【Pandas】 pandas 常用操作
读取 CSV 文件
可以使用 pd.read_csv() 来读取文件,pd.read_csv()的参数非常多,这里只对常用参数和用法做总结,全部参数可参考官方文档。
常用参数:
- filepath_or_buffer :要读取的文件路径;
- sep:分隔符,对 csv 文件来说,每行数据分隔符为逗号
,,默认值为,; - delimiter 是 sep 的别名;
- header:是否读入表头,
header=None则不读入文件中的表头,使用默认的表头([0,1,...])
假设文件D:\\test.csv的内容如下
name,gender,1,2
tom,male,3,3
jane,female,4,4
erik,male,5,5
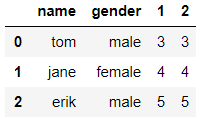
使用pd.read_csv()来读取文件
df = pd.read_csv('D:\\test.csv', sep=',')
df
输出
如果不需要读入表头的话,指定header=None即可
df = pd.read_csv('D:\\test.csv', header=None)
df
输出
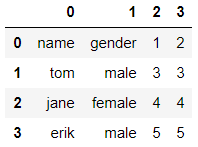
可以看到,表头被替换成了默认的索引。
删除行
创建DataFrame
df = pd.DataFrame({'name':['jane', 'mike', 'eric'],
'gender': ['female', 'male', 'male'],
'age': [18, 19, 20]})
df.head()
输出:

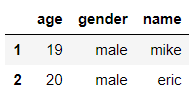
删除第0行
df = df.drop(0, axis=0) #axis=0表示按行删除
df
输出
删除第i行
df = df.drop(i, axis=0)
删除列
创建DataFrame
df = pd.DataFrame({'name':['jane', 'mike', 'eric'],
'gender': ['female', 'male', 'male'],
'age': [18, 19, 20]})
df.head()
输出:
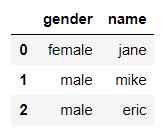
删除第 0 列,也就是 age 列
df = df.drop(df.columns[0], axis=1) # axis=1表示对列进行操作
df
输出
也可以指定列名删除
df = df.drop('age', axis=1)
df
输出
还可以使用del直接删除
del df['name']
df
输出
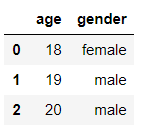
删除多列
df = df.drop(['age', 'gender'], axis=1)
df
输出
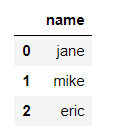
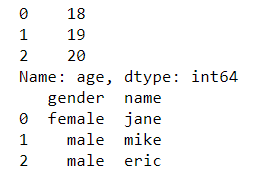
如果我们想获得删除后的列,可以使用pop函数
age = df.pop('age')
print(age)
print(df)
输出
切片
创建DataFrame
df = pd.DataFrame({'name':['jane', 'mike', 'eric'],
'gender': ['female', 'male', 'male'],
'age': [18, 19, 20]}, index=['a', 'b', 'c'])
df.head()
输出

Pandas中切片常用的有loc[]和iloc[]函数。简单地说,loc根据标签来选择数据,而iloc根据索引来选择数据。
loc[]
选取第 0 行(a 对应的数据)
df.loc['a']
输出

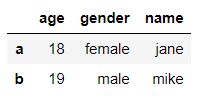
选择第 1 行和第 2 行数据
df.loc['a':'b']
输出
同时选择行列数据
df.loc['a':'b', 'age']
输出
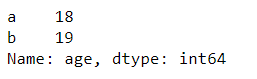
选择多行多列数据
df.loc['a':'b', ['age', 'name']]
输出
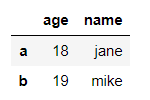
行也可以用列表来表示
df.loc[['a','b'], ['age', 'name']]
输出
iloc[]
iloc[]和loc[]用法类似,只是iloc使用索引来进行选择和切片。
使用同样的DataFrame
df = pd.DataFrame({'name':['jane', 'mike', 'eric'],
'gender': ['female', 'male', 'male'],
'age': [18, 19, 20]}, index=['a', 'b', 'c'])
df.head()
输出
选择第 0 行
df.iloc[0]
输出

选择第 0 行和第 1 行
df.iloc[0:2]
输出
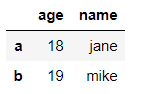
同时选择行和列
df.iloc[0:2, 0] #第0,1行,第0列(age)
输出
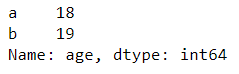
选取多行多列
df.iloc[0:2, [0,2]] #第0,1行,第0,2列(age, name)
输出
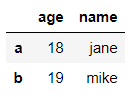
行索引也可以使用列表的形式
df.iloc[[0,1], [0,2]] #第0,1行,第0,2列(age, name)
输出
其他
还可以用类似访问普通数组的方式选择列
df[['name', 'gender']]
输出
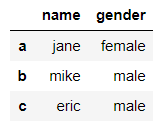
条件选择
创建DataFrame
df = pd.DataFrame({'name':['jane', 'mike', 'eric'],
'gender': ['female', 'male', np.nan],
'age': [18, 21, 20]}, index=['a', 'b', 'c'])
df
输出

单个条件
假如我们想选择年龄大于18岁的人,则可以使用条件选择
df.loc[df['age']>18]
输出
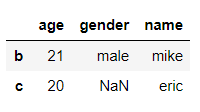
将年龄大于18的同学的性别改为"man"
df.loc[df['age']>18, 'gender'] = 'man'
df
输出
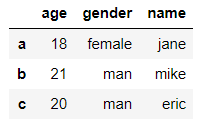
多个条件
假如我们想选择年龄小于20且性别为女的同学,则
df.loc[(df['age']<20) & (df['gender']=='female')]
输出

NaN
创建一个含有NaN的DataFrame
df = pd.DataFrame({'name':['jane', 'mike', 'eric'],
'gender': ['female', 'male', np.nan],
'age': [18, np.nan, 20]}, index=['a', 'b', 'c'])
df.head()
输出
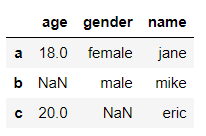
判断是否存在NaN
当我们拿到一份数据时,我们通常要判断数据是否有缺失,可以通过df.info()来判断
df.info()
输出
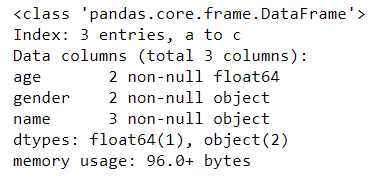
可以看到,数据共 3 行,但 age 列和 gender 列都只有 2 个数据对象。所以 age 列和 gender 列数据有缺失,各缺失 1 条数据。
还可以使用df.isnull()来判断
df.isnull()
输出
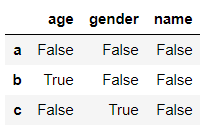
这样实际上是把每个元素是否为空都输出了出来,当数据量较大时,通过这种方法判断显然是不合理的,可以使用df.isnull().any()来判断
df.isnull().any()
输出

通过输出我们可以知道,age 列和 gender 列存在空值,而 name 列没有缺失值。
使用df.isnull().any()只能判断每列是否存在缺失值,而不能得出有多少缺失值。可以使用df.isnull().sum()来判断每列有多少缺失值
df.isnull().sum()
输出
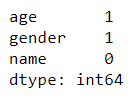
可以看到,age 列和 gender 列各有一个缺失值,而 name 列没有缺失值。
统计NaN的比例
NaN的比例可以然我们更直观的看到有多少缺失值
total = df.isnull().sum().sort_values(ascending=False)
percent = (df.isnull().sum()/df.isnull().count()).sort_values(ascending=False)
missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
missing_data.head()
输出
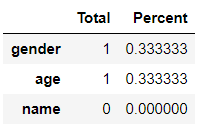
可以看到,age 列和 gender 列缺失值个数占总数的 33.3%.
缺失值的处理
当某列的缺失值较多时,可以直接将该列删除,可以使用上面的删除列的方法将对应的列删除。
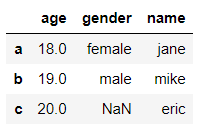
当某列的缺失值较少时,我们可以使用df.fillna()将缺失值填充,可以填充为该列其他非空值的平均值,中位数等
df['age'] = df['age'].fillna(df['age'].mean()) # 将age列中的缺失值填充为平均值
df
输出
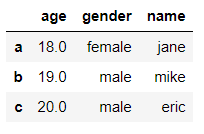
df['gender'] = df['gender'].fillna('male') # 将gender列中的缺失值填充为'male'
df
输出
年龄应该是整数,通过astype()来更改数据类型
df['age'] = df['age'].astype(int)
df
输出

连接concat
pd.concat可以将多个DataFrame连接成一个DataFrame。
首先创建两个DataFrame:df1,df2
df1 = pd.DataFrame({'name':['jane'],
'gender': ['female'],
'age': [18]})
df1
输出

df2 = pd.DataFrame({'name':['mike'],
'gender': ['male'],
'age': [19]})
df2
输出

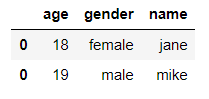
通过指定axis可以实现水平连接(axis=1)和垂直连接(axis=0)
df = pd.concat([df1, df2], axis=0) #垂直连接
df
输出
df = pd.concat([df1, df2], axis=1) #水平连接
df
输出
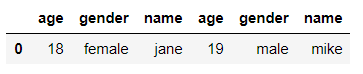
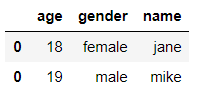
如果两个DataFrame的列名不同,那么连接后的DataFrame可能存在缺失值
df3 = pd.concat([df1, df2], axis=0)
df3
输出
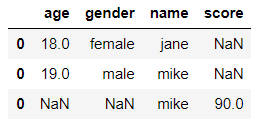
df4 = pd.DataFrame({'name':['mike'],
'score':[90]})
df4
输出

将 df3 和 df4 连接
df5 = pd.concat([df3, df4], axis=0)
df5
输出
合并merge
使用pd.merge将两个DataFrame合并起来
df3
输出

df4
输出

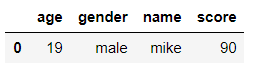
将 df3 和 df4 根据 name 列合并
df6 = pd.merge(df3, df4, on='name')
df6
输出

还可以使用下面这种方式
df7 = df3.merge(df4)
df7
输出
apply, applymap和map
我们可以通过apply,applymap和map使用函数来对DataFrame或者Series进行操作。这3中方法的区别在于:
- apply对整个DataFrame(以行或列为元素)进行操作
- applymap对整个DataFrame中的元素进行操作
- map对Series中的元素进行操作
apply
apply对整个DataFrame(以行或列为元素)进行操作。创建DataFrame
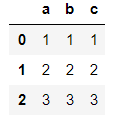
df = pd.DataFrame({'a': [1,2,3], 'b':[1,2,3], 'c':[1,2,3]})
df
输出
求df每列的和
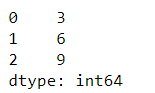
df.apply(np.sum, axis=0)
输出

求df每行的和
df.apply(np.sum, axis=1)
输出
使用自定义的lambda函数求和
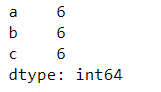
df.apply(lambda x:x.sum(), axis=0)
输出
使用自定义的函数求和
def my_sum(x):
return x.sum()
df.apply(my_sum, axis=0)
输出

applymap
applymap对整个DataFrame中的元素进行操作。创建DataFrame
df = pd.DataFrame({'a': [1,2,3], 'b':[1,2,3], 'c':[1,2,3]})
df
输出
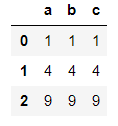
对df中的每个元素求平方
df.applymap(lambda x:x**2)
输出
map
map对Series中的每个元素进行操作。创建DataFrame
df = pd.DataFrame({'a': [1,2,3], 'b':[1,2,3], 'c':[1,2,3]})
df
输出
对第a列的数字进行平方
df['a'].map(lambda x:x**2)
输出


 浙公网安备 33010602011771号
浙公网安备 33010602011771号