数据仓库系列之ETL中常见的增量抽取方式
为了实现数据仓库中的更加高效的数据处理,今天和小黎子一起来探讨ETL系统中的增量抽取方式。增量抽取是数据仓库ETL(数据的抽取(extraction)、转换(transformation)和装载(loading))实施过程中需要重点考虑的问题。ETL抽取数据的过程中,增量抽取的效率和可行性是决定ETL实施成败的关键问题之一,做过数据建模的小伙伴都知道ETL中的增量更新机制比较复杂,采用何种机制往往取决于源数据系统的类型以及对增量更新性能的要求。今天我们只重点对各种方法进行对比分析,从而总结各种机制的使用条件和优劣性,为数据仓库项目的ETL工程的实施提供增量抽取技术方案参考。
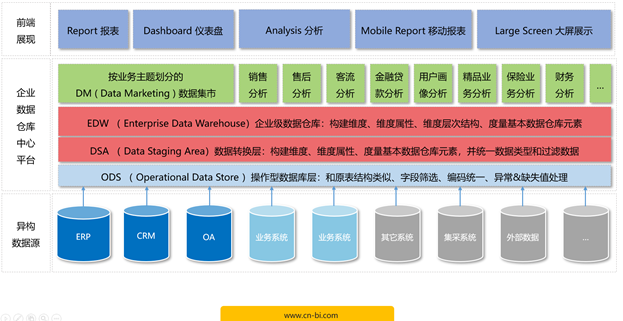
在数据库仓库开发过程中,无论是全量抽取方案还是增量抽取方案,抽取数据的工作一般由数据仓库工具来完成。目前数据仓库开发工具非常多,比如SE-DWA,DTS,Kettle等等。虽然增量抽取方案设置比较简单,但是我们还是需要具体来了解一下增量抽取机制以便后续更合理的利用增量抽取方案。下面讨论各种增量抽取的实现机制原理。
一、增量抽取的机制
实现增量抽取关键准确快速的捕获变化的数据。优秀的增量抽取机制要求ETL能够将业务系统中的变化数据按一定的频率准确地捕获,同时不能对业务系统造成太大的压力,影响现有业务。相对全量抽取而言,增量抽取的设计更复杂,有一种将全量抽取过程自动转换为增量抽取过程的ETL设计思路,前提是必须捕获变化的数据,增量数据抽取中常用的捕获变化数据的方法小黎子了解到的有以下四种方式:
1 、基于建触发器方式生成增量数据
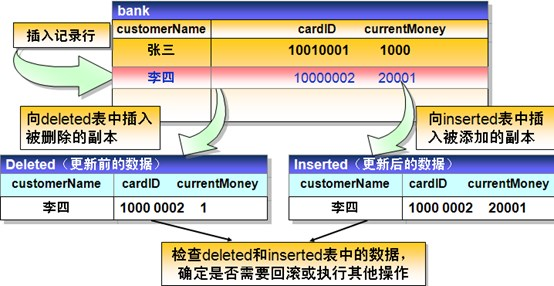
使用触发器生成增量数据是普遍采取的一种增量抽取机制。该方式是根据抽取要求,在要被抽取的源表上建立3个触发器插入、修改、删除,每当源表中的数据发生变化,就被相应的触发器将变化的数据写入一个增量日志表,ETL的增量抽取则是从增量日志表中而不是直接在源表中抽取数据,同时增量日志表中抽取过的数据要及时被标记或删除。
为了简单演示,增量日志表一般不存储增量数据的所有字段信息,而只是存储源表名称、更新的关键字值和更新操作类型(knsen、update或delete),ETL增量抽取进程首先根据源表名称和更新的关键字值,从源表中提取对应的完整记录,再根据更新操作类型,对目标表进行相应的处理。
优点:数据库本身的触发器机制,契合度高,可靠性高,不会存在有增量数据未被捕获到的现象
缺点:对于源系统有较大的影响,需要建立触发器机制,增加运维人员,还要建立临时表,储存临时表,增加储存成本和运维成本
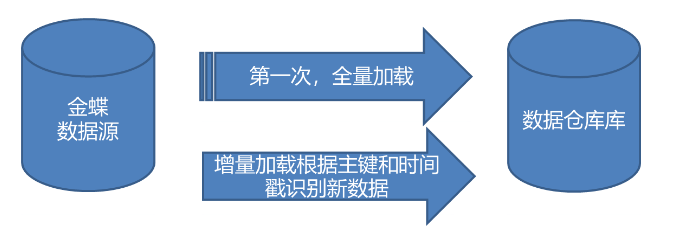
2 、基于时间戳方式生成增量数据

时间戳方式是指增量抽取时,抽取进程通过比较系统时间与抽取源表的时间戳字段的值来决定抽取哪些数据。这种方式需要在源表上增加一个时间戳字段,系统中更新修改表数据的时候,同时修改时间戳字段的值。
有的数据库(例如Sql Server)的时间戳支持自动更新,即表的其它字段的数据发生改变时,时间戳字段的值会被自动更新为记录改变的时刻。在这种情况下,进行ETL实施时就只需要在源表加上时间戳字段就可以了。对于不支持时间戳自动更新的数据库,这就要求业务系统在更新业务数据时,通过编程的方式手工更新时间戳字段。使用时间戳方式可以正常捕获源表的插入和更新操作,但对于删除操作则无能为力,需要结合其它机制才能完成。
优点:数据处理逻辑清楚,速度较快,成本低廉,流程简单
缺点:要求源表的时间字段必须是随表变动而变动的不为空数据,由于是直接读取表数据,该方法无法获取删除类型的数据。
3、 基于全表比对方式生成增量数据

全表比对即在增量抽取时,ETL进程逐条比较源表和目标表的记录,将新增和修改的记录读取出来。
优化之后的全部比对方式是采用MD5校验码,需要事先为要抽取的表建立一个结构类似的MD5临时表,该临时表记录源表的主键值以及根据源表所有字段的数据计算出来的MD5校验码,每次进行数据抽取时,对源表和MD5临时表进行MD5校验码的比对,如有不同,进行update操作:如目标表没有存在该主键值,表示该记录还没有,则进行insert操作。然后,还需要对在源表中已不存在而目标表仍保留的主键值,执行delete操作。
优点:因为是基于目标对比抽取数据,所以对源系统无影响
缺点:该方法仅仅适合表有主键,唯一键或者数据量较小的表,不然海量数据中每条数据的每一列都进行逐一比对,很显然这种频繁的I/O操作以及复杂的比对运算会造成很大的性能开销。这样操作需要足够的硬件做支撑
4 、基于日志表方式生成增量数据
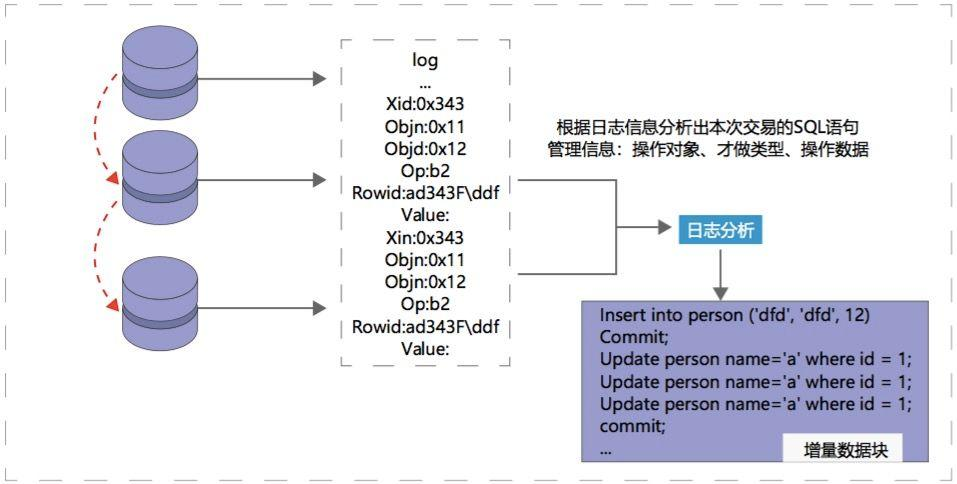
对于建立了业务系统的生产数据库,可以在数据库中创建业务日志表,当特定需要监控的业务数据发生变化时,由相应的业务系统程序模块来更新维护日志表内容。增量抽取时,通过读日志表数据决定加载哪些数据及如何加载。日志表的维护需要由业务系统程序用代码来完成。
优点:可以做到数据无误差传输,有回滚机制,有容灾备份的能力
缺点:数据库开归档模式会对源系统数据库的磁盘造成压力,增加储存成本,此外大多数数据库的日志都是不对外开放的,只针对数据库本身的工具开放读取
二、比较和分析
可见,ETL在进行增量抽取操作时,有以上各种机制可以选择。现从兼容性、完备性、性能和侵入性3个方面对这些机制的优劣进行比较分析。各种数据增量抽取机制的优劣性综合分析如下图所示。

通过对各种增量抽取机制的对比分析,我们发现,没有一种机制具有绝对的优势,不同机制在各种因素的表现大体上都是相对平衡的。所以,ETL实施过程中究竞选择哪种增量抽取机制,要根据实际的数据源系统环境进行决策,需要综合考虑源系统数据库的类型、抽取的数据量(决定对性能要求的苛刻程度)、对源业务系统和数据库的控制能力以及实现难度等各种因素,甚至结合各种不同的增量机制以针对环境不同的数据源系统进行ETL实施。
三、总结

为了实现数据仓库中数据的高效抽取,增量抽取是ETL数据抽取过程中非常重要的一步,实现增量抽取的机制直接决定了数据仓库项目整体开发的效果。我们通过对比几种常见的增量抽取机制并总结了各种机制的特性并分析了它们的优劣。各种增量抽取机制都有它有存在的价值和固有的限制条件,所以在ETL的设计和实施工作过程中,只能依据项目的实际环境进行综合考虑,甚至需要对可采用的多种机制进行实际的测试,才能确定一个最优的增量抽取方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号