结对编程作业
结对编程作业
| 队友博客 | 分工(1:1) |
|---|---|
| 高菲 | AI算法及代码,小程序,接口设计,编写博客 |
| 黄少丹 | 原型设计,小程序,接口设计,编写博客 |
| 菲雪落丹亭GitHub链接 |
一、原型设计
1.整体介绍
*说明:此次原型设计的完整文件夹放在GitHub上
此次结对编程作业采用的原型设计工具为Axcure Rp9.0。
由于一开始设想的是做一个图片华容道的拼图小程序,所以在原型设计上是以移动端为标准绘制原型。
但是实现的小程序功能并没有原型传达的那么完整(向实力低头),所以只有游戏界面。
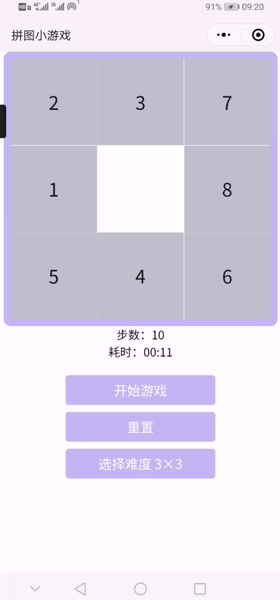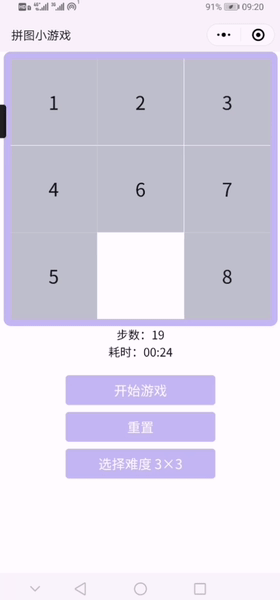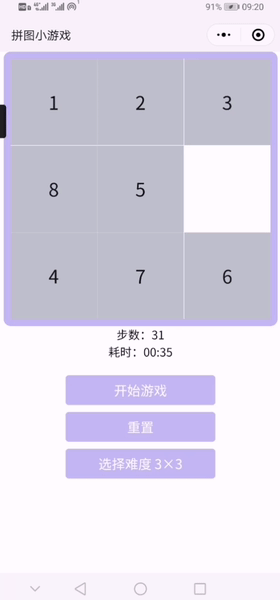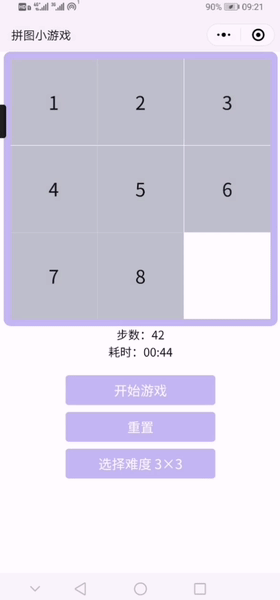
2.已实现小程序截图&小程序试玩录屏
难度可选择3*3-8*8
(小程序试玩录屏,已加速)
3.原型试玩
原型交互链接
流程图:
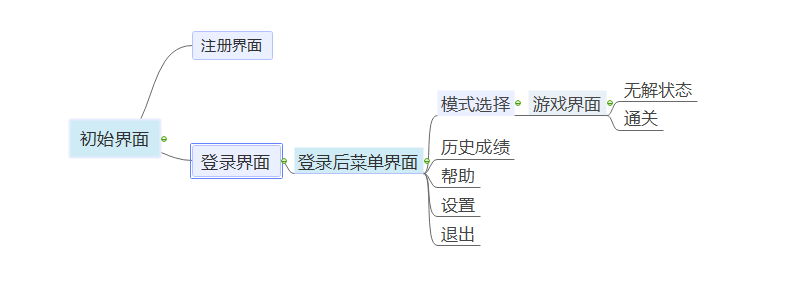
原型拼图试玩链接
截图:

AI自动解题

4.详细介绍:
目录
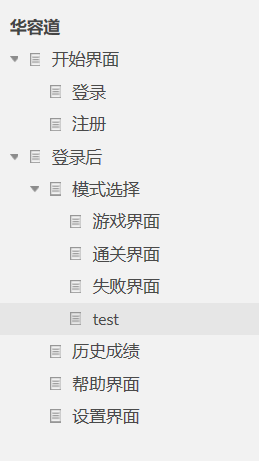
-
打开游戏后,进入初始界面,可选择登录或注册:



-
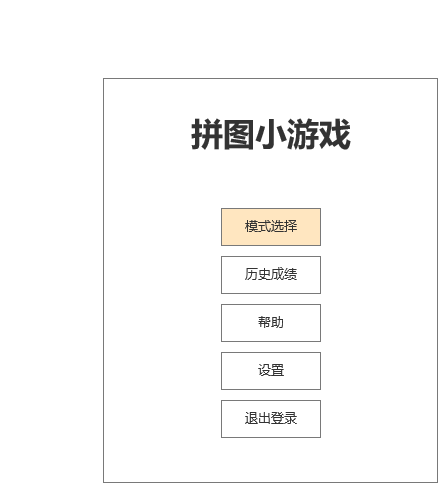
登录后,有五个选项,
1)选择游戏模式进行游戏
2)历史成绩
3)帮助
4)设置
5)退出
-
选择模式,目前仅开放3阶级别,想解锁更高级别需要在3阶级别达到一定成绩。

·游戏界面,可以选择暂停,重玩,返回开始菜单;
·有计时和步数功能。

·其中通关界面和失败界面如下:


-
历史成绩,有历史最高和上一局成绩,可返回菜单

-
帮助界面,主要是游戏规则介绍

-
设置界面,可以调整音乐和难度
-
退出,返回初始界面,切换账号
5.遇到的困难及解决方法
-
一开始以为是需要在原型上能直接进行游戏,苦恼,因为一直觉得原型只是用来展示功能的,以及添加一些简单的交互功能,要用原型来进行拼图游戏,这不可能啊!(
打脸)
然后,就开始一顿找材料......最后发现在Axcure里面可以使用功能函数移动图片,

从而达到实现拼图游戏的效果。(结果就是上面的原型试玩)
(自我反省..原型做得有一咻咻的简陋,UI美观是谈不上了。。不过主要也只是为了展示功能嘛自我安慰heihei)

-
做完原型后,听说还需要做小程序,让游戏可以在移动端快乐玩耍~~
坝特!我只是个小菜鸟啊,这种事情怎么可能会做呢??
然后又是一通找找找......最后,总算知道怎么开发一个属于自己的小程序了。(以后团队编程也不慌啦hhhh)
经过一通神奇的魔法施展之后,终于有一个可以玩的小程序啦。

-
你要问我有何收获?
其实很多时候一开始觉得做不了的事情,压力给到了,潜力自然就激发了。更何况互联网时代资源那么多,前人的肩膀那么高,作为享受时代科技成果的我们,作业无法做出来的情况是极少的。(只是做得精不精致的差别orz)
花精力去找资料,试着调试程序,修改代码,可以做得像点样子了,只是想做得更完美需要花更多的精力。
还有大概就是理想很丰满,现实很骨感= =

6.讨论照片

二、AI与原型设计实现
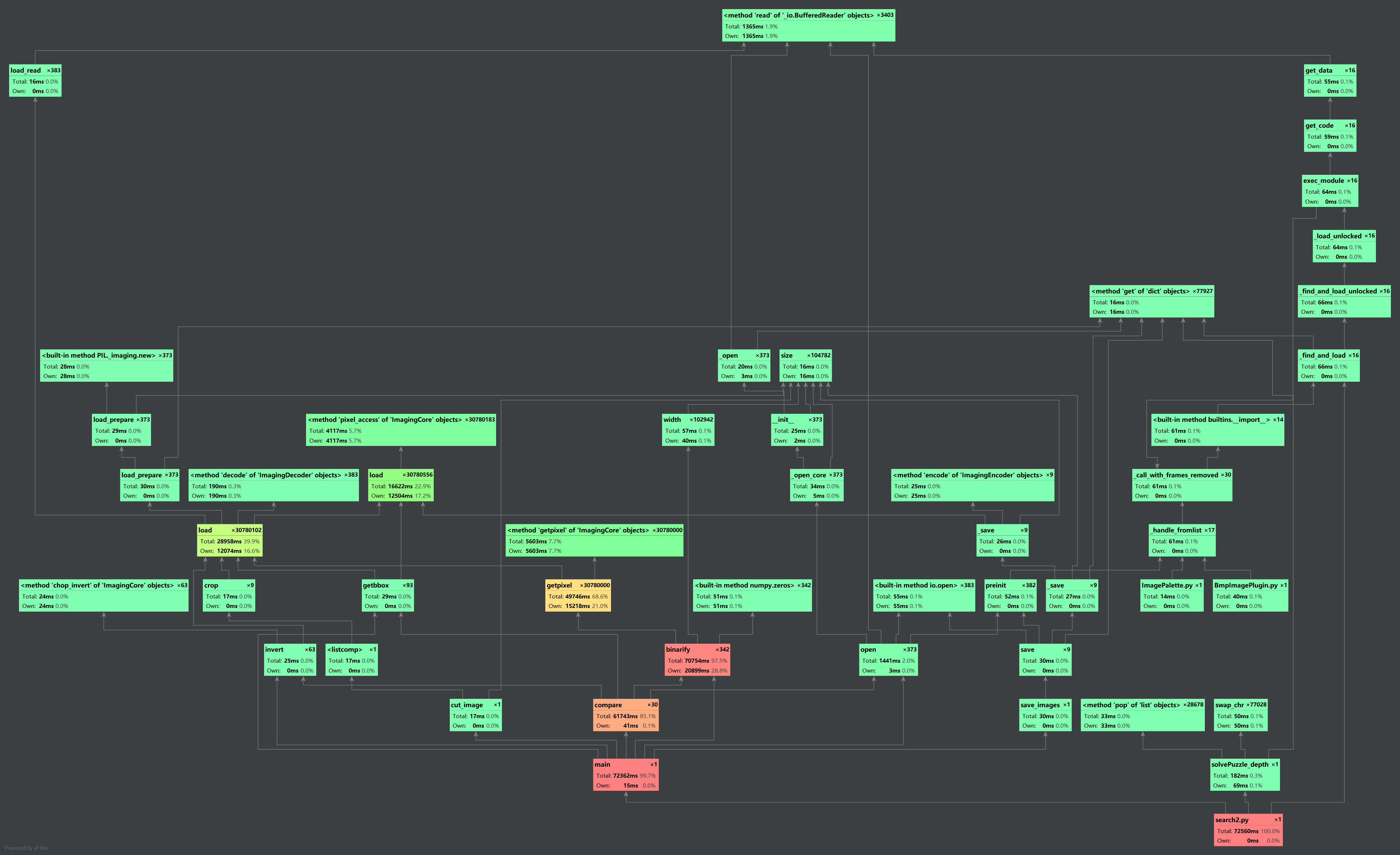
1.代码实现思路
- 网络接口的使用:
(1)对于提交题目,答案等操作使用的是Postman。
提交答案使用post的时候,需要添加headers,添加Key-Value值,Content-Type:application/Json;User-Agent:自己的headers。

后续进行AI大比拼的时候,获取赛题信息中的编码图片信息使用的并不是postman,而是使用python的爬虫技术,方便转换成图片并识别。如下:
(2)对于获取题目图片以及uuid,step:使用了requests库和re正则式匹配,字符串分割等操作,对图片进行转码,并下载
具体代码:
import base64
import requests
import re
def get_test_dict():
url = "http://47.102.118.1:8089/api/challenge/start/218ba788-b0a3-45d0-86b5-33b0e03e13c2"
payload = "{\r\n \"teamid\": 46,\r\n \"token\": \"5d6b1511-a783-4929-aa52-e3a69f197adf\"\r\n}"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36',
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
r'"raw_title":".+?"'
data = re.findall(r'\"img\":".+?"', response.text)
print(response.text)
data1 = eval(str(data[0]).split(':')[1])
return data1
def decode_base64(base64_data):
with open('./base64.jpg', 'wb') as file:
img = base64.b64decode(base64_data)
file.write(img)
return img
if __name__ == '__main__':
#img_path = './images/background.jpg'
#test_dict = get_test_dict()
base64_data = get_test_dict()
#print("uuid:"+ str(test_dict['uuid']))
#print(test_dict['step'])
#print(test_dict['swap'])
img = decode_base64(base64_data)
#print(img)
- 代码组织与内部实现设计(类图)
-
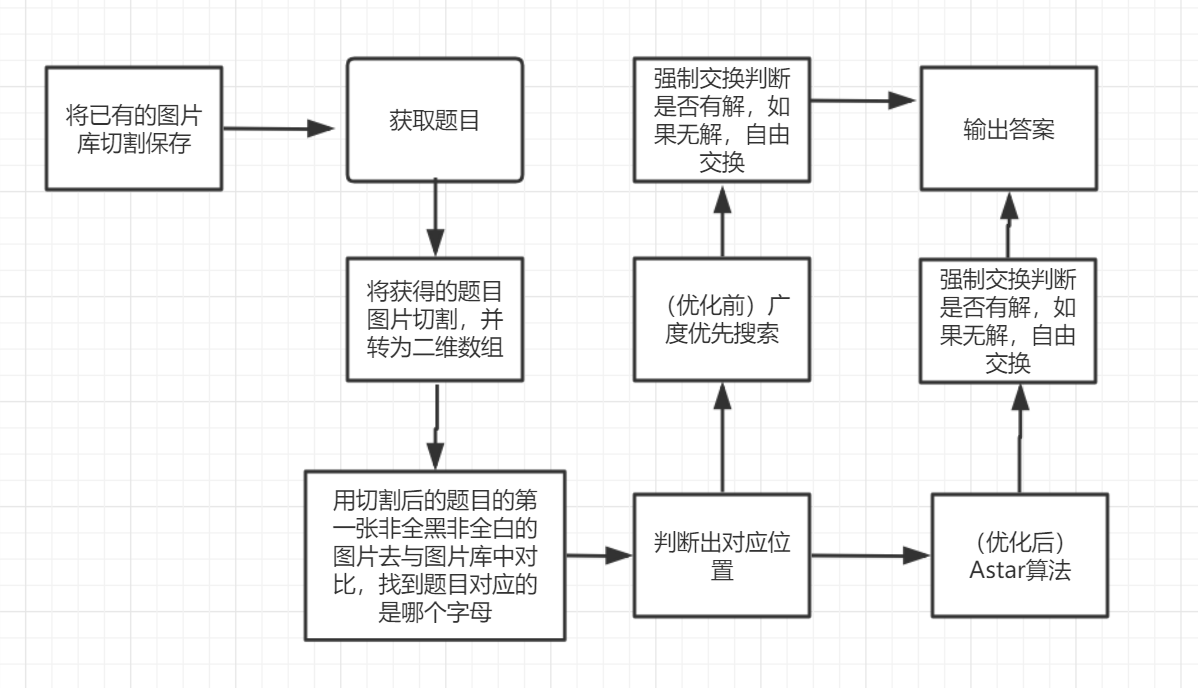
思路流程图:
-
算法的关键:
(1)奇偶性判别
起始位置与终止位置逆序值是否同奇同偶,强制交换后使用
(2)bfs广度优先搜索(优化前):

1)初始状态定义为一个字符串如'568103472'
2)目标状态可定义为字符串如'012345678'
3)可以将该棋盘的每一个状态看作是一个树节点,每次移动后产生一个新状态,每次移动可以看作是二维数组中某个数与0交换位置。
4)每次交换前的节点都会被保存在一个集合容器中并于目标状态进行比较,若相同则输出完整的从初始状态到目标状态的序列,若不同则保存在该集合容器中(保存的状态不能重复,也需要比较)。
5)循环
部分代码:
from test import main
g_dict_layouts = {}
#每个位置可交换的位置集合
g_dict_shifts = {0:[1, 3], 1:[0, 2, 4], 2:[1, 5],
3:[0,4,6], 4:[1,3,5,7], 5:[2,4,8],
6:[3,7], 7:[4,6,8], 8:[5,7]}
wasd={'01':'d','03':'s','10':'a','12':'d','14':'s','21':'a','25':'s','30':'w','34':'d','36':'s','41':'w','43':'a','45':'d','47':'s','52':'w','54':'a','58':'s','63':'w','67':'d','74':'w','76':'a','78':'d','85':'w','87':'a'}
def swap_chr(a, i, j):
if i > j:
i, j = j, i
#得到ij交换后的数组
b = a[:i] + a[j] + a[i+1:j] + a[i] + a[j+1:]
return b
def solvePuzzle_depth(srcLayout, destLayout):
#先进行判断srcLayout和destLayout逆序值是否同是奇数或偶数
#这是判断起始状态是否能够到达目标状态,同奇同偶时才是可达
src=0;dest=0
for i in range(1,9):
fist=0
for j in range(0,i):
if srcLayout[j]>srcLayout[i] and srcLayout[i]!='0':#0是false,'0'才是数字
fist=fist+1
src=src+fist
for i in range(1,9):
fist=0
for j in range(0,i):
if destLayout[j]>destLayout[i] and destLayout[i]!='0':
fist=fist+1
dest=dest+fist
if (src%2)!=(dest%2):#一个奇数一个偶数,不可达
return -1, None
#初始化字典
g_dict_layouts[srcLayout] = -1
stack_layouts = []
stack_layouts.append(srcLayout)#当前状态存入列表
bFound = False
while len(stack_layouts) > 0:
curLayout = stack_layouts.pop(0)#出栈
if curLayout == destLayout:#判断当前状态是否为目标状态
break
# 寻找0 的位置。
ind_slide = curLayout.index("0")
lst_shifts = g_dict_shifts[ind_slide]#当前可进行交换的位置集合
for nShift in lst_shifts:
newLayout = swap_chr(curLayout, nShift, ind_slide)
if g_dict_layouts.get(newLayout) == None:#判断交换后的状态是否已经查询过
g_dict_layouts[newLayout] = curLayout
stack_layouts.append(newLayout)#存入集合
lst_steps = []
lst_steps.append(curLayout)
while g_dict_layouts[curLayout] != -1:#存入路径
curLayout = g_dict_layouts[curLayout]
lst_steps.append(curLayout)
lst_steps.reverse()
return 0, lst_steps
def search(matrix):
for r in range(9):
if matrix[r]=='0':
return r
(3)A*算法(优化后):
公式表示为: f(n)=g(n)+h(n),
其中 f(n) 是从初始点经由节点n到目标点的估价函数,
g(n) 是在状态空间中从初始节点到n节点的实际代价,
h(n) 是从n到目标节点最佳路径的估计代价。
部分代码:
while(g_ListArr != []):
nowNum = g_ListArr[0]
g_ListArr.remove(nowNum) #从队列头移除
g_readArr.append(nowNum) #添加到已读队列
if nowNum.myList == g_GoalList:
print("Find The Answer!")
while(nowNum.myPreList != []):
print(nowNum.myList)
nowNum = nowNum.GetItsPre()
print(nowNum.myList)
break
else:
[idx, jdx] = nowNum.GetZeroIndex()
if idx - 1 >= 0:
upList = copy.deepcopy(nowNum.myList)
upList[idx][jdx] = upList[idx - 1][jdx]
upList[idx - 1][jdx] = 0
upNum = StruNum(upList, nowNum.myList, nowNum.myCost + 1)
#A*算法:代价 = 到达此状态代价 + 期望到达目标节点代价
upNum.myCost += upNum.GetGoalCost()
#如果新节点没有被走过
if upNum.GetListIndex(g_readArr) == -1:
tmpIndex = upNum.GetListIndex(g_ListArr)
if tmpIndex != -1:
#当新节点已经出现在未读队列中,如果新节点的代价更小,则更新,否则不更新
if upNum.myCost < g_ListArr[tmpIndex].myCost:
g_ListArr.remove(g_ListArr[tmpIndex])
g_ListArr.append(upNum)
else:
g_ListArr.append(upNum)
if idx + 1 < 3:
downList = copy.deepcopy(nowNum.myList)
downList[idx][jdx] = downList[idx + 1][jdx]
downList[idx + 1][jdx] = 0
downNum = StruNum(downList, nowNum.myList, nowNum.myCost + 1)
downNum.myCost += downNum.GetGoalCost()
# 如果新节点没有被走过
if downNum.GetListIndex(g_readArr) == -1:
tmpIndex = downNum.GetListIndex(g_ListArr)
if tmpIndex != -1:
# 当新节点已经出现在未读队列中,如果新节点的代价更小,则更新,否则不更新
if downNum.myCost < g_ListArr[tmpIndex].myCost:
g_ListArr.remove(g_ListArr[tmpIndex])
g_ListArr.append(downNum)
else:
g_ListArr.append(downNum)
if jdx - 1 >= 0:
leftList = copy.deepcopy(nowNum.myList)
leftList[idx][jdx] = leftList[idx][jdx - 1]
leftList[idx][jdx - 1] = 0
leftNum = StruNum(leftList, nowNum.myList, nowNum.myCost + 1)
leftNum.myCost += leftNum.GetGoalCost()
# 如果新节点没有被走过
if leftNum.GetListIndex(g_readArr) == -1:
tmpIndex = leftNum.GetListIndex(g_ListArr)
if tmpIndex != -1:
# 当新节点已经出现在未读队列中,如果新节点的代价更小,则更新,否则不更新
if leftNum.myCost < g_ListArr[tmpIndex].myCost:
g_ListArr.remove(g_ListArr[tmpIndex])
g_ListArr.append(leftNum)
else:
g_ListArr.append(leftNum)
if jdx + 1 < 3:
rightList = copy.deepcopy(nowNum.myList)
rightList[idx][jdx] = rightList[idx][jdx + 1]
rightList[idx][jdx + 1] = 0
rightNum = StruNum(rightList, nowNum.myList, nowNum.myCost + 1)
rightNum.myCost += rightNum.GetGoalCost()
# 如果新节点没有被走过
if rightNum.GetListIndex(g_readArr) == -1:
tmpIndex = rightNum.GetListIndex(g_ListArr)
if tmpIndex != -1:
# 当新节点已经出现在未读队列中,如果新节点的代价更小,则更新,否则不更新
if rightNum.myCost < g_ListArr[tmpIndex].myCost:
g_ListArr.remove(g_ListArr[tmpIndex])
g_ListArr.append(rightNum)
else:
g_ListArr.append(rightNum)
#按照COST排序
g_ListArr.sort(key=takeThr)
(4)bfs与A*算法的比较
BFS(广度优先搜索方法)是一种盲目式搜索,它实际上是一种最差的A*算法,认为h*(n)=0
(5)关于强制转换
如果强制转换后判断无解,自由调换就把调换的图片重新调换回来,若是有解,则按照原算法继续求解。
2.性能分析
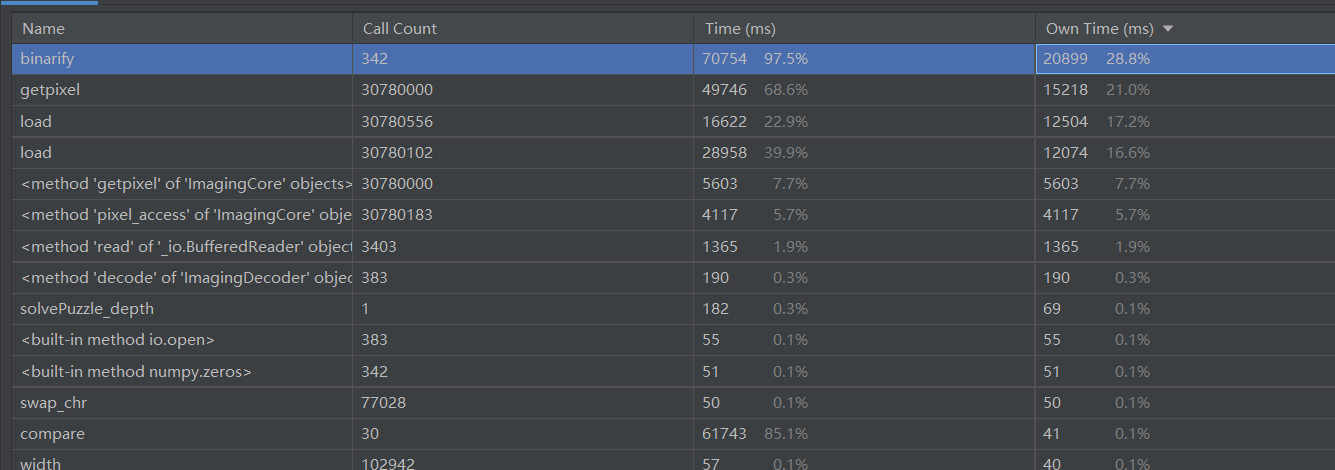
其中时间消耗最多的是binarify函数(用于将图片转为01二维数组)
- 性能改进
这部分上面有具体提到,是将bfs算法改成了A*算法
但其实性能分析中时间消耗最大的函数是binarify(将图片转为01二维数组),如果题目图片是a,b,c等靠前的字符时间就比较短,如果题目是x,y,z等靠后的字符时间就用的比较长
时间原因没有来得及修改
之后的改进方向:
二分法去比较,判断是哪个字符 - 单元测试

数据构造思路:就是将下图中某一个替换为空白,再随机拼起来(通过逆序值是否相同奇偶性来构造有解与无解的测试用例)

部分单元测试代码:
import unittest
import as_function
from BeautifulReport import BeautifulReport
class TestForAllIMG(unittest.TestCase):
@classmethod
def setUp(self):
print("开始单元测试……")
@classmethod
def tearDown(self):
print("已结束测试")
def x1(self):
as_function.testfunction('E:/image/1.png')
def x2(self):
as_function.testfunction('E:/image/2.png')
def x3(self):
as_function.testfunction('E:/image/3.png')
def x4(self):
as_function.testfunction('E:/image/4.png')
def x5(self):
as_function.testfunction('E:/image/5.png')
def x6(self):
as_function.testfunction('E:/image/6.png')
if __name__ == '__main__':
#unittest.main()
suite = unittest.TestSuite()
suite.addTest(TestForAllIMG('x1'))
suite.addTest(TestForAllIMG('x2'))
suite.addTest(TestForAllIMG('x3'))
suite.addTest(TestForAllIMG('x4'))
suite.addTest(TestForAllIMG('x5'))
suite.addTest(TestForAllIMG('x6'))
runner = BeautifulReport(suite)
runner.report(
description='论文查重测试报告', # => 报告描述
filename='nlp_TFIDF.html', # => 生成的报告文件名
log_path='.' # => 报告路径
)
3.github代码签入记录
由于AI大比拼的延迟,所以代码签入时间延迟到了19号。
4.困难:
- (1)模块异常困难:
得出相应位置后,无法与八数码算法拼接
解决方法:
进行了一些转换,空为0,比其大的都减一 - (2)结对困难:
因为分工比较明确,两方信息不太对等,缺少沟通,对彼此进度了解较少
解决方法:
每天沟通进度
5.评价你的队友
高菲说:
- 值得学习的地方
审美比我好,抗压能力比我强,学习能力也很强,表情包不错,行走的快捷小技巧,写作能力贼贼贼贼~优秀!在我心里就是最棒的! - 需要改进的地方
效率有待提高
黄少丹说:
- 值得学习的地方
学习能力贼贼贼贼~强!!做事条理清晰,效率很高,拎得清!斗图happy!
AI算法放心交给她!信任彼此!棒棒哒的小菲菲!送你一朵小红花! - 需要改进的地方
抗压能力有待提高
三、PSP表格及学习进度条
1.学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 90 | 90 | 6 | 6 | 学习A*算法;设计了原型初稿 |
| 2 | 220 | 310 | 10 | 16 | 实现了图片处理,基本实现完整代码;原型设计交互完善,实现拼图功能 |
| 3 | 360 | 670 | 15 | 31 | 实现接口设计,强制交换;开始进行小程序实现 |
| 4 | 200 | 870 | 24 | 55 | AI大比拼,代码拼接完善;小程序实现完毕 |
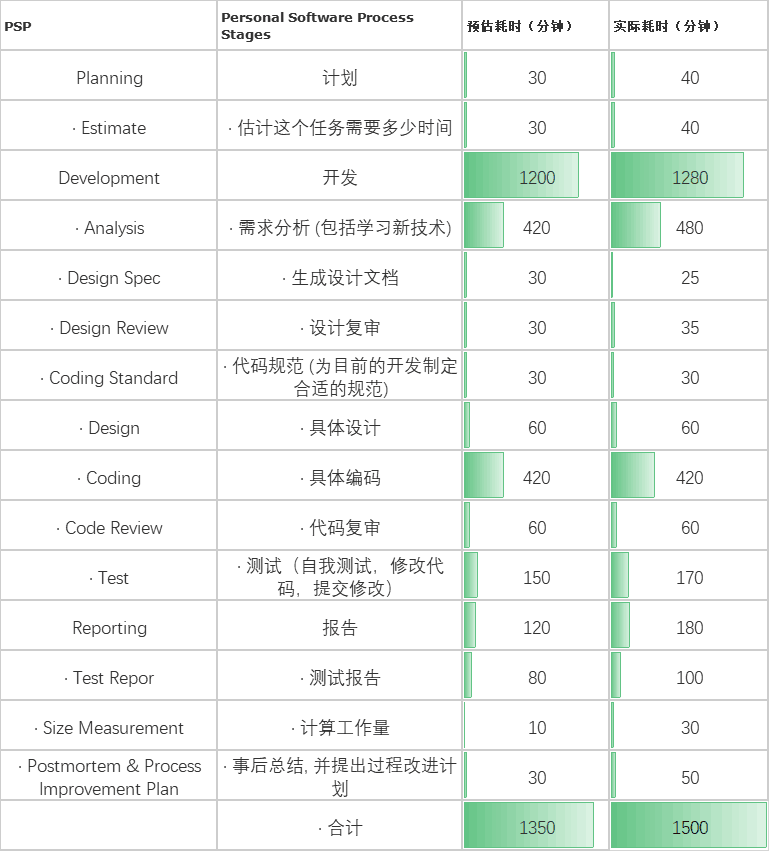
2.PSP表格

 浙公网安备 33010602011771号
浙公网安备 33010602011771号