【深度学习】模型压缩
通常我们训练出的模型都比较大,将这些模型部署到例如手机、机器人等移动设备上时比较困难。模型压缩(model compression)可以将大模型压缩成小模型,压缩后的小模型也能得到和大模型接近甚至更好的性能。这篇文章总结了几种常用的模型压缩方法:网络裁剪(network pruning)、知识蒸馏(knowledge distillation)、参数量化(parameter quantization)以及模型结构设计(architecture design)。
网络裁剪
一些研究表明,我们训练出的很多大模型的参数都是过多的(over-paramerterized),有很多冗余参数或者神经元。我们可以将这些冗余的参数和神经元给裁减掉,从而减小模型的体积。网络裁剪的方法有参数裁剪和神经元裁剪。
参数裁剪
如果一些参数接近于 0,那么我们就可以把这些参数给裁减掉。也就是说,可以通过判断某参数的 l1 或者 l2 范数是否接近于 0 来决定是否要裁剪该参数。

参数裁剪之后,模型变得不对称了。不对称的模型难以用代码实现(通常使用 0 来代替被裁剪的权重),也难以利用 GPU 进行加速。
神经元裁剪
如果我们在训练的过程中,某一神经元的输出在大多数情况下都为 0 或者接近 0,那么我们就可以把这个神经元给裁减掉。
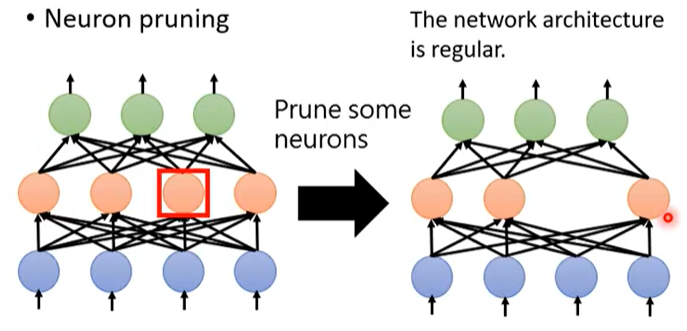
神经元裁剪之后网络还是对称的,所以神经元裁剪比参数裁剪更容易实现,也更容易利用 GPU 加速。
裁剪后微调
我们在模型裁剪之后会得到一个小模型,小模型通常会损失一些性能。为了提高小模型的性能,我们可以将小模型在原来的训练集上进行微调,这样可以将丢失的性能填补回来。

上图是网络裁剪的流程图。需要的注意的是,不要一次将模型裁剪太多,这样的话模型的性能很难恢复。所以,每次对模型裁剪一点,循环裁剪多次,直到模型达到自己的要求。
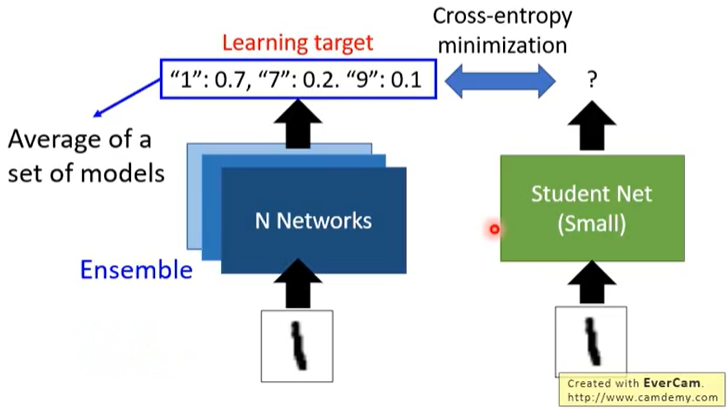
知识蒸馏
知识蒸馏(knowledge distillation)的思想是先训练一个大模型(teacher),然后再训练一个小模型(student)来拟合大模型的输出。这样,最终得到的小模型体积比大模型小,但能获得和大模型接近的性能。

在上图中,我们要训练一个模型对手写数字进行分类。首先将“1”输入到大模型中,大模型的输入为:"1":0.7, "7":0.2, "9":0.1,也就是模型认为这张图片是 1 的可能性为 0.7, 是 7 的可能性为 0.2, 是 9 的可能性为 0.1,然后我们再训练一个小模型来同时拟合原来的标签 1 (hard target)和大模型的输出(soft target)。大模型的输出能带来更多的信息,例如,通过大模型的输出我们可以得到输入的标签为 1 ,而且我们还可以知道 1、7、9 这 3 个数字是相似的,这是原始数据集中没有的。假设输入为 x,正确标签为 y,大模型(teacher)的输出概率为 p,小模型(student)的输出概率为 q,则小模型的训练目标为:
其中,\(CE\) 为交叉熵(Cross Entropy),\(\alpha\) 为权重。
知识蒸馏也可以应用于模型融合(ensemble)。例如,在 kaggle 比赛中,为了获得更好的成绩,我们通常会融合多个模型,在分类问题中,一种融合模型的方法是将各个模型的输出概率求平均作为最终的输出概率。这种方法在比赛中可以使用,但在实际使用中意义不大,因为融合多个模型会增加推断时间,而且总的模型体积也会成倍增加。可以使用知识蒸馏来解决这个问题。拿分类问题举例,我们融合后的结果是多个模型输出概率的平均,所以我们可以再训练一个小模型来拟合大模型融合后的结果。这样就相当于用一个小模型来替代了参与融合的所有模型。
在分类问题中,网络的最后一层通常是一个 softmax 层,softmax 的计算方法如下
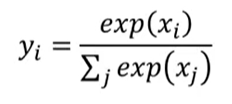
这样会有一个问题。例如,我们在训练大模型(teacher)的时候,假设是 3 分类问题,softmax 的输入为:x1:100, x2:10, x3:1,这样 softmax 的输出会接近 1, 0, 0,因为这 3 个输入差的太多了,所以输出会接近 one hot vector。而1, 0, 0这样的 one hot 输出和原始数据集中的输出的一样的,小模型(student)不会从这样的输出中学到其他的信息,蒸馏学习也就失去了意义。
为了避免这个问题,我们需要在 softmax 中增加温度参数 T,此时,softmax 的计算方法如下

也就是先对 softmax 的输入除以 T。上图中 T=100,所以输入由x1:100, x2:10, x3:1变成了x1:1, x2:0.1, x3:0.01,此时 softmax 的输出为 0.56, 023, 0.21,这样小模型(student)就可以从大模型(teacher)的输出中学到其他的信息。
参数量化
参数量化(parameter quantization)通过对模型的参数做一些限制来减小模型的体积。
使用 16 bit
模型参数模型是 32 位的,我们知道如果在训练时使用 16 位来进行训练,会大大降低显存占用并加快训练速度。所以,我们可以用 16 位的参数来代替 32 位的参数来实现模型压缩。
参数聚类
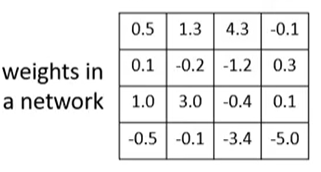
参数聚类(parameter clustering)使用聚类算法(例如 k-means)将相似的参数转为同一个值,然后记录某个参数属于哪个簇以及该簇对应的参数值是多少即可。例如,聚类前的参数如下
我们通过聚类得到了 4 个簇,每个簇用一种颜色表示
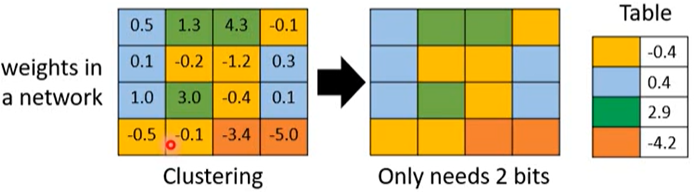
因为有 4 个簇,所以我们可以用 2 个二进制位来表示每个参数,例如 00 表示蓝色簇。然后再使用一个表来记录颜色和参数的对应关系。这样的话可以大大减少模型的体积。还可以使用哈夫曼编码来对簇的编码进行进一步的优化。
Binary Weights
我们还可以使用 binary weights,也就是每个参数的取值只有两种 0 或者 1。直觉上这样的网络的性能可能会很差,实际上,使用 binary weights 的网络和使用普通 weights 的网络在一些分类问题上的性能差距不是很大
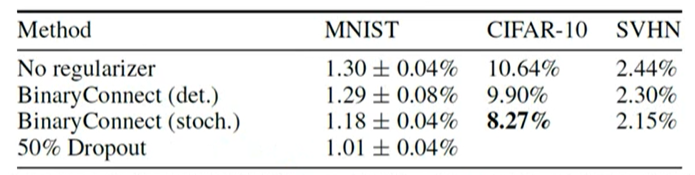
表格中的值为分类错误率。Binary weights 能达到这样性能的原因可以从正则化方面进行解释。Binary weights 对参数进行了限制。
模型结构设计
还可以从模型结构设计(architecture design)方面入手来减少模型的参数。
考虑如下图所示的神经网络
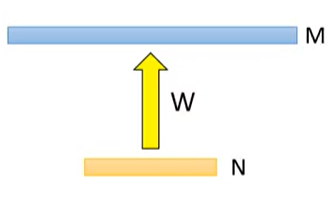
第一层有 N 个神经元,第二层有 M 个神经元,则参数大小为 M × N。我们在两层之间插入一个包含 K 个神经元的新层且该层不使用激活函数,其中 K<M,N,如下
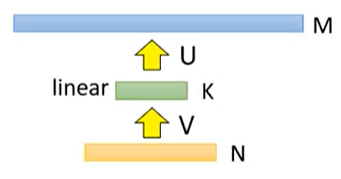
则参数矩阵变成了两个矩阵 M × K 和 K × N 之和。当 K<M,N 时,参数数量会降低(ALBERT就使用了这个技巧)。
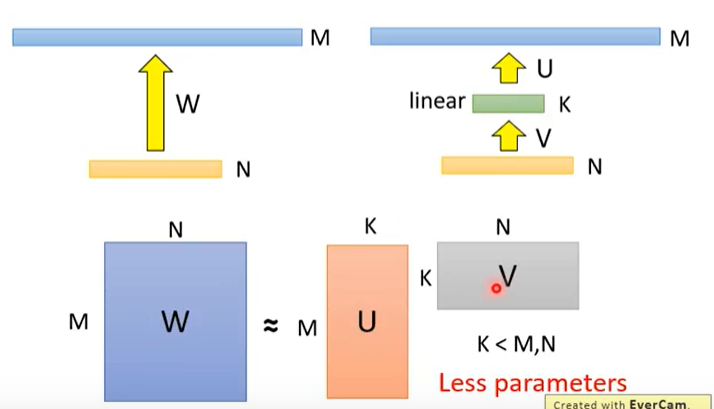
这一技巧会降低参数矩阵的秩(rank),所以也叫做低秩近似(low rank approximation)。
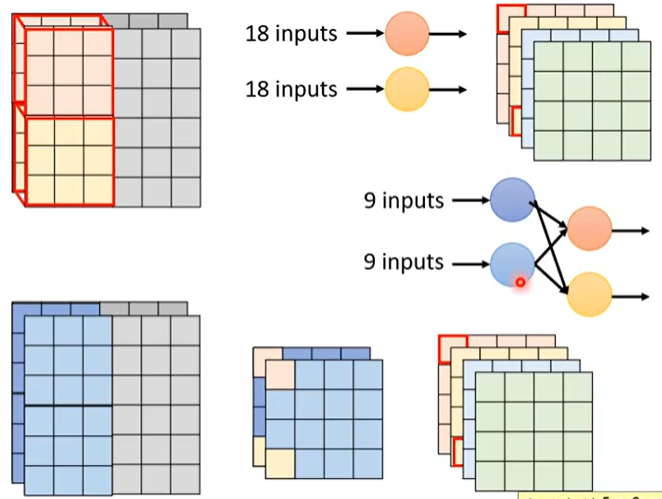
我们再把这一技巧推广到卷积神经网络(CNN)中。假设我们的输入形状为 6 × 6 × 2,也就是 2 个信道,每个信道的形状为 6 × 6,如下
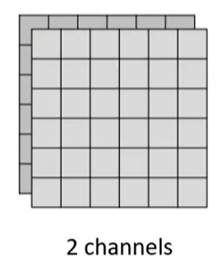
因为输入的信道为 2,则卷积核的信道也为 2,假设我们使用 4 个 3 × 3 × 2 的卷积核对输入进行卷积,则最终结果的形状为 4 × 4 × 4,如下
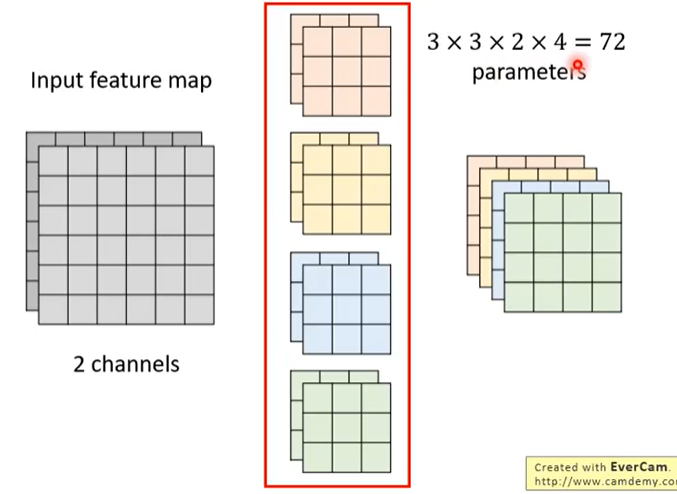
这样共需要 72 个参数。
我们对卷积的过程分为两个步骤:depthwise convolution 和 pointwise convolution,这叫做 Depthwise Separable Convolution。首先,我们使用 2 个 3 × 3 的卷积核分别对输入的两个信道进行卷积
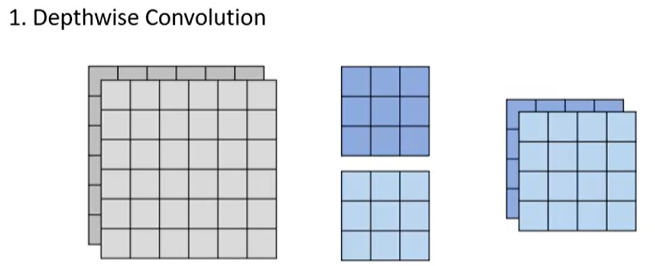
在上图中,深蓝色卷积核对深灰色输入信道进行卷积,浅蓝色卷积核对浅蓝色输入信道进行卷积最终得到 2 个 4 × 4 的输出,这一步骤叫做 depthwise convolution。
然后,我们对这 2 个 4 × 4 的输出进行 pointwise convolution,具体是使用 4 个 1 × 1 × 2 的卷积核对其进行卷积

最终会得到的输出和常规卷积的输出具有相同的尺寸,但是我们只用了 18 + 8 = 26 个参数。
其实,我们将卷积分为两个步骤就相当于在两个线性层中间插入一个更小的层
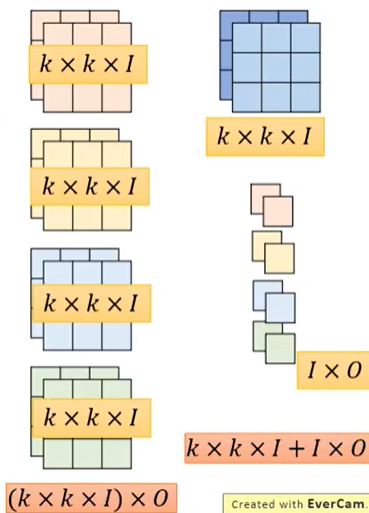
下面估计一下这种卷积参数量的差距。使用 I 表示输入信道的个数,在上面的例子中,I=2,;使用 O 表示输出信道的个数,上面的例子中 O=4;使用 k 表示卷积核的大小。则常规卷积需要的参数数量为 (k × k × I)× O,而 Depthwise Separable Convolution 需要的参数数量为 k × k × I + I × O。
两者的比值为
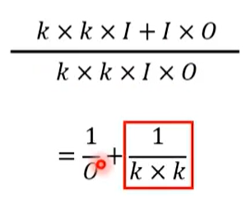
通常,O 比较大,例如 256,所以最终的结果接近 \(\frac{1}{k*k}\),含义是假设卷积核的尺寸为 3,那么 Depthwise Separable Convolution 需要的参数量为常规卷积参数量的九分之一。这一技巧在 MobileNet 中被使用。
总结
这篇文章介绍了网络裁剪(network pruning)、知识蒸馏(knowledge distillation)、参数量化(parameter quantization)以及模型结构设计(architecture design)这 4 种模型压缩的方法,主要参考了李宏毅《深度学习2019》课程。这 4 种方法基本上都是从减少模型参数的角度来进行模型压缩,只有使用 16 位模型这种方法是从存储角度来压缩模型。还有一个问题,就是既然我们需要小模型,那么为什么不直接训练小模型呢?原因是大模型通常更加容易训练而且性能也会更好。
参考
1、李宏毅《深度学习2019》
2、https://posts.careerengine.us/p/5e040074089a4c71be7da859

 浙公网安备 33010602011771号
浙公网安备 33010602011771号