

用Nokogiri操作xml文件
目前在Ruby社区,最流行的操作xml的方法是使用nokogiri这个gem。Nokogiri较之于以前的REXML有性能上的优势,因此逐渐取代REXML成为Ruby程序员最通用的xml工具。Nokogiri及其它模块的内存使用情况对比如下图:
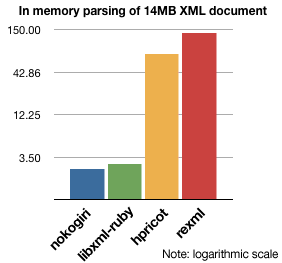
此图的来源,以及详细的说明参见这里。
要点:
- Nokogiri里的几个重要的类:Node/Document/Element/NodeSet/Cdata/Text。
其相互继承关系如下图所示:![]()
可以说,一个XML文件的内容就由是多个Node对象构成的树型结构表示的。XML中的一切内容,都是Node对象或者Node对象的属性(Attributes)。
而Node的几个子类则对Node类进行了细分,它们之间有一些差别:- Document: 当将一个完整的xml格式的String或XML文件读入,则其返回对象为Document类;
- Element: 正常通过开关标签包含有内容的Node为Element类;
- Text: 一个Element对象内部包含的纯文字为Text类;
- CDATA: 一个Element对象内容包含的CDATA数据为CDATA;
而值得强调的是,以上四个类的对象也都是Node对象,因此也继承了Node的方法和属性。 - NodeSet: 可以认为,NodeSet是由Node对象组成的Array,因此可以对NodeSet对象使用很多Array的方法。
- 读入文件
我们用以下的XML文件为例:
![]() View Code
View Code1 <Collection version="2.0" id="74j5hc4je3b9"> 2 <Name>A Funfair in Bangkok</Name> 3 <PermaLink>Funfair in Bangkok</PermaLink> 4 <PermaLinkIsName>True</PermaLinkIsName> 5 <Description>A small funfair near On Nut in Bangkok.</Description> 6 <Date>2009-08-03T00:00:00</Date> 7 <IsHidden>False</IsHidden> 8 <Items> 9 <Item filename="AGC_1998.jpg"> 10 <Title>Funfair in Bangkok</Title> 11 <Caption><![CDATA[A small funfair near On Nut in Bangkok.]]></Caption> 12 <Authors>Anthony Bouch</Authors> 13 <Copyright>Copyright Anthony Bouch</Copyright> 14 <CreatedDate>2009-08-07T19:22:08</CreatedDate> 15 <Keywords> 16 <Keyword>Funfair</Keyword> 17 <Keyword>Bangkok</Keyword> 18 <Keyword>Thailand</Keyword> 19 </Keywords> 20 <ThumbnailSize width="133" height="200" /> 21 <PreviewSize width="532" height="800" /> 22 <OriginalSize width="2279" height="3425" /> 23 </Item> 24 <Item filename="AGC_1164.jpg" iscover="True"> 25 <Title><![CDATA[Bumper Cars at a Funfair in Bangkok]]></Title> 26 <Caption>Bumper cars at a small funfair near On Nut in Bangkok.</Caption> 27 <Authors>Anthony Bouch</Authors> 28 <Copyright>Copyright © Anthony Bouch</Copyright> 29 <CreatedDate>2009-08-03T22:08:24</CreatedDate> 30 <Keywords> 31 <Keyword>Bumper Cars</Keyword> 32 <Keyword>Funfair</Keyword> 33 <Keyword>Bangkok</Keyword> 34 <Keyword>Thailand</Keyword> 35 </Keywords> 36 <ThumbnailSize width="200" height="133" /> 37 <PreviewSize width="800" height="532" /> 38 <OriginalSize width="3725" height="2479" /> 39 </Item> 40 </Items> 41 </Collection>
该文件的文件名为test.xml。
Nokogiri::XML::Document.parse() -
>> f = File.open("/path/to/the/test.xml") => #<File:/path/to/the/collection.xml> >> doc = Nokogiri::XML::Document.parse(f) => # You'll see the XML document output to the console.
还有两种快捷方式:
Nokogiri.xml()
Nokogiri::XML()
以上三种方法都是等价的。在以上代码中,doc是一个Document对象。 - 使用xpath得到一个NodeSet对象(一组Node)
>> items = doc.xpath("//Items/Item") => #You'll see the xml for our two items output to the console. >> items.count => 2
- 使用at_xpath得到匹配xpath的NodeSet中的第一个node(相当于xpath.first)
- Node对象的重要方法。通常,这些方法都使用在Element对象上。
- children:得到下属的NodeSet。
但有一个问题是,children方法会返回很多内容为"\n"的Text对象。比如,一个Element包含n个child,每个child之间由"\n"和blank分隔,则这些"\n"和blank也会成为children方法得到的Node,这样NodeSet得到的元素数目为2n+1。
要解决这个问题,需要在导入XML文件的时候使用noblanks方法。
doc2_without_blanks = Nokogiri::XML(f) do |config| config.noblanks end这样,一个包含n个child的Element,其children方法返回的NodeSet的元素数目为n。
- child:得到第一个Node对象(类似于xpath与at_xpath的关系)
- content: 得到该node的文字内容,等价于text
值得注意的是,content方法可以作用于包含文字内容(Text对象或CDATA对象)的Element对象,也可以直接作用于Text或CDATA对象,以上两种情况返回值是一样的。
doc.at_xpath("//Items/Item/Title").content => "Funfair in Bangkok"
doc.at_xpath("//Items/Item/Title").child.content
=> "Funfair in Bangkok"
- content: 得到该node的文字内容,等价于text
- content= 修改该node的文字内容(即,一个Text对象)
doc.at_xpath("//Items/Item/Title").content="abcdefg" => "abcdefg" doc.at_xpath("//Items/Item/Title").text => "abcdefg"
同样,content=可以作用于包含Text或CDATA的Element,也可以直接作用于Text或CDATA对象。但是,如果应用于CDATA对象,该对象会被覆写为Text对象!
- replace 将本Node替换成另外一个Node,例如:
doc.at_xpath("//Items/Item/Caption").child.text => "A small funfair near On Nut in Bangkok." doc.at_xpath("//Items/Item/Caption").child.replace Nokogiri::XML::CDATA.new(doc,"cdata test") => #<Nokogiri::XML::CDATA:0xd7d6ccc "cdata test"> doc.at_xpath("//Items/Item/Caption").child.text => "cdata test"
在上面的代码中,本来”Caption"这个Element里包含的Cdata的内容为“A small funfair near on Net in Bangkok",通过replace方法,将原先的CDATA Node换成了一个新的CDATA Node,内容为”cdata test". 在本例中,我们建立了一个新的CDATA对象,详细说明见下面一点。
- children:得到下属的NodeSet。
- CDATA类型的创建
- 用Nokogiri::XML::CDATA.new类方法创建。在上面的例子中,我们已经用了这种方法。
- 用Document的对象方法创建,如下例:
doc.at_xpath("//Items/Item/Caption").child.replace doc.create_cdata("cdata test2") => #<Nokogiri::XML::CDATA:0xd6a7ff4 "cdata test2"> doc.at_xpath("//Items/Item/Caption").child.text => "cdata test2"
两种方法的效果是相同的。
- 将Document对象写回xml文件
当我们对导入的xml文件进行了一些修改以后,我们希望把修改过的xml结构写回到文件里。做法如下例:
1 File.open("test2.xml","w") do |f2| 2 f2.puts doc.to_xml 3 end
在本例中,通过Document类的to_xml方法,把Document对象转化为xml格式的字串,再写入到test2.xml这个新文件里。



以上就是使用Nokogiri这个gem对xml操作的一些基本方法。在了解了上述方法之后,我们就能够做到,对于xml文件实现我们需要的一些修改。这篇文章是由我自己学习Nokogiri的笔记整理而成,希望能对Nokogiri的初学者能有一些帮助。
PS::本文主要的参考资料,是以下这篇教程:
http://www.58bits.com/blog/2012/06/13/getting-started-nokogiri-xml-ruby
本文使用的例子取材于些。我在这篇教程的基础上结合自己的碰到的情况做了一些整理并增加了一些内容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号