Java Reactor通信模型
前言
Netty是Java网络通信中高性能框架,但它为什么是高性能的呢?其中很大一个原因在于Netty采用Reactor通信模型。Reactor是同步IO的线程模型,效率高且编码易于理解,和它相对应的是基于异步IO的Proactor线程模型,Proactor同样高效,但因为是异步的处理方式,所以编码不易。
下面就来介绍Reactor通信模型的原理和实现。
BIO 和 NIO
首先,介绍两种最常见的通信方式,BIO和NIO。
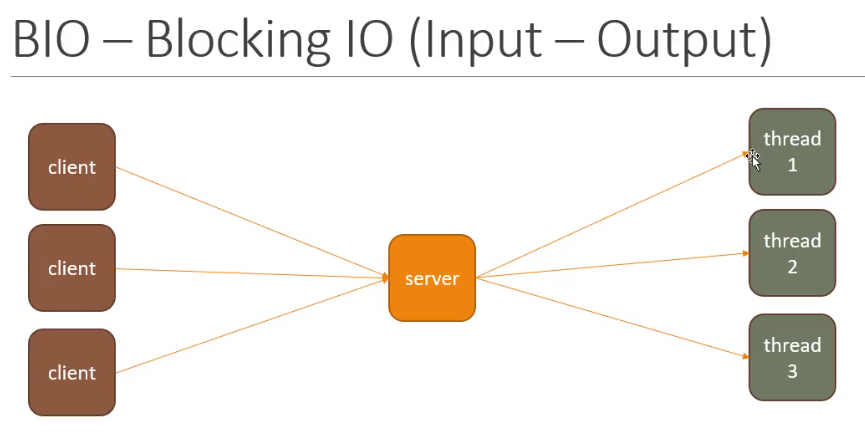
1、BIO
Blocking IO,阻塞IO。阻塞指的是调用accept、read、write等方法时,线程是阻塞的,必须一直等待相应的事件发生,而不能做其他的任何事情。
BIO下,每一个客户端连接后,都需要创建一个线程来处理连接和读写操作。所以,效率十分低下,只适用于连接数且读写操作比较少的场景。
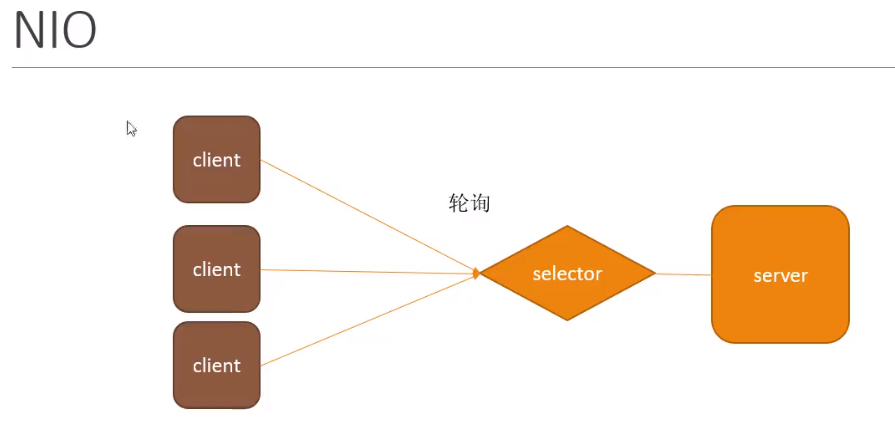
2、NIO
Non-blocking IO,非阻塞IO。非阻塞指的是调用accept、read、write等方法时,即使没有相应的事件发生,线程也不用一直在这等着,可以继续往下执行。
NIO下,客户端的连接和读写请求都是通过Selecor大管家进行处理的,即一个线程处理多个客户端的连接。所以,NIO的效率要比BIO高许多。并且,Reactor模型就是基于NIO通信方式实现的。
如果对BIO和NIO通信的源码有兴趣,请看文章末尾的链接。
Reactor模型
Reactor模型也主要有三种实现方式,单Reactor单线程、单Reactor多线程和主从Reactor多线程。
1、单 Reactor 单线程
该模式和NIO的通信方式一致,单线程处理客户端的连接和读写操作。缺点很明显,就是连接和读写多的情况下,效率低下。
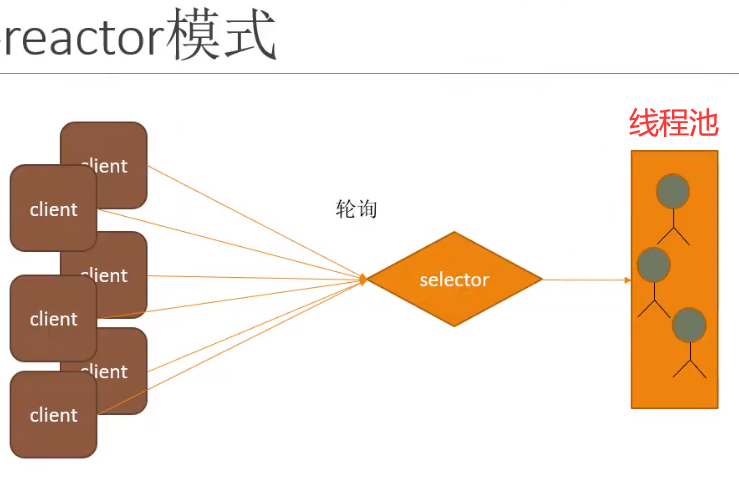
2、单 Reactor 多线程
该模式与NIO的区别在于,通过多线程的方式来处理客户端的读写操作,这样既减轻了Selector的压力,又保证了处理读写操作的能力。这个缺点在于Reactor既要负责客户端的连接,又要负责读写操作,连接操作比较快,但读写可能很多且比较耗时。
WorkHandler.java
package main.java.io.reactor.single;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.SocketChannel;
import java.util.concurrent.ExecutorService;
// 处理客户端读写操作
public class WorkHandler {
private final SelectionKey key;
private final ExecutorService executor;
private final ByteBuffer buffer;
public WorkHandler(SelectionKey sk, ExecutorService es) {
key = sk;
executor = es;
buffer = ByteBuffer.allocate(1024);
}
public void handle() {
SocketChannel channel = (SocketChannel) key.channel();
try {
int n = channel.read(buffer); // 执行 read 之后,selector.select() 才不会再次监听到同一个读事件
executor.execute(() -> {
try {
System.out.println("work handle call");
if (n > 0) {
String tn = Thread.currentThread().getName();
String str = String.format("%s %s %s",
"[SingleReactor]", tn, new String(buffer.array()).trim());
channel.write(ByteBuffer.wrap(str.getBytes()));
}
} catch (IOException e) {
e.printStackTrace();
}
});
} catch (IOException e) {
e.printStackTrace();
}
}
}
3、主从 Reactor 多线程
基于单 Reactor 多线程的缺点,于是有了主从Reactor模式,主 Reactor 只负责处理客户端的连接,从 Reactor 负责客户端的读写操作,并且是一主多从的模型。主从模型下,不仅遵循了单一职责的原则,还提高了承受读写负载的能力。
说了这么多,还是来看下这个的完整源码:
(1)MSReactor.java
package main.java.io.reactor.ms;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.util.Iterator;
/**
* 主从 Reactor,多工作线程
* Master-Slave Reactor,Multiple Worker Threads
*/
public class MainReactor {
private static final String ADDRESS = "127.0.0.1";
private static final int PORT = 8000;
public static void main(String[] args) {
try {
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.configureBlocking(false);
InetSocketAddress address = new InetSocketAddress(ADDRESS, PORT);
serverSocketChannel.bind(address);
System.out.println("MSReactor server bind " + address);
Selector selector = Selector.open();
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
for (;;) {
selector.select();
Iterator<SelectionKey> it = selector.selectedKeys().iterator();
while (it.hasNext()) {
SelectionKey key = it.next();
if (key.isAcceptable()) {
Acceptor acceptor = new Acceptor(serverSocketChannel, selector);
acceptor.accept();
}else if (key.isReadable()) {
SubReactor subReactor = new SubReactor(key);
subReactor.process();
}
it.remove();
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
(2)Acceptor.java
package main.java.io.reactor.ms;
import java.io.IOException;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
/**
* 处理客户端连接
*/
public class Acceptor {
private final ServerSocketChannel serverSocketChannel;
private final Selector selector;
public Acceptor(ServerSocketChannel ssc, Selector s) {
serverSocketChannel = ssc;
selector = s;
}
public void accept() {
try {
SocketChannel channel = serverSocketChannel.accept();
System.out.println("connected from " + channel.getRemoteAddress());
channel.configureBlocking(false);
channel.register(selector, SelectionKey.OP_READ);
} catch (IOException e) {
e.printStackTrace();
}
}
}
(3)SubReactor.java
package main.java.io.reactor.ms;
import java.nio.channels.SelectionKey;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 从 Reactor
*/
public class SubReactor {
private final SelectionKey key;
private final ExecutorService executor;
public SubReactor(SelectionKey k) {
key = k;
executor = Executors.newCachedThreadPool();
}
public void process() {
WorkHandler workHandler = new WorkHandler(key, executor);
workHandler.handle();
}
}
(4)WorkHandler.java
package main.java.io.reactor.ms;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.SocketChannel;
import java.util.concurrent.ExecutorService;
public class WorkHandler {
private final SelectionKey key;
private final ExecutorService executor;
private final ByteBufferPool pool;
public WorkHandler(SelectionKey sk, ExecutorService es) {
key = sk;
executor = es;
pool = new ByteBufferPool();
}
public void handle() {
SocketChannel channel = (SocketChannel) key.channel();
try {
if (!channel.isConnected()) {
System.out.println(channel.getRemoteAddress() + " close connect");
return;
}
ByteBuffer b1 = pool.borrowObject();
int n = channel.read(b1); // 执行 read 之后,selector.select() 才不会再次监听到同一个读事件
executor.execute(() -> {
try {
if (n > 0) {
String tn = Thread.currentThread().getName();
String str = String.format("%s %s ", "[MSReactor]", tn);
ByteBuffer b2 = pool.borrowObject();
b2.put(str.getBytes());
b1.flip(); // reset read pos
b2.put(b1);
b2.flip(); // reset read pos
channel.write(b2);
b1.clear();
b2.clear();
pool.returnObject(b1);
pool.returnObject(b2);
}
} catch (IOException e) {
e.printStackTrace();
}
});
} catch (IOException e) {
try {
channel.close();
} catch (IOException ioException) {
ioException.printStackTrace();
}
e.printStackTrace();
}
}
}
(5)ByteBufferPool.java
package main.java.io.reactor.ms;
import java.nio.ByteBuffer;
import java.util.LinkedList;
import java.util.Queue;
public class ByteBufferPool {
private final int cap;
private final int bufferSize = 256;
private final Queue<ByteBuffer> pool;
public ByteBufferPool() {
this(10);
}
public ByteBufferPool(int initialCap) {
cap = initialCap;
pool = new LinkedList<>();
initPool();
}
private void initPool() {
for (int i=0; i<cap; i++) {
pool.offer(ByteBuffer.allocate(bufferSize));
}
}
public boolean returnObject(ByteBuffer buffer) {
return pool.offer(buffer);
}
public ByteBuffer borrowObject() {
ByteBuffer buffer = pool.poll();
if (buffer == null) {
buffer = ByteBuffer.allocate(bufferSize);
}
return buffer;
}
}
看了源码,你是否发现ByteBuffer使用起来有点不方便。是的,JDK提供的ByteBuffer使用起来很不方便,甚至容易出错,需要开发人员注意向ByteBuffer写完数据,程序要读取数据之前要flip进行读写转换,其实也就是reset read/write position。
ByteBuffer不易使用在于它使用一个变量实现了读写指针,从而在写完之后读取数据时,要手动地进行读写转换。而如果使用过Netty地同学会发现,Netty提供的ByteBuf就不需要这个操作,因为ByteBuf使用了两个变量来表示读和写指针,从而避免了程序要手动地读写转换,这或许就是设计的魅力吧。
此外,为了提高读写效率,我用队列简单对BytBuffer实现了池化。
实现代码
代码请看GitHub仓库:
github - flowers-bloom - io
如果访问速度太慢,可访问Gitee:
gitee - flowers-bloom - io
参考
- [1] Reactor模型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号