
并发容器
为什么要用ConcurrentHashMap?
说到HashMap,应该都不陌生,但是说到ConcurrentHashMap,新手用过的应该比较少
HashMap本身是不适合多线程的,是没有并发安全保证的,为什么呢?因为HashMap的put操作会引起死循环,HashMap里面的Entry链表会产生环型的数据结构,导致调用get方法时会一值找不到下一个节点,而ConcurrentHashMap采用分段锁保证了线程安全的
HashTable为什么是线程安全的?:
还有别的线程安全的Map吗?有那就是HashTable;
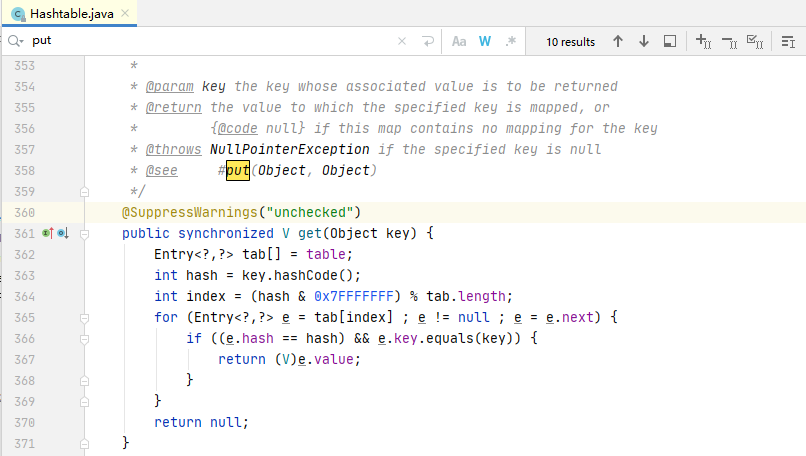
通过源码可以看出来为什么HashTable是线程安全的,因为方法直接被Synchronized修饰了,一把大锁加上去再安全不过了,不过相对的,性能会下降,因为锁的粒度非常粗,所有的线程被串行化了
然后我们来说说ConcurrentHashMap,然是如何实现的呢?
说之前,来说说hash吧,其实很多人都知道,hash但是具体是什么很少有人能直接说出来
Hash:(哈希)
hash还有一个名称那就是散列,或者哈希
把任意长度的输入通过一种算法(散列),变化成为固定长度的输出,这个输出值就是所谓的散列值.这个定义就是所谓的hash,输入压缩映射,不同的输入可能会压缩成相同的输出,容易造成哈希冲突,又叫直接取余法,
如果发生哈希冲突,有几种解决办法
1:开放寻址,
2:再散列
3:链地址
像md4,md5,sha都属于摘要算法,哈希算法
像MD摘要算法是不可逆的,当然应该有人也在百度上搜索到过MD5解密,他其实是,采用固定的默认的MD5把字符串加密后,存储起来,在你解密的时候采用彩虹表碰撞的到的值而已,所以他的原理是,碰撞,而不是解密
但是我们一般是不直接MD5的而是加入一些随机盐,来保证安全
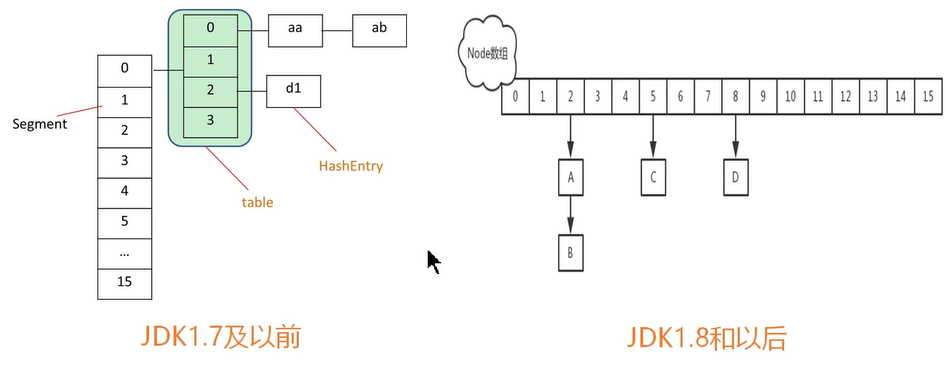
ConcurrentHashMap1.7到1.8的变化:
位运算:

其他的还有
符号 31位为0表示正数,31位为1表示负数
有符号左移(<<),只要左移到第31位就会消失
有符号右移(>>)
无符号右移(>>>)
其他的并发容器
ConcurrentSkipListMap
ConcurrentSkipListSet
什么是SkipList?
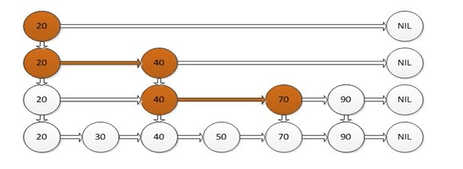
学过容器的人都知道,链表适合增加和删除概率
而数组适合查询
链表的缺陷就在于查询这里
而跳表就解决了这个缺陷,以空间换取时间,增加索引
在底层上一层一层的增加索引增加到满意为止

在插入索引的时候掷骰子,这个节点是不是索引完全取决于掷骰子,每一层都掷骰子,为true就添加,为false就不添加,所以在计算机学中调表也叫概率数据结构
有了索引之后如果要在70之后增加数据只要查询3次就可以,而不用去遍历整个链表,他的查询速度已经接近红黑树了,但是实现上要比红黑树简单的多
在常用的技术中,比如redis,Lucene中都使用了跳表
那为什么ConcurrentHashMap不用跳表而采用红黑树呢?
因为Map这种数据结构的空间利用率本身就不高,HashMap的空间利用率只有40%左右,而ConcurrentHashMap只会更低,所以在权衡后采用红黑树
ConcurrentLinkedQueue
无界非阻塞队列 可以看做LinkedList的并发版本 遵循先进先出原则
add,offer方法都是将元素插入到尾部
peek,poll都是从头部获取元素
peek从头部获取元素,但是不移除
poll从头部获取元素后移除头部元素
写时复制容器
CopyOnWriteArrayList
CopyOnWriteArraySet
就是在往容器中插入元素时会复制源容器,之后添加完成后,对指针进行替换
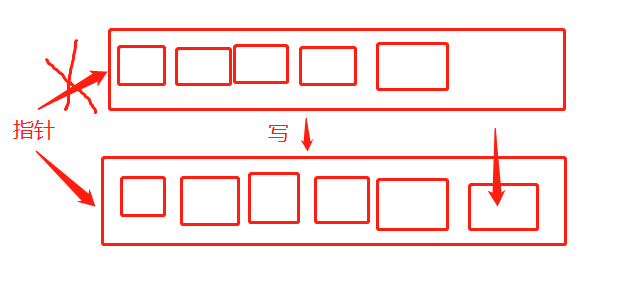
我感觉好像读写分离呀,原有的线程在源容器中,写完之后改指针
适用场景
适用于读多写少的场景,比如白名单,黑名单,商品类目的更新
只能保证数据的最终一致性,不能保证实时一致性
作者:彼岸舞
时间:2021\01\05
内容关于:并发编程
本文来源于网络,只做技术分享,一概不负任何责任

 浙公网安备 33010602011771号
浙公网安备 33010602011771号