

ES minimum_should_match
最近在处理关键词匹配文章的项目,比如给定“Ukip Vimpat applies” 查询指定的title中含有至少2个词的内容
# 查看分词情况
POST _analyze
{
"analyzer": "standard",
"text": [
"Ukip Vimpat applies"
]
}
如下是分词的结果
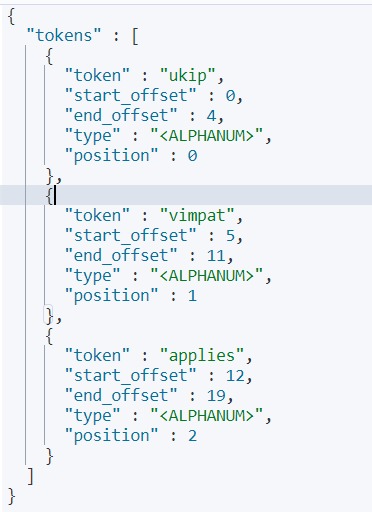
在10w级数量上查询包含至少2个词的文章,利用ES的minimum_should_match 可以很容易解决这类问题,
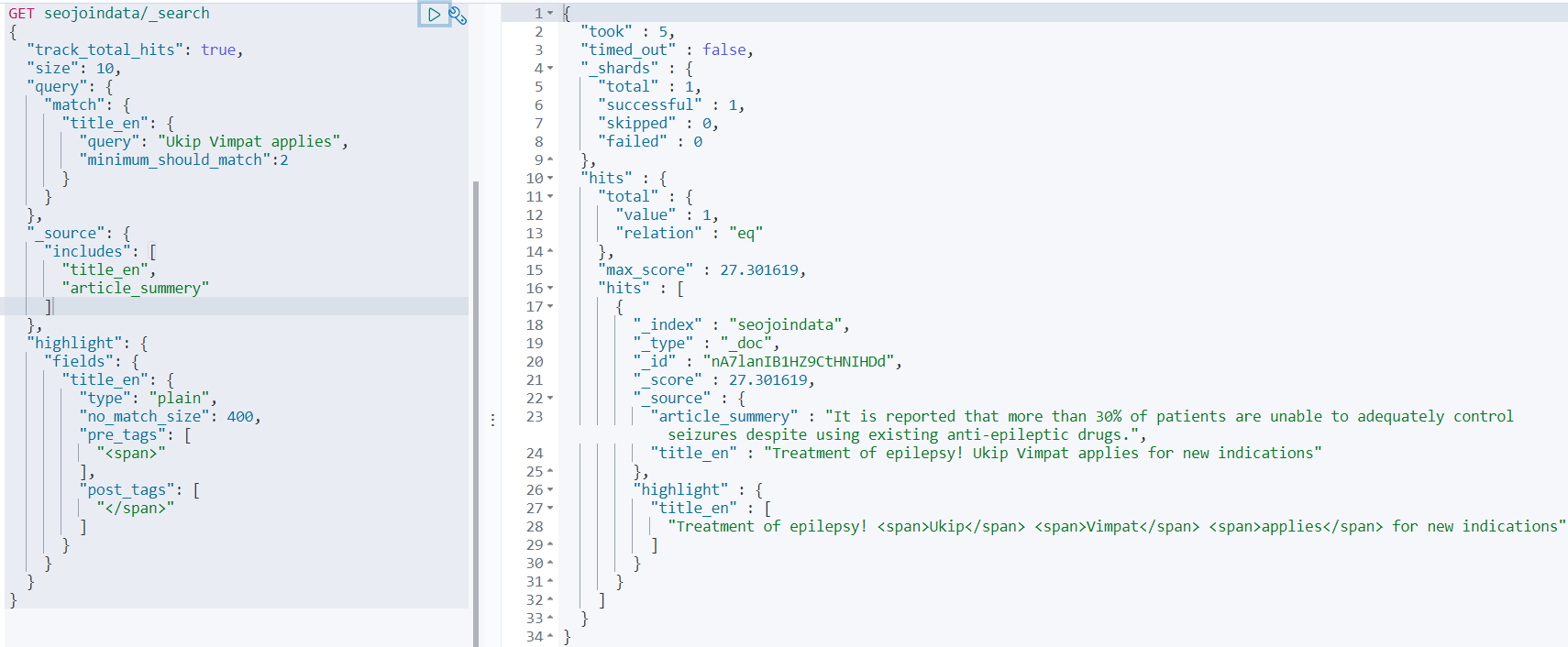
minimum_should_match 中即可以是整数,即包含的单词个数,
如minimum_should_match :2 表示“Ukip Vimpat applies”这个词至少包含2个单词
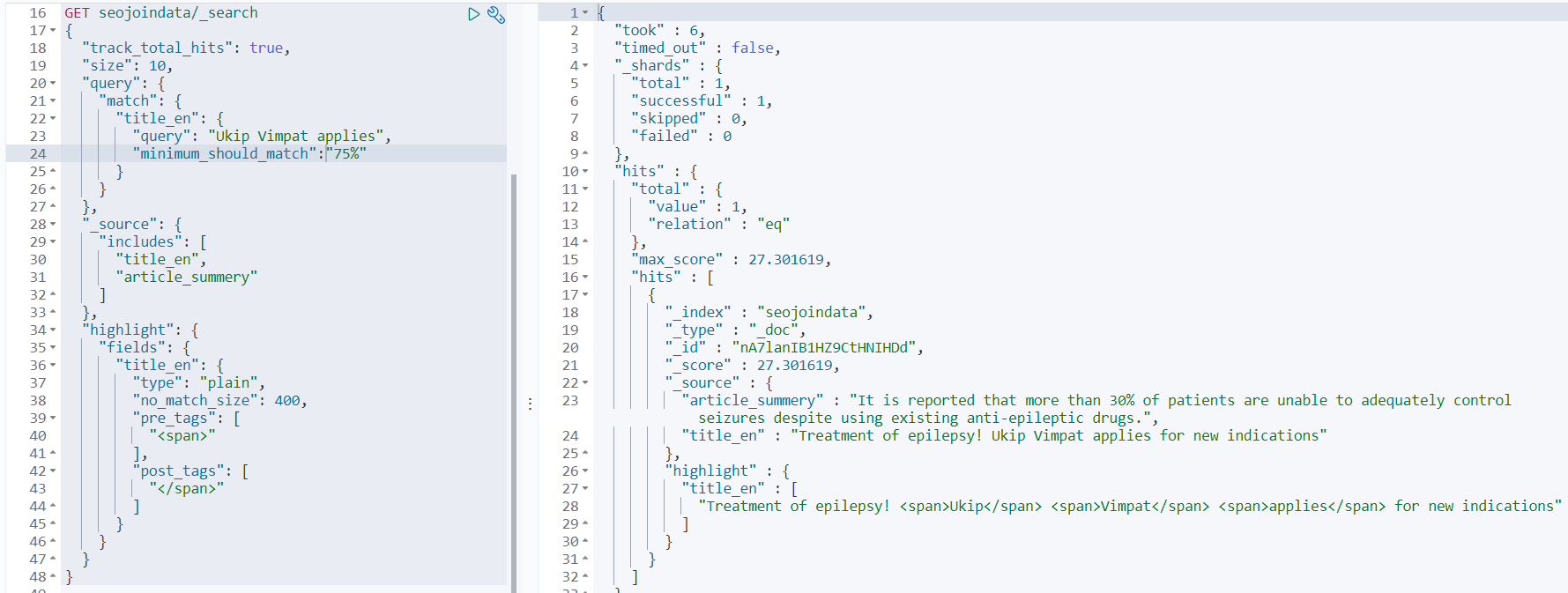
minimum_should_match 如果为百分比,即分词后的个数*百分比,
如minimum_should_match : "75%" 表示“Ukip Vimpat applies”分词后的个数为3,最后为3*0.75
如果为百分数,小数是向下去整,所以最好的还是通过计算分词的数量,给一个整数
GET seojoindata/_search
{
"track_total_hits": true,
"size": 10,
"query": {
"match": {
"title_en": {
"query": "Ukip Vimpat applies",
"minimum_should_match":"75%"
}
}
},
"_source": {
"includes": [
"title_en",
"article_summery"
]
},
"highlight": {
"fields": {
"title_en": {
"type": "plain",
"no_match_size": 400,
"pre_tags": [
"<span>"
],
"post_tags": [
"</span>"
]
}
}
}
}
关于分词的情况参考 https://www.cnblogs.com/feng07/p/11571152.html
