【LeetCode-BFS】单词接龙
题目描述
给定两个单词(beginWord 和 endWord)和一个字典,找到从 beginWord 到 endWord 的最短转换序列的长度。转换需遵循如下规则:
- 每次转换只能改变一个字母。
- 转换过程中的中间单词必须是字典中的单词。
说明:
- 如果不存在这样的转换序列,返回 0。
- 所有单词具有相同的长度。
- 所有单词只由小写字母组成。
- 字典中不存在重复的单词。
- 你可以假设 beginWord 和 endWord 是非空的,且二者不相同。
示例:
输入:
beginWord = "hit",
endWord = "cog",
wordList = ["hot","dot","dog","lot","log","cog"]
输出: 5
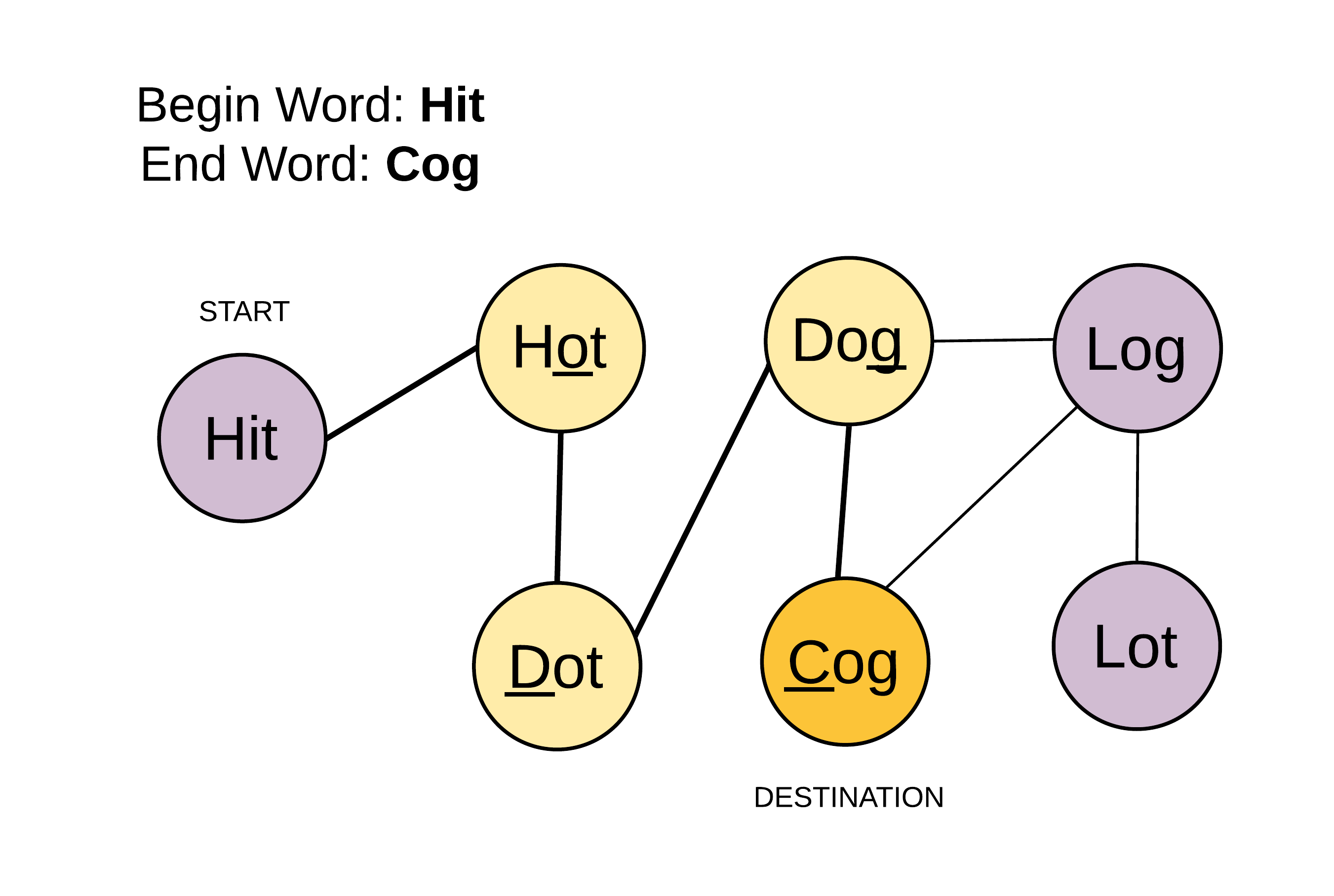
解释: 一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog",
返回它的长度 5。
题目链接: https://leetcode-cn.com/problems/word-ladder/
思路
题目中要求每次转换只能改变一个字母,所以我们可以把这个问题看做一个搜索问题,搜索从源单词到目标单词的一条路径。
现在有一个问题需要解决,就是我们如何判断两个单词是相邻的?例如,hit 和 hot 只有一个字母不同,是相邻的。我们每次改变单词的一个字母可以提取出单词的“模式”,例如,我们每次将“hit”中的一个字母改为“*”可以得到:*it、h*t 和 hi*。
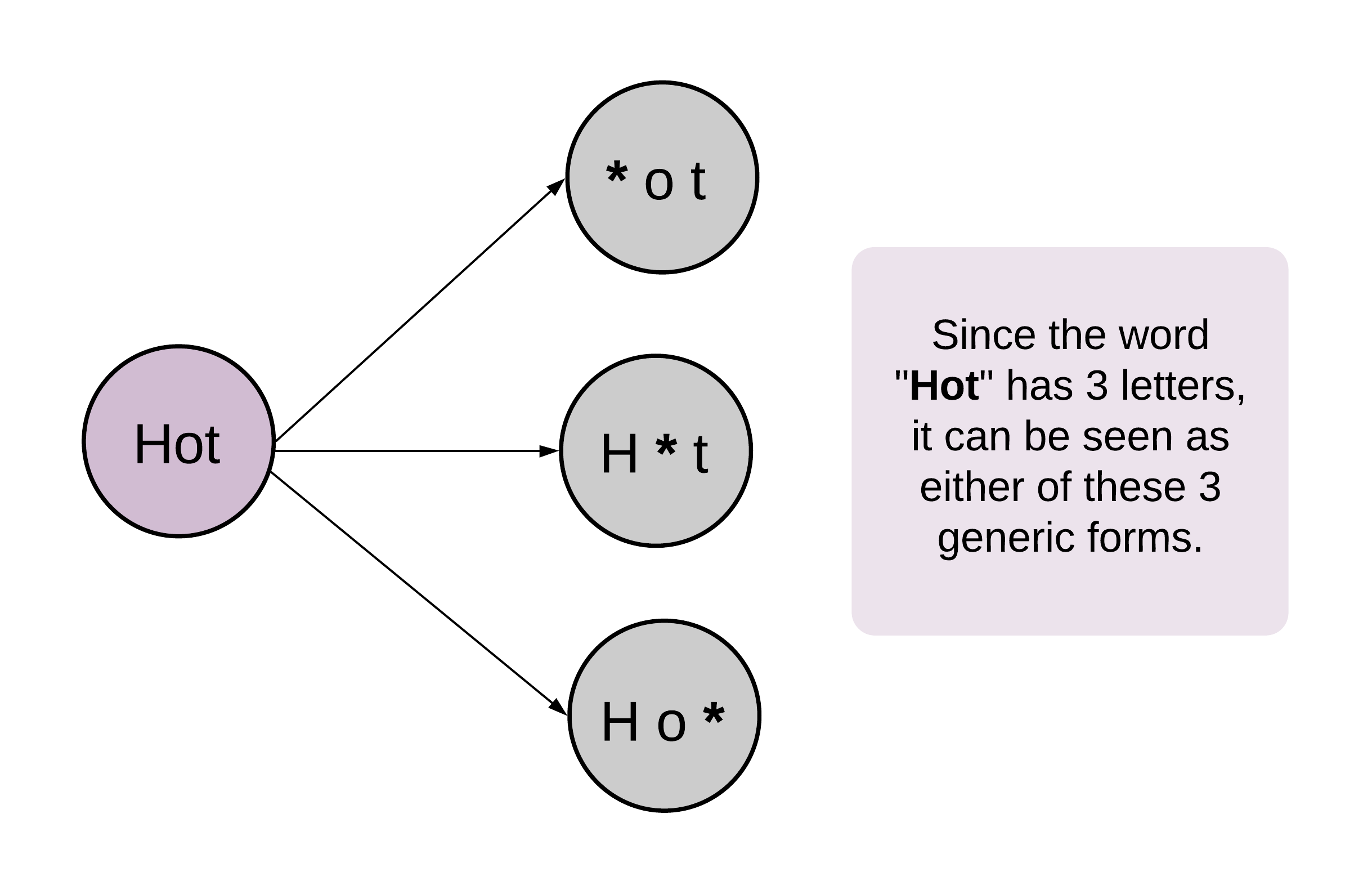
而对于 hot,我们进行同样的操作也可以得到 3 个模式:*ot、h*t 和 ho*。我们发现,hit 和 hot 的模式中都出现了 h*t,这说明 hit 可以通过替换一个字母转为 hot,这意味着 hit 和 hot 是相邻的。
知道了如何定义相邻,我们就可以使用 bfs 求解了。步骤如下:
- 首先根据字典 wordList 中的单词,求出每个单词的模式,并存放在哈希表中(
unordered_map<string, vector<string>> patterns),例如patterns['h*t']={"hot","hit"}的含义是 h*t 可以由 hot 和 hit 转换而来,hot 和 hit 是相邻的; - 然后将起始单词 beginWord 和当前走了几步放入队列中(可以使用 pair 将这两个变量封装起立,则队列的定义为
queue<pair<string, int>> q),标记 beginWord 已经被访问过; - 当队列不空,循环:
- 获取队头元素,从而得到当前的单词 curString 以及当前的路径长度 cnt;
- 通过每次替换 curString 中的一个字母为 * 计算 curString 的模式,并根据哈希表 patterns 获取 curString 的下一个单词;
- 如果 curString 的下一个单词是目标单词 endWord,则返回 cnt+1;
- 否则,如果 curString 的下一个单词没有被访问过,则将 {curString, cnt+1} 入队,并标记 curString 已经访问过;
- 如果队列为空,说明无解,返回 0;
代码如下:
class Solution {
public:
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
unordered_map<string, vector<string>> patterns;
for(auto word:wordList){
for(int i=0; i<word.size(); i++){
string temp = word;
temp[i] = '*';
patterns[temp].push_back(word);
}
}
queue<pair<string, int>> q;
unordered_map<string, bool> visit; // 标记单词是否访问过
q.push(make_pair(beginWord, 1));
visit[beginWord] = true;
while(!q.empty()){
pair<string, int> pr = q.front(); q.pop();
string curString = pr.first;
int cnt = pr.second;
for(int i=0; i<curString.size(); i++){
string temp = curString;
temp[i] = '*';
if(patterns.find(temp)!=patterns.end()){
vector<string> candis = patterns[temp];
for(string candi:candis){
if(candi==endWord) return cnt+1;
if(!visit[candi]){
q.push(make_pair(candi, cnt+1));
visit[candi] =true;
}
}
}
}
}
return 0;
}
};
其实,我们也可以不使用 patterns 来记录模式,而是直接将当前单词 curString 和字典 wordDict 中的单词逐个比对,判断不同字母的个数是否等于 1,如果等于 1 并且没访问过就入队。这种方法相对会更容易被想到,而且代码也会更简洁,但是会超时。代码如下:
class Solution {
public:
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
queue<pair<string, int>> q;
unordered_map<string, bool> visit; // 标记单词是否访问过
q.push(make_pair(beginWord, 1));
visit[beginWord] = true;
while(!q.empty()){
pair<string, int> pr = q.front(); q.pop();
string curString = pr.first;
int cnt = pr.second;
for(auto word:wordList){
if(visit[word]) continue;
int diffCnt = 0;
for(int j=0; j<word.size(); j++){
if(curString[j]!=word[j]) diffCnt++;
}
if(diffCnt==1 && !visit[word]){
if(word==endWord) return cnt+1;
q.push(make_pair(word, cnt+1));
visit[word] = true;
}
}
}
return 0;
}
};
// 超时

 浙公网安备 33010602011771号
浙公网安备 33010602011771号