ubuntu安装hadoop经验
安装环境:
1 linux系统
2 或(windows下)虚拟机
本文在linux系统ubuntu下尝试安装hadoop
安装前提
1 安装JDK(安装oracle公司的JDK )
(1)检查是否已安装JDK
$ java -version
(2)(本人采用手动安装)官网下载jdk,解压文件,放置在 /usr/目录下 如:/usr/local/jdk
(3)配置环境变量,设置全局(也就是此系统下所有用户的)环境变量
命令:$ sudo vi ~/.bashrc (用vi编辑器)
文件末尾添加:
#set java environment - 注释 export JAVA_HOME=/usr/local/jdk/jdk1.8.0_181 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH
保存后结束
(4)检查

2 安装ssh
(1)检查是否安装ssh(一般会自带客户端服务:ssh-client,本机需要安装对应的服务端服务ssh-server·「ssh-client与ssh-server版本要对应」)
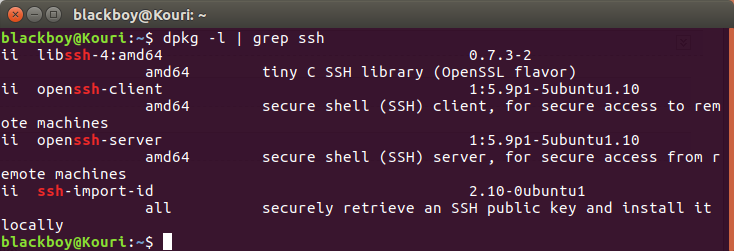
命令:$ dpkg -l | grep ssh
查看是否有 openssh-server
(2)安装openssh-server
命令:sudo apt-get install openssh-server
问题:因为本机已安装的openssh-client 与要安装的openssh-server不匹配,所以要先将openssh-client 降低版本
(3)查看ssh服务是否开启
命令:ps -e | grep sshd
如图:没有服务,而已安装,那就是没有启动

命令 ps -e | grep ssh
说明ssh-client服务开启,而ssh-server服务没启动

(4)启动ssh-server
命令:sudo /etc/init.d/ssh start 或 sudo service ssh start
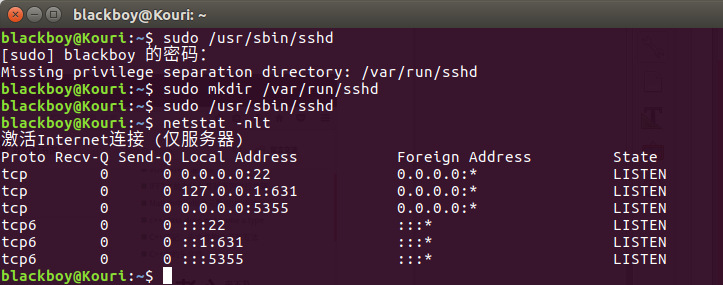
问题:依然没有启动,无法理解错误原因,但是找到解决方法,如图,当第四行 有 :::22表示开启22端口
(5)登录ssh
命令:ssh localhost

(6)设置ssh免码登录( 没有详细了解,有待继续学习 )
$ ssh-keygen -t rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
安装hadoop(搭建hadoop开发环境)
(1)官网下载hadoop,并解压好文件
(2)安装配置
先了解hadoop的运行模式
@运行模式
单机模式:默认,非分布式模式运行,读取本地资源,不使用hdfs(分布式文件系统),不加载hadoop守护进程
伪分布式:“单节点集群”上运行hadoop,所有守护进程运行在同一台机器上,读取hdfs上资源
全分布式:守护进程运行在一个集群上
@配置:
1 单机环境配置:
没有创建额外用户来使用hadoop,本次在当前用户下操作(可能会遇到权限问题)
$ vi .bashrc (用vi编辑 .bashrc)
将以下代码添加到 .bashrc 中
#set hadoop environment export HADOOP_HOME=/hadoop/hadoop-2.9.1 //hadoop文件路径 export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME
export HADOOP_ISTALL=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
vi /hadoop/hadoop-2.9.1/etc/hadoop/hadoop-env.sh (配置hadoop-env.sh 的JAVA_HOME环境变量)
export JAVA_HOME=/usr/local/jdk/.. //jdk文件路径
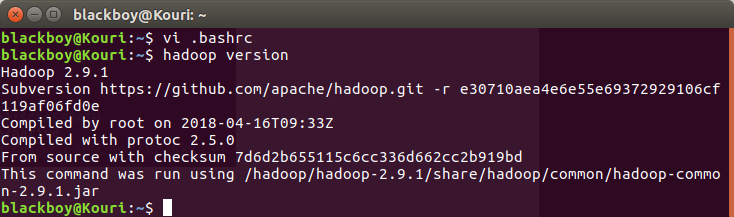
查看是否安装
2 伪分布式配置
(一)修改 /hadoop/hadoop-2.9.1/etc/hadoop/ 目录下的4个文件
注:只是进行简单的初期配置,更详细的配置可以去官网或百度查阅
(1)core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/hadoop-2.9.1/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Kouri:9000</value>
</property>
</configuration>
(2)hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/hadoop-2.9.1/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/hadoop-2.9.1/tmp/dfs/data</value>
</property>
</configuration>
(3)mapred-site.xml
因为初始只有mapred-site.xml.template,需要修改文件名
mv mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name></name>
<value></value>
</property>
</configuration>
(4)yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name> //主机名
<value>Kouri</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name> //浏览器地址
<value>localhost:8088</value>
</property>
</configuration>
(二)格式化HDFS
$ cd ~
$ hdfs namenode -format
(三)启动 (逐个启动/全部启动)
全部启动:start-all.sh
(四)查看进程
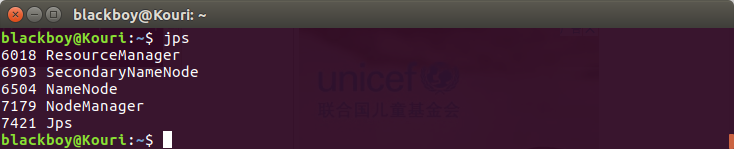
$ jps //列出守护进程
安装成功结果
(五)查看运行状态 - web界面
http://localhost:50070/ - Hadoop hdfs 状态
http://localhost:8088/ - hadoop yarn 管理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号