
Mybatis源码学习第六天(核心流程分析)之Executor分析
今Executor这个类,Mybatis虽然表面是SqlSession做的增删改查,其实底层统一调用的是Executor这个接口
在这里贴一下Mybatis查询体系结构图
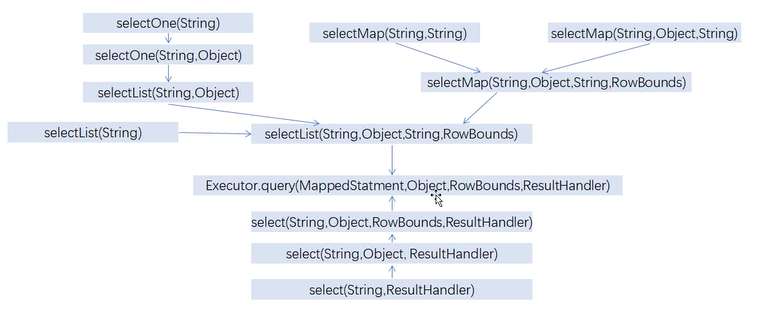
Executor组件分析
Executor是Mybatis的核心组件之一,定义了数据库操作最基本的方法,SqlSession的功能都是基于它实现的;

在分析这个之前先来说一下 大家不用想也知道 设计模式白,之前都是这么开始讲的,没错在这里我说一下模板模式
模板模式:一个抽象类公开定义了执行他方法的方式/模板,他的子类可以按需要重写方法的实现,但调用将以抽象类中定义的方法执行,定义一个操作中算法的骨架,而将一些步骤延迟到子类中,模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定实现;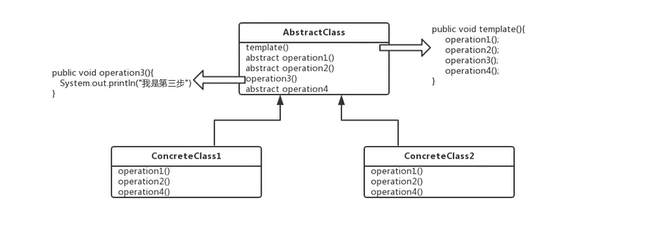
模板模式大家应该也都熟悉,举一些例子吧:就HttpClient的restTemplate,redisTemplate,等都是模板模式的标准样式;
模板模式的应用场景:
遇到由一系列步骤构成的过程需要执行,这个过程从高层次上看是相同的,但是有些步骤的实现可能不同,这个时候就需要考虑用模板模式了.
接下来我们说一下这个Executor吧;
其中就采用了模板模式,BaseExecutor就是模板模式中的抽象层,他实现了Executor接口的大部分方法,主要提供了缓存管理和事物管理的能力,其他子类需要实现的抽象方法为doUpate,doQuery等方法;
然后说一下Mybatis一次完整的执行流程吧
SqlSession执行
统一归到Executor的query中
贴一下executor.query的代码吧
1 @Override 2 public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { 3 BoundSql boundSql = ms.getBoundSql(parameter); 4 CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql); 5 return query(ms, parameter, rowBounds, resultHandler, key, boundSql); 6 }
开始获取Sql语句 从MappedStatement中获取,因为在初始化的时候是存储在MappedStatement中的,这里就不多讲了,想要了解的可以看我之前写的,也可以自行百度
通过已有的4种信息开始创建缓存的CacheKey,至于具体的可以看我之前分析Cache基础支撑模块的分析;
1 @SuppressWarnings("unchecked") 2 @Override 3 public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { 4 ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId()); 5 if (closed) { 6 throw new ExecutorException("Executor was closed."); 7 } 8 if (queryStack == 0 && ms.isFlushCacheRequired()) { 9 clearLocalCache(); 10 } 11 List<E> list; 12 try { 13 queryStack++; 14 list = resultHandler == null ? (List<E>) localCache.getObject(key) : null; 15 if (list != null) { 16 handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); 17 } else { 18 list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); 19 } 20 } finally { 21 queryStack--; 22 } 23 if (queryStack == 0) { 24 for (DeferredLoad deferredLoad : deferredLoads) { //对延迟加载的数据进行处理 25 deferredLoad.load(); 26 } 27 // issue #601 28 deferredLoads.clear(); 29 if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) { //如果当前Sql的一级缓存配置为STATEMENT,查询完立即清空一级缓存 30 // issue #482 31 clearLocalCache(); 32 } 33 } 34 return list; 35 }
非嵌套查询,并且FlushCache配置为true则清空一级缓存
根据CacheKey查询一级缓存,说道这里有人就会问,MyBatis不是先查二级缓存吗?不要着急,Mybatis的二级缓存不是在这里写的,等一会在来说,如果只是单纯分析BaseExecutor那么确实是直接查询一级缓存的
如果命中一级缓存 那么返回,如果没有命中那么从数据库中加载数据(有三种方法:Simple|Reuse|Batch),放入一级缓存中.
BaseExecutor定义了这样的一个查询骨架,能修改的或者说给子类重写实现的就只有关于数据库操作这一块了
Executor的三个实现类解读
SimpleExecutor:默认配置,使用PrepareStatement对象访问数据库,每次访问都要创建新的PrepareStatement对象;
ReuseExecutor:使用预编译PrepareStatement对象访问数据库,访问时,会重用缓存中的statement对象;
BatchExecutor:实现批量执行多条SQL语句的能力;
先来SimpleExecutor
1 @Override 2 public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException { 3 Statement stmt = null; 4 try {
//获取全局Configuration 5 Configuration configuration = ms.getConfiguration();
// 创建StatementHandler对象 6 StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// StatementHandler对象创建stmt,并用prepareStatement对占位符进行处理 7 stmt = prepareStatement(handler, ms.getStatementLog());
// 通过statementHandler对象调用ResultSetHandler将结果集转化为指定对象返回 8 return handler.<E>query(stmt, resultHandler); 9 } finally { 10 closeStatement(stmt); 11 } 12 }
1 private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException { 2 Statement stmt;
// 在这里获取的Connetion 3 Connection connection = getConnection(statementLog); 4 stmt = handler.prepare(connection, transaction.getTimeout()); 5 handler.parameterize(stmt); 6 return stmt; 7 }
1 protected Connection getConnection(Log statementLog) throws SQLException { 2 Connection connection = transaction.getConnection(); 3 if (statementLog.isDebugEnabled()) {
// 在这里返回的就是调用动态代理增强后的Connection
// 要了解日志模块关于参数语句等打印的请看之前的文章mybatis源码学习第一天 (logging模块),
// 在这里优雅的嵌入到代码中采用调用链的方式返回之后的打印增强类 4 return ConnectionLogger.newInstance(connection, statementLog, queryStack); 5 } else { 6 return connection; 7 } 8 }
简单说一下这个日志打印的调用链把 ConnectionLogger -> PrepareStatementLogger -> ResultSetLogger
之后再说StatementHandler,其实也是模板模式,抽象类构建骨架,三个子类实现,大家也可以先去看看,没啥难的
然后是ReuseExecutor
1 @Override 2 public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException { 3 Configuration configuration = ms.getConfiguration(); 4 StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql); 5 Statement stmt = prepareStatement(handler, ms.getStatementLog()); 6 return handler.<E>query(stmt, resultHandler); 7 }
看着一样是吧,确实没啥区别,具体的区别在prepareStatement方法中
1 private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException { 2 Statement stmt; 3 BoundSql boundSql = handler.getBoundSql(); 4 String sql = boundSql.getSql(); //获取Sql语句 5 if (hasStatementFor(sql)) { // 根据Sql语句检查是否缓存了对应的Statement 6 stmt = getStatement(sql); //获取缓存的Statement 7 applyTransactionTimeout(stmt); //设置新的超时时间 8 } else { // 缓存中没有statement创建Statement,创建statement过程和SimpleExecutor类似 9 Connection connection = getConnection(statementLog); 10 stmt = handler.prepare(connection, transaction.getTimeout()); 11 putStatement(sql, stmt); // 放入缓存中 12 }
// 使用PrepareStatement处理占位符 13 handler.parameterize(stmt); 14 return stmt; 15 }
不用想也知道缓存肯定是Map
1 private final Map<String, Statement> statementMap = new HashMap<>();
没错这个就是缓存的Map 在41行搁着呢,好了不逗了......接着说别的
二级缓存就是通过装饰器把CachingExecutor包装BaseExecutor,也就是二级缓存如果开启的话,就会包装一层CachingExecutor,所以说会先走二级缓存再走一级缓存,如果二级缓存没有开启的话,那么就直接走一级缓存
1 @Override 2 public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) 3 throws SQLException {
// 从MapperStatement中获取二级缓存 4 Cache cache = ms.getCache(); 5 if (cache != null) { 6 flushCacheIfRequired(ms); 7 if (ms.isUseCache() && resultHandler == null) { 8 ensureNoOutParams(ms, boundSql); 9 @SuppressWarnings("unchecked") 10 List<E> list = (List<E>) tcm.getObject(cache, key); 11 if (list == null) {
// 二级缓存为空,才会调用BaseExecutor.query 12 list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); 13 tcm.putObject(cache, key, list); // issue #578 and #116 14 } 15 return list; 16 } 17 } 18 return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); 19 }
装饰器模式之前在Cache模块中说过,不了解请百度一下,或看我之前写的Cache模块
Executor的三个执行器
通过对 SimpleExecutor doQuery方法的解读发现,Executor是指挥官,他在调度三个执行器工作;
StatementHandler:他的作用是使用数据库的Statement或PrepareStatement执行操作,启承上启下的作用;
ParameterHandler:对预编译的 Sql语句进行参数设置,SQL语句中的占位符 ? 都对应BoundSql.parameterMappings集合中的一个元素,在该对象中记录了对应的参数名称以及该参数的相关属性
ResultSetHandler:对数据库返回的结果集(ResultSet)进行封装,返回用户指定的实例类型;
在这里就像 SqlSession 说我不干活 Executor 你去干,我也不干 StatementHandler你去干
就像是 售前 ->> 项目经理 ->> 开发人员
在这里的三个执行器分别对应不同时段的处理
StatementHandler -> parameterHandler -> resultSetHandler
今天先写到这里吧,有点晚了,明天吧剩余的一点写一下!抱歉
作者:彼岸舞
时间:2020\03\22
内容关于:Mybatis
本文部分来源于网络,只做技术分享,一概不负任何责任

 浙公网安备 33010602011771号
浙公网安备 33010602011771号