爬虫如何发现更多的url呢,怎么动态收集新的url连接
大家在做爬虫采集数据的时候很多都会遇到增量采集的问题,有些时候是通过过滤url来进行的,有些是通过爬取网页后再进行分析判断,
以上这些过程也许大部分做爬虫的都会这么做,各位有没有想过,
除了以上的常用的方式还有没有其他的能够可以一次性批量获取先要的url连接地址呢?
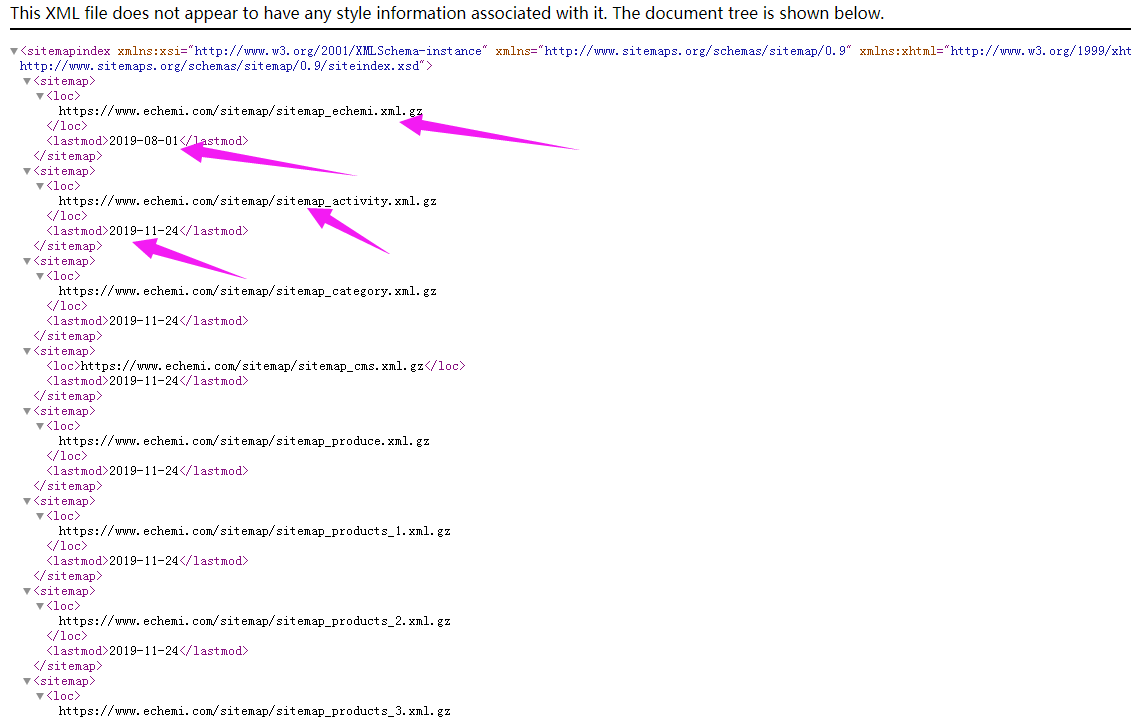
自己做爬虫也有很多年了,前不久听了一次SEO优化的课,在SEO优化中有一条是关于sitemap的,很多网站为了方便各个搜索引擎收录最新的内容,基本会每天都会自动生成一个sitemap文件,
是的,就是这个sitemap文件为我们提供了最新的可以采集内容的连接地址,以前没怎么在意这些,突然发现这个sitemap不就是可以很轻松为我们提供批量的采集url的好来源吗?
真是踏破铁鞋无觅处,得来全不费工夫啊,不过也不能高兴太早,不是每个网站都会有sitemap,这里也只是给大家提供了一条思路,在采集的路上可以获得更多的来源途径 这样既可以为对方网站减轻不必要的访问压力,也为自己节省了时间精力,
一举两得,何乐而不为呢。
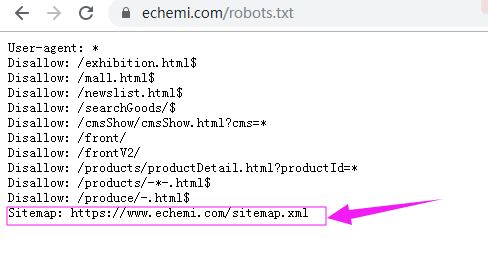
一般都会在网站根目录下的robots.txt中提供sitemap的路径,或者直接访问域名下的sitemap.xml文件也可以获取,这个一般是按照天,每天生成一个xml.gz的文件,解压后里面就是我们需要的url地址了