

Tutorial_6 运行结果
1.buyer_favorites.txt
2.代码
package mapreduce; import java.io.IOException; import java.util.Iterator; import java.util.StringTokenizer; import java.io.IOException; import java.util.Iterator; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public WordCount() { } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); // String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); String input = "hdfs://192.168.1.102:9000/user/hadoop/input/buyer_favorite1.txt"; String output = "hdfs://192.168.1.102:9000/user/hadoop/output"; String[] otherArgs = new String[] { input, output }; /* 直接设置输入参数 */ if (otherArgs.length < 2) { System.err.println("Usage: wordcount <in> [<in>...] <out>"); System.exit(2); } Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(WordCount.TokenizerMapper.class); job.setCombinerClass(WordCount.IntSumReducer.class); job.setReducerClass(WordCount.IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); for (int i = 0; i < otherArgs.length - 1; ++i) { FileInputFormat.addInputPath(job, new Path(otherArgs[i])); } FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public IntSumReducer() { } public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int sum = 0; IntWritable val; for (Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) { val = (IntWritable) i$.next(); } this.result.set(sum); context.write(key, this.result); } } public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private static final IntWritable one = new IntWritable(1); private Text word = new Text(); public TokenizerMapper() { } public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString(), "\t"); while (itr.hasMoreTokens()) { this.word.set(itr.nextToken().split(" ")[0]); context.write(this.word, one); } } } }
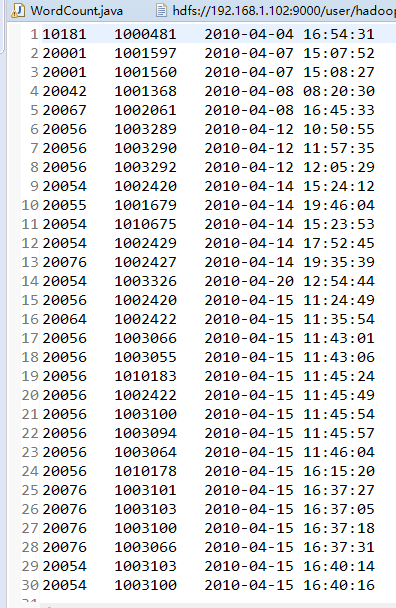
3.运行结果

4.遇到的问题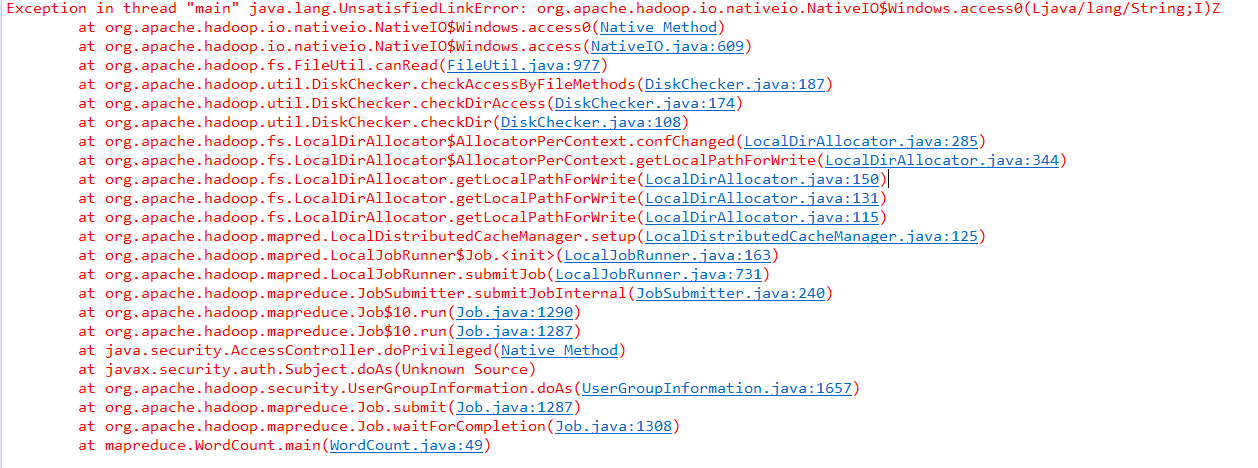
解决办法:
分析:
C:\Windows\System32下缺少hadoop.dll,把这个文件拷贝到C:\Windows\System32下面即可。
解决:
hadoop-common-2.2.0-bin-master下的bin的hadoop.dll放到C:\Windows\System32下,然后重启电脑,也许还没那么简单,还是出现这样的问题。(原博主是这么写的,实际上只是将hadoop.dll粘到了 C:\Windows\System32目录下就行了)
————————————————
声明:仅解决办法参考CSDN博客,文末附原文链接。
原文链接:https://blog.csdn.net/congcong68/article/details/42043093

