会员
周边
新闻
博问
闪存
赞助商
Chat2DB
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
fly_bk
博客园
首页
新随笔
联系
订阅
管理
上一页
1
···
4
5
6
7
8
9
10
11
12
···
43
下一页
2021年1月19日
html 灯笼
摘要: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <div class="deng-box denglong"> <div class="deng">
阅读全文
posted @ 2021-01-19 08:32 fly_bk
阅读(229)
评论(0)
推荐(0)
2020年12月31日
朴素贝叶斯
摘要: 从词向量计算概率 import numpy as np def loadDataSet(): """ 实验样本 :return: 第一个变量是进行词条切分后的文档集合,第二个变量是一个类别标签的集合 """ postingList = [['my', 'dog', 'has', 'flea', 'p
阅读全文
posted @ 2020-12-31 11:26 fly_bk
阅读(101)
评论(0)
推荐(0)
2020年12月30日
决策树基于ID3算法
摘要: from math import log import operator """ 使用ID3算法划分数据集,ID3算法可以用于划分标称型数据集 决策树分类器就像带有终止块的流程图,终止块表示分类结果。 开始处理数据集时,首先需要测量集合中数据的不一致, 然后寻找最优方案划分数据集,直到数据集中的所有
阅读全文
posted @ 2020-12-30 12:16 fly_bk
阅读(212)
评论(0)
推荐(0)
mac matplotlib设置中文
摘要: plt.rcParams['font.family'] = 'Arial Unicode MS'
阅读全文
posted @ 2020-12-30 11:01 fly_bk
阅读(112)
评论(0)
推荐(0)
2020年12月26日
MySQL数据库中实现对中文字段按照首字字母排序
摘要: 在MySQL中,我们经常会对一个字段进行排序查询,但进行中文排序和查找的时候,对汉字的排序和查找结果往往都是错误的。 这种情况在MySQL的很多版本中都存在。 如果这个问题不解决,那么MySQL将无法实际处理中文。 出现这个问题的原因是因为MySQL在查询字符串时是大小写不敏感的,在编绎MySQL时
阅读全文
posted @ 2020-12-26 11:27 fly_bk
阅读(400)
评论(0)
推荐(0)
2020年12月24日
01 K近邻算法
摘要: K近邻算法采用测量不同特征值之间的距离方法进行分类 优点:精读高,对异常值不敏感,无数据输入假定 缺点:计算算杂度高,空间复杂度高。适合数据范围:数值型和标称型 K近邻算法是分类数据最简单最有效的算法。是基于实例的学习,使用算法时我们必须有接近实际数据的训练 样本数据。K近邻算法必须保存全部数据集,
阅读全文
posted @ 2020-12-24 12:45 fly_bk
阅读(226)
评论(0)
推荐(0)
2020年12月22日
01 pandas对象
摘要: 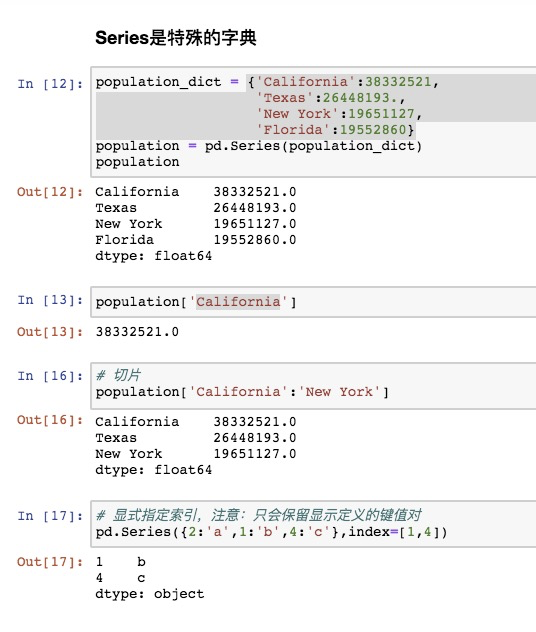
评论(0)
推荐(0)
10 numpy 花哨的索引
摘要:
阅读全文
posted @ 2020-12-22 11:14 fly_bk
阅读(99)
评论(0)
推荐(0)
09 numpy布尔
摘要:  
阅读全文
posted @ 2020-12-22 10:28 fly_bk
阅读(54)
评论(0)
推荐(0)
2020年12月19日
08 广播
摘要: http://www.astroml.org/book_figures/appendix/fig_broadcast_visual.html 规则 例子
阅读全文
posted @ 2020-12-19 16:01 fly_bk
阅读(76)
评论(0)
推荐(0)
上一页
1
···
4
5
6
7
8
9
10
11
12
···
43
下一页
公告
 浙公网安备 33010602011771号
浙公网安备 33010602011771号