Golang底层原理剖析之函数调用栈-栈帧布局与函数跳转
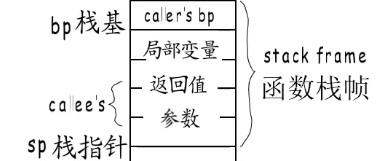
栈帧布局
我们按照编程语言的语法定义的函数,会被编译器编译为一堆机器指令,写入可执行文件,程序执行时,可执行文件被加载到内存,这些机器指令对应到虚拟地址空间中,位于代码段。

如果在一个函数中调用另一个函数,编译器就会对应生成一条call指令,程序执行到这条指令时,就会跳转到被调用函数处开始执行,而每个函数的最后都有一条ret指令,负责在函数结束后跳回到调用处,继续执行。
函数执行时需要有足够的内存空间,供函数存放局部变量,参数等数据,这段空间对应到虚拟地址空间的栈,栈是向下增长,分配给函数的栈空间,被称为栈帧,栈底被称为栈基bp,栈顶又叫栈指针sp

go语言函数栈帧布局是这样的,先是调用者函数栈基地址,接下来是局部变量,然后是调用函数的返回值和参数
函数跳转
call指令只做两件事
- 第一将下一条指定的地址入栈,这就是返回地址,被调用函数执行结束后会跳回到这里(从现象看,返回地址是被CALL指令压栈的,既不是调用者分配的,也不是被调用者分配的。逻辑上看,调用者不会访问栈上的返回地址以及位于返回地址之下的地方。但被调用者的视角看,从上到下依次是参数、返回地址、局部变量,所以应该算是被调用者的栈帧,也就是可以理解为被调用者栈帧第一个存的是return addr,第二个存的是调用者bp。)
- 第二,跳转到被调用函数的入口处开始执行
所有的函数的栈帧布局都遵循统一的约定,所以,被调用者是通过栈指针加上相应的偏移来定位到每个参数和返回值的

程序执行时,CPU用特定的寄存器来存储运行时bp与sp,同时也有指令指针寄存器用于存储下一条要执行的指令地址。
go语言的栈不是逐步扩张的,而是一次性分配,也就是在分配栈帧时,直接将栈指针移动到所需最大栈空间的位置,然后通过栈指针+偏移值这种相对寻址方式使用函数栈帧

之所以一次性分配,主要是为了避免栈访问越界。由于函数栈帧的大小,可以在编译时期确定,对于栈消耗较大的函数,go语言的编译器会在函数头部插入检测代码,如果发现需要进行“栈增长”,就会另外分配一段足够大的栈空间,并把原来栈上的数据拷贝过来,原来这段栈空间就被释放了。

接下来看看call指令和ret指令是怎样实现函数跳转与返回的
一个函数A在a1处调用b1处的函数B,跳转前寄存器和栈的情况是这样的

然后到call指令这里,它的作用有两点,第一,把下一条指令执行地址a2入栈保存起来,第二,跳转到指令执行地址b1处,call指令就结束了。

函数B开始执行,先把sp向下移动24字节,为自己分配足够大的栈帧,所以栈指针移到s7,接下来是b2这条指令,要把调用者栈基(caller bp)存到sp+16的地方,接下来b3把sp+16存入栈基寄存器,接下来就是执行函数B剩下的指令了

在ret指令之前,编译器还会插入两条指令,第一条指令恢复调用者A的栈基地址,它之前被存储在sp+16字节这里,这就是为什么栈帧布局第一条就是caller’s bp的原因,第二条指令释放自己的栈帧空间,分配时向下移动多少,释放时就向上移动多少

然后就到ret指令了,它的作用也有两点,第一弹出call指令压栈的返回地址,第二,指令指针寄存器跳转到这个返回地址,ok现在可以从a2这里继续执行了
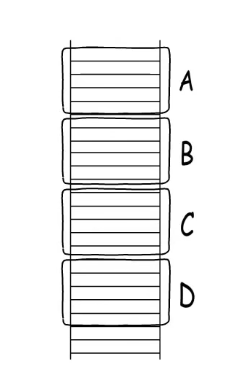
简单来说,函数通过call指令实现跳转,而每个函数开始时会分配栈帧,结束前又会释放自己的栈帧,ret指令又会把call恢复到call之前的样子,通过这些指令的配合能够实现函数的层层嵌套。如果函数A嗲用B,B调用C,C调用D,就会形成这样的栈
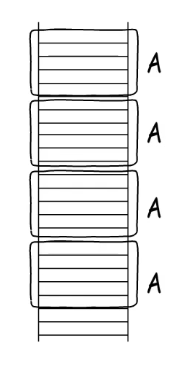
如果每次调用的都是A,就是递归调用栈了

