scala lambda 表达式 & spark RDD函数操作
形式:(参数)=> 表达式 [ 一种匿名函数 ]
例1:map(x => x._2)
解:x=输入参数,“=>” 右边是表达式(处理参数);
x._2 : x变为(**,x,**...)元组的第二个元素;
map ():将每一条输入参数映射为一个新的对象,在spark中会生成新的RDD,如下
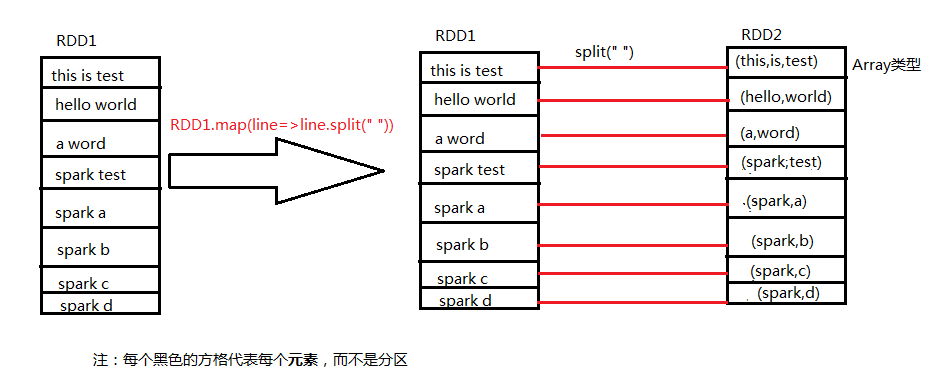
flatmap ()对比

例2:filter(line=>line.split(",")=="Tom")- 过滤
解:先 line.split(“,”),将每一行按“,”拆分,再选择其中==“Tom”的元素,形成新RDD
例3:val list=List(1,2,3,4)
list.reduce(_+_)
解: reduce(_+_)的下划线是占位符,表当前元素;
reduce()将对两个元素操作返回一个元素
reduceByKey()

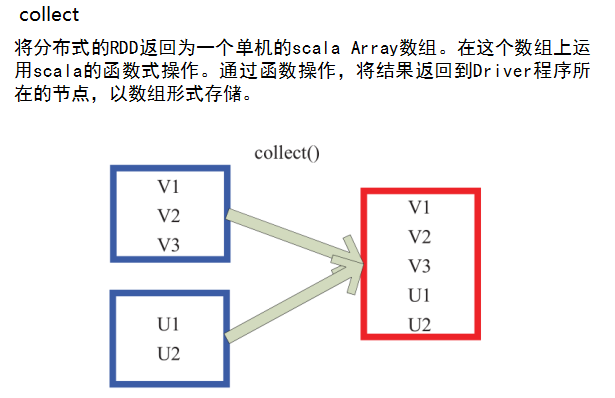
例4:collect()
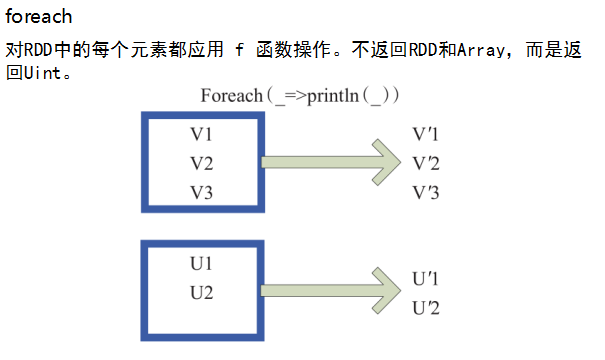
例5:foreach()
其他RDD操作:
flatten
zip
fold
groupByKey
patch
drop
sort
........
参考:https://www.cnblogs.com/spec-dog/p/4813933.html
https://www.cnblogs.com/zzhangyuhang/p/8989894.html
http://dblab.xmu.edu.cn/blog/961-2/
...................................................

 浙公网安备 33010602011771号
浙公网安备 33010602011771号