
Stable diffusion中这些重要的参数你一定要会用
Stable diffusion中这些重要的参数你一定要会用
如果你已经使用Stable diffusion AI模型生成了一些图像,但发现它们并不完全符合你的期望,不用担心,你可以通过调整一些基本的生成参数来进行自定义,以达到更加满意的效果。
使用Stable diffusion软件
Stable diffusion(AI)是一种强大的技术,它可以生成高质量的图像。虽然一些基本的参数可以在免费的在线AI生成器中调整,但为了获得更全面和精细的控制,我们通常会转向更专业的工具,如Stable diffusion web UI AUTOMATIC1111。这个平台提供了更多的选项和功能,使得用户能够更深入地探索和利用稳定扩散AI的潜力。
云端环境推荐【仙宫云】点我直达仙宫云这个平台非常强大,性价比也很高。它支持GeForce GTX 4090,3090,3080ti等多种主流高性能计算GPU。并且平台提供了Stable Diffusion WebUI,ComfyUI,Fooocus等多款AI应用。注册就送免费算力。
在Stable diffusion web UI中,我们先生成一个初始的图像,然后再一步步的引导大家学习了解一些重要参数的用法。
这是我们的初始参数:
Checkpoint: realisian_v60
prompt: digital painting of a magical cat goddess,ambiguous,energetic,pyroclasmic,fierce,abyssal,occult,multiple exposure photography,weird,deferred rendering,
Negative prompt: (naked, nude, nudity, nsfw, nipples),sexy,
Steps: 20,Sampler: DPM++ 2M Karras,
CFG scale: 7,
Seed: 712020765,
Size: 512x768,
Clip skip: 2
我们可以得到下面这样一张图片:

我们生成了一张带有魔力的猫的图片。
下面我们来调整一些非常重要的参数,来看看具体的效果。
使用x/y/z plot
为了进行参数对比,我们可以修改好参数,然后点击生成,生成一张照片,最后把生成的照片再合并起来进行比较。
这种做法比较麻烦,不符合我们现代人追求效率的做法。
为了更好的进行对比,这里我们需要用到一个叫x/y/z plot的脚本。
点击web UI下方的script,你会发现一个x/y/z plot的选项。选中他:
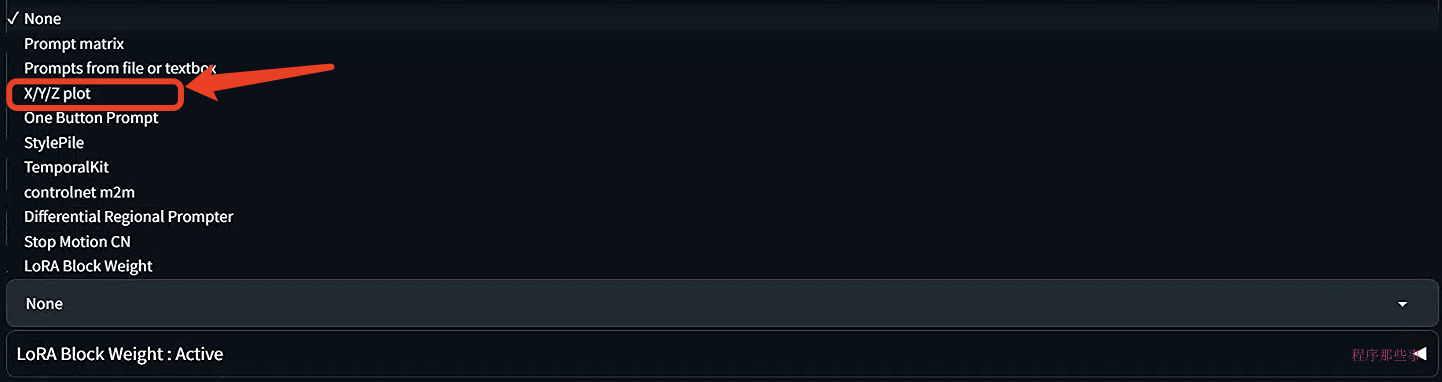
你会得到下面的界面:
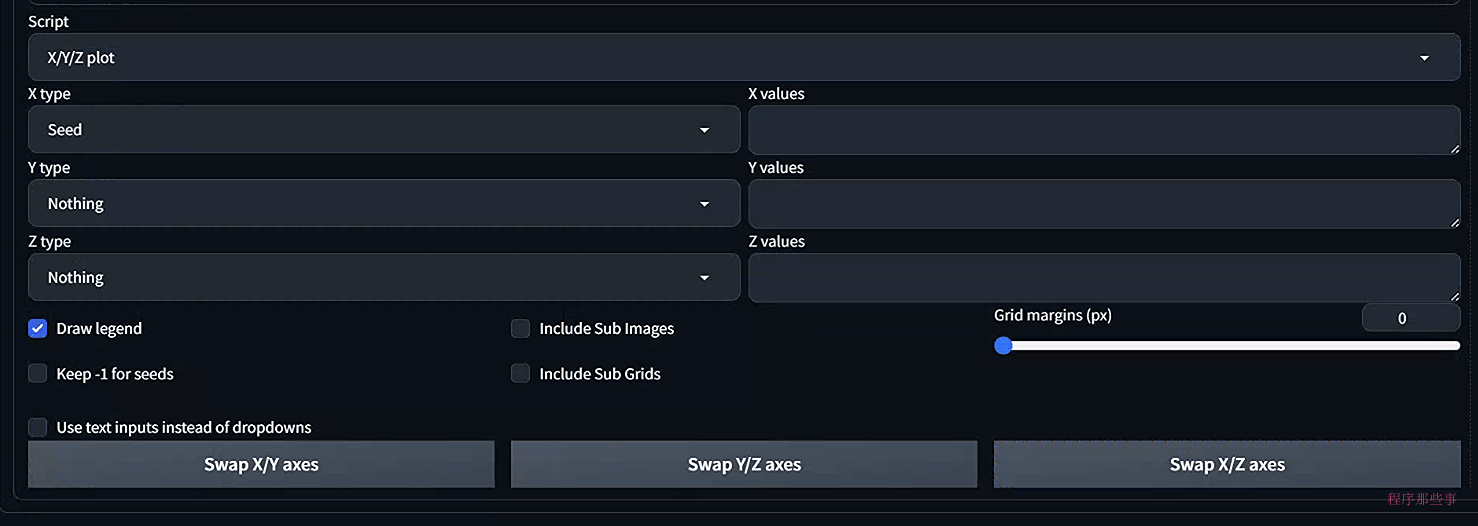
这个脚本很简单,学过微积分的都能理解。
基本上x,y,z就是三个不同的变量,你可以为不同的变量设置不同的值。最后会生成一个grid的合并图片,非常方便我们进行图片效果的对比。
接下来我们会使用这个脚本来进行不同参数的对比。
CFG scalar
CFG scalar是一个参数,用于控制模型应在多大程度上遵守你的提示。
1 – 大多数情况下忽略您的提示。
3 – 更有创意。
7 – 在遵循提示和自由之间取得良好的平衡。
15 – 更多提示。
30 – 严格按照提示操作。
因为我们这里只有一个变量,所以X type选择CFG Scale. value字段设置为:1,3,7,15,30:
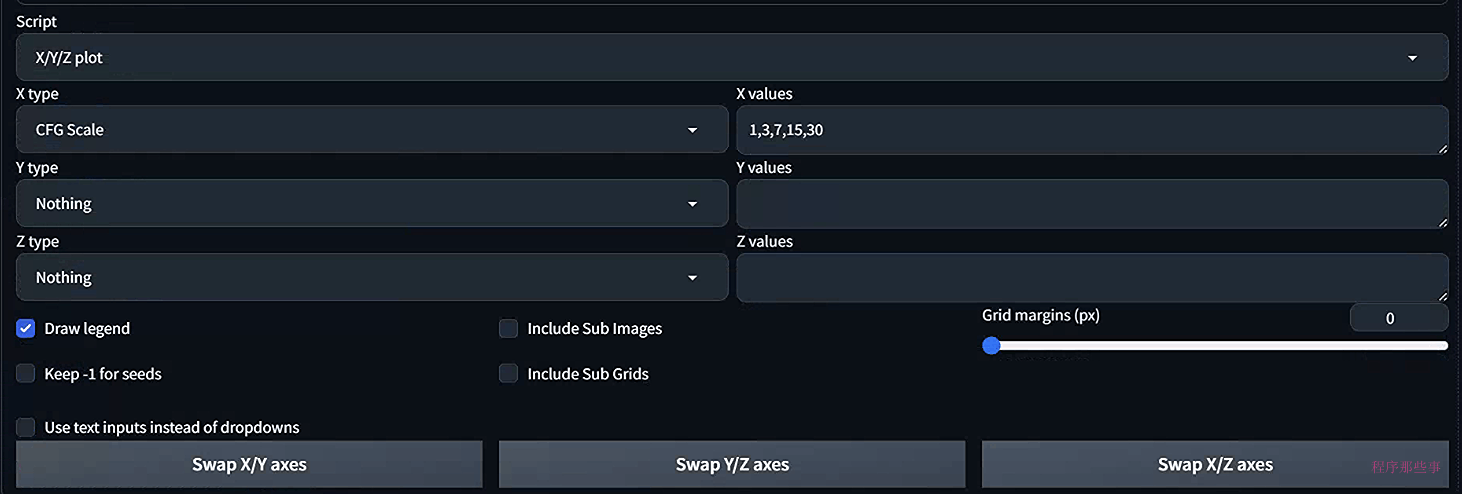
运行之后,我们可以得到相应图片的对比情况:

可以看到,1和30基本上太过极端了。
通常情况下,我们可以从7开始。如果你想图片更多接近你的提示词,那么可以适当的进行增加。
Sampler Steps
增加采样步骤可以提高质量。通常情况下,使用采样器进行 20 步就可以得到高质量、清晰的图像。如果增加更多的步数,那么图像会出现微妙的变化,但不一定会具有更高的质量。
同样我们更改Sampler Steps,选择1,5,10,20,30和50:
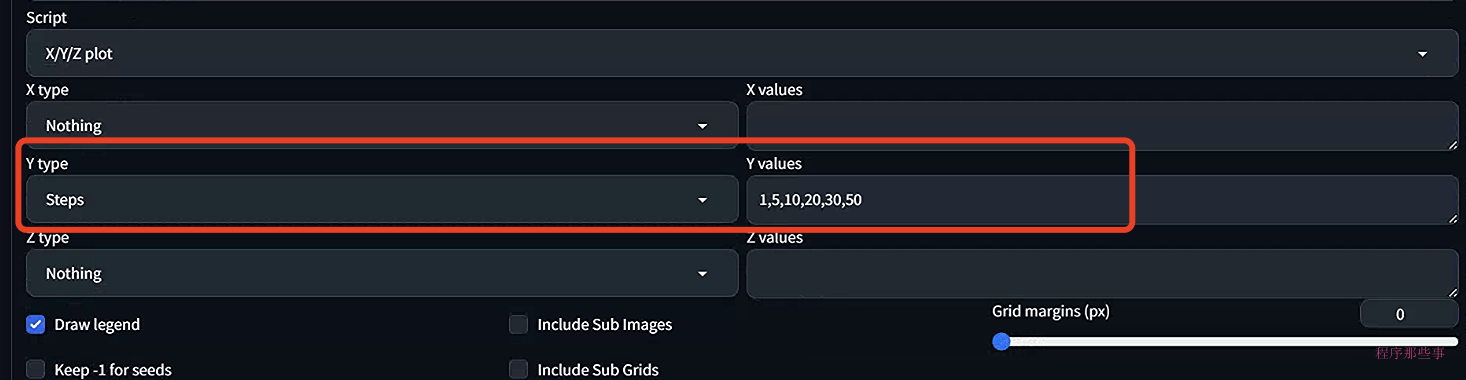
最后生成的结果如下:

一般情况下20步已经够了,你可以根据需要看看是否需要增加步数。
Sampler方法
Stable diffusion支持多种采样方法。这些方法仅代表了不同的扩散方程求解方法。它们应该产生相似的结果,但由于数字偏差可能略有不同。然而,由于没有绝对正确的答案——唯一的标准是图像看起来不错,因此您不必过于担心方法的准确性。
下面是这些采样器的简单介绍:
Euler a :有很高的多样性,tag利用率仅次与DPM2和DPM2 a。但是构图有时很奇葩,而且步数大于30,效果减弱
Euler:柔和,也适合插画,环境细节与渲染好,背景模糊较深。同时是最简单、最快的
LMS 是 Euler 的衍生,它们使用一种相关但稍有不同的方法(平均过去的几个步骤以提高准确性)。大概30step可以得到稳定结果,更倾向于动画的风格
Heun:单次出图平均质量比Euler和Euler a高,但速度最慢,高step表现好。
DPM2:该采样方法对tag的利用率最高,几乎占80%+
DPM2 a:几乎与DPM2相同,是对于DDIM的改进,减少步骤以获得良好的结果,它的速度大约是DDIM的两倍,生图效果也非常好
DPM fast:此为上界开发者所遗留的测试工具,不适合魔术师使用
LMS Karras:会大改成油画的风格,写实不佳。
DDIM:适合宽画,速度偏低,高step表现好,负面tag不够时发挥随意,环境光线与水汽效果好,写实不佳。
UniPC 效果较好且速度非常快,对平面、卡通的表现较好,推荐使用。
DDIM 收敛快,但效率相对较低,因为需要很多 step 才能获得好的结果,适合在重绘时候使用。
PLMS 是 Euler 的衍生,可以更好地处理神经网络结构中的奇异性。
不同的方法处理时间并不相同,以下是各种方法的处理时间。
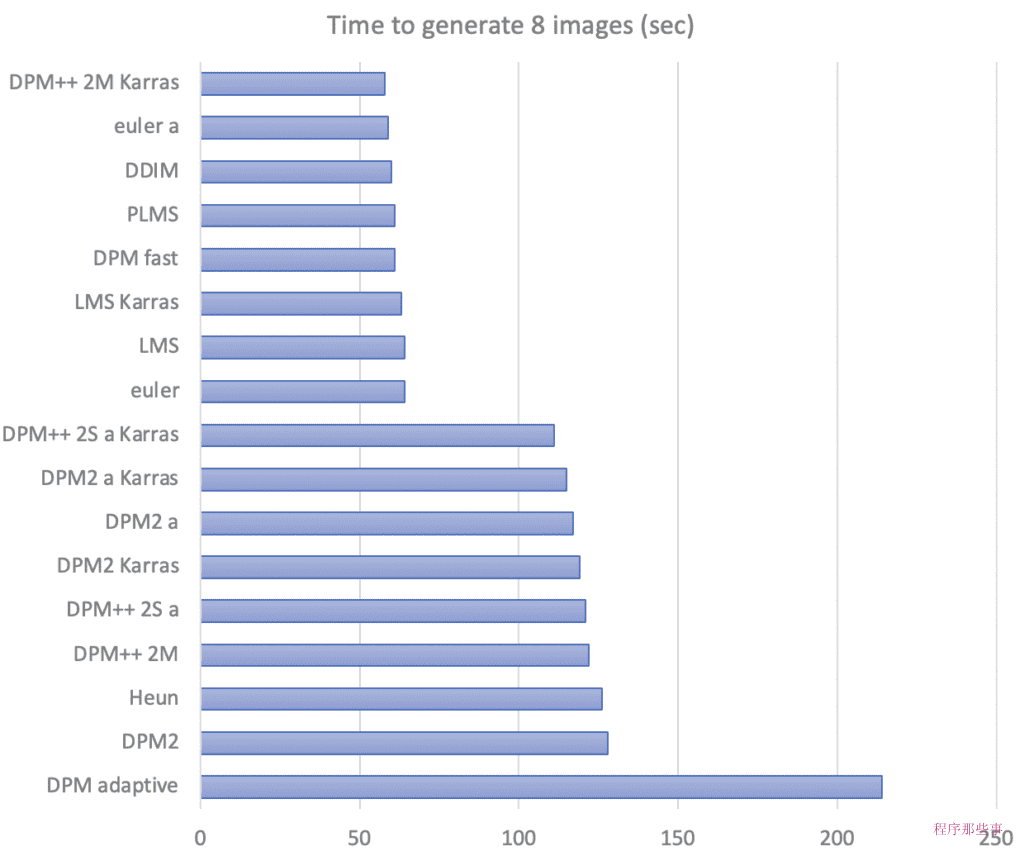
以下是使用不同采样方法经过 20 个步骤后生成的图像。其中许多是相似的,但也可能有一些完全不同的。
同样的我们使用X/Y/Z plot来进行对比:

推荐:DPM++ 2M Karras
seed
Seed决定了初始噪声模式,从而决定了最终图像。
将其设置为 -1 意味着每次都使用随机的种子。这在您想要生成新图像时非常有用。
如果你设置seed为同一值,那么会导致每一代图像都相同。
我们可以在这里设置seed值:
Size
size决定了输出图像的大小。由于 Stable Diffusion v1 是使用 512×512 张图像进行训练的,因此偏离太多可能会导致复制对象等问题。
所以我们尽可能保持输出的size是正方形。512×768(纵向)或768×512(横向)也可以。
建议:将图像大小设置为512×512。否则,请拨打 512×768 或 768×512。
当然这只适合V1模型,SDXL已经扩展到了1024x1024。
batch size
batch size是每次生成的图像数量。由于最终图像非常依赖于随机种子,因此一次生成几张图像始终是一个好主意。这样,您可以更好地了解当前提示可以做什么。
建议:将批处理大小设置为 4 或 8。
总结
在本文中,我们介绍了 Stable Diffusion AI 的基本参数。大家可以尝试一下去调整对应的参数,看看能不能得到不同的结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号