
python调用java的jar包,在scrapy中处理加密逻辑
APP采集过程中有些请求是需要加密处理的,之前的方式是通过frida-inject的方式处理的,但是这需要连接手机,
好在本次处理的APP加密逻辑不是很复杂,加密逻辑都在java层,于是便将里面的java层的加密逻辑单独摘出来,想单独的做成一个jar包,这样就不用再用python做一个相同的算法还原了
经过半天的调试,终于将java层用到的加密逻辑代码都摘了出来。
以前没有做过java开发,基础的导出jar包都不知道怎么搞,经过这次经历也算补齐了一个短板,特此记录下
在eclipse里创建一个项目

在src文件夹上右键,选择创建包Package,取个名字就好

将用到的java代码,以及依赖的java类都放在里面,这个是相对依赖比较少的情况,对于依赖第三方的类库的还没处理过

对于本次的APP加密用到的就这几个类文件,在包名上右键,选择Export
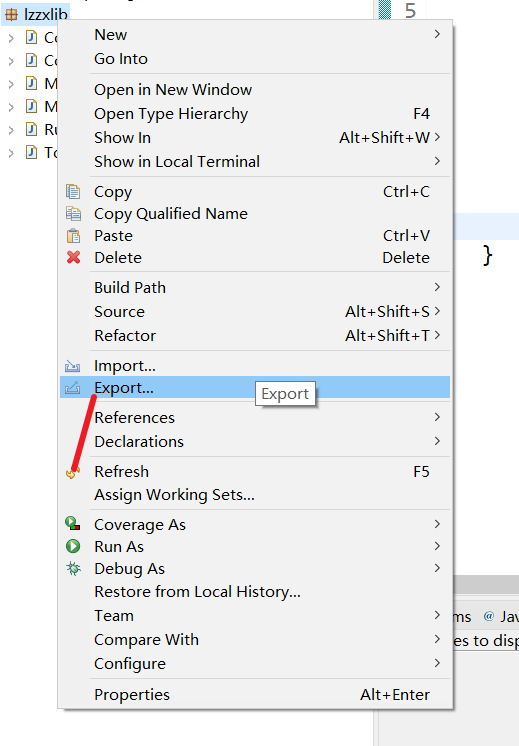
如下图所示,选择Java下的JAR file

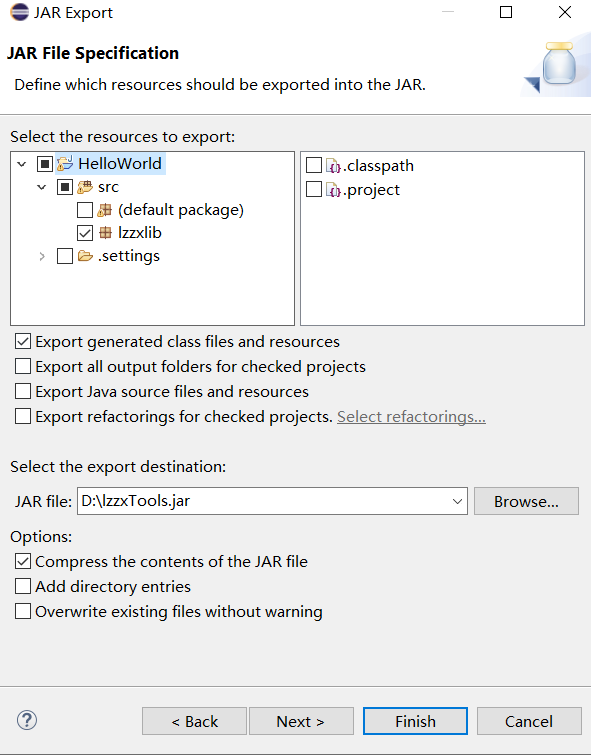
选择好保存目录就可以了,这样就生成了jar包文件了
python调用jar包有多种方式,一个是用Jython,需要单独安装一个java版的python,有点麻烦
另一种就是通过jpype的方式,直接在python代码里调用jar包文件
详细的方式可以参考 其他博主的文章 (https://blog.51cto.com/u_16099268/6527910)文章写的很详细
需要注意的是编译成jar文件的时候需要最好用系统环境变量里的java sdk,不然在jpype调用jar包的时候很容易因为java sdk版本的问题导致异常,
因为我的机器上有多个java sdk版本,jpype默认调用的是系统环境变量里的java
import reimport traceback import time import json import os import scrapy import requests from urllib import parse from scrapy import FormRequest from datetime import datetime, timedelta from scrapy import signals from urllib.parse import urljoin, urlparse, parse_qs,urlencode from scrapy.pipelines.files import FilesPipeline from hashlib import md5 import jpype class LzzxSpider(scrapy.Spider): name = 'lzzx' # python要调用的java的jar包路径 jarpath = os.path.join(os.path.abspath("."), "lzzxTools.jar") # 获取jvm.dll的文件路径 jvmPath = jpype.getDefaultJVMPath() # 使用jpype开启虚拟机 if jpype.isJVMStarted() is not True: jpype.startJVM(jvmPath, "-ea", "-Djava.class.path=%s" % jarpath) # 加载java类 tools = jpype.JClass("lzzxlib.Tools")
# 爬虫结束时执行的函数
def closed(self, reason):
# 关闭jvm
jpype.shutdownJVM()
# jpype调用jar包
def sign_stamp(self,price_type):
print(price_type)
time_stamp = int(round(time.time() * 1000))
tree_url = "xxx"
base_url = "xxx"
price_detail_url = "xxx"
display_url = "xxx"
price_type_url = "***"
if price_type == "dp":
result = str(self.tools.a(time_stamp,display_url))
return {"time_stamp": time_stamp, "result": result}
elif price_type == "btb":
result = str(self.tools.a(time_stamp,price_type_url))
return {"time_stamp": time_stamp, "result": result}
elif price_type == "tree":
result = str(self.tools.a(time_stamp,tree_url))
return {"time_stamp": time_stamp, "result": result}
elif price_type == "price_detail":
result = str(self.tools.a(time_stamp,price_detail_url))
return {"time_stamp": time_stamp, "result": result}
else:
result = str(self.tools.a(time_stamp,base_url))
return {"time_stamp": time_stamp, "result": result}
这样就完成了在scrapy中调用jar包的整个过程,特此记录下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号