
nodejs实现分段加速下载
node如何下载文件?
用 axios 就行啦!
简单版如下:
const axios = require('axios')
const fs = require('fs')
function formatHeaders (headers) {
return Object.keys(headers).reduce((header, name) => {
header[String(name).toLowerCase()] = headers[name]
return header
}, {})
}
async function download(url, filePath) {
let response = await axios({
timeout: 60000,
method: 'get',
responseType: 'stream', // 请求文件流
headers: {
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Pragma': 'no-cache'
},
url
})
let responseHeaders = formatHeaders(response.headers)
let fileLength = Number(responseHeaders['content-length'])
let readerStream = response.data.pipe(fs.createWriteStream(filePath))
// 监听 WraiteStream 的 finish 事件
readerStream.on('finish', () => {
if (fileLength === readerStream.bytesWritten) {
// 下载成功
}
})
readerStream.on('error', (err) => {
// 下载失败
})
}
大功告成!
。。。

等下,分段下载怎么搞?
分段下载,需要用到请求的头信息字段 Range。MDN描述摘抄如下:
Range 是一个请求首部,告知服务器返回文件的哪一部分。在一个 Range 首部中,可以一次性请求多个部分,服务器会以 multipart 文件的形式将其返回。如果服务器返回的是范围响应,需要使用 206 Partial Content 状态码。假如所请求的范围不合法,那么服务器会返回 416 Range Not Satisfiable 状态码,表示客户端错误。服务器允许忽略 Range 首部,从而返回整个文件,状态码用 200 。
语法如下:
Range: <unit>=<range-start>- Range: <unit>=<range-start>-<range-end> Range: <unit>=<range-start>-<range-end>, <range-start>-<range-end> Range: <unit>=<range-start>-<range-end>, <range-start>-<range-end>, <range-start>-<range-end>
如果你看视频的时候注意一下视频的请求头,你会发现请求信息是这样的:
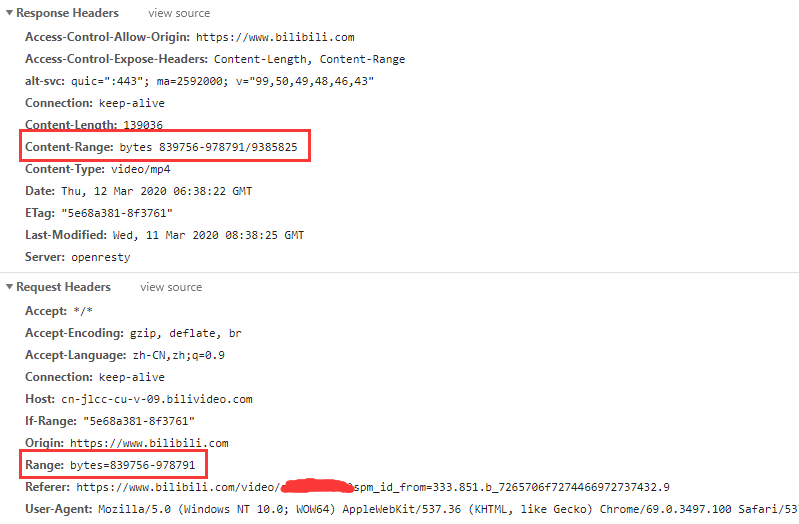
content-range 字段描述如下:
在HTTP协议中,响应首部 Content-Range 显示的是一个数据片段在整个文件中的位置。
语法
Content-Range: <unit> <range-start>-<range-end>/<size> Content-Range: <unit> <range-start>-<range-end>/* Content-Range: <unit> */<size>
so,要实现分段下载,用range字段分割就行啦!
一顿操作猛如虎:
先拿到请求的文件的大小,就是 content-range 字段后面的 size 那一截
async function getResHeader(url) { try { let response = await axios({ timeout: 60000, method: 'get', headers: { 'Cache-Control': 'no-cache', 'Connection': 'keep-alive', 'Pragma': 'no-cache', 'Range': 'bytes=0-1' }, url }) let headers = formatHeaders(response.headers) if (headers && headers['content-range']) { // 根据 content-range 获取文件大小 return Number(headers['content-range'].split('/').pop()) } return 0 } catch (e) { throw e } }
再根据返回的文件大小进行分块,这里我们就先预设 4M 吧,小于4M的就不分块了:
// 长度分割方法 function splitBlock(blockSize, fileLength) { let blockList = [] let block = 0 while (block < fileLength) { let end = block + blockSize - 1 if (end > fileLength) { end = fileLength } blockList.push({start: block, end: end}) block += blockSize } return blockList } let fileLength = await getResHeader(url) let fileBuffer = null // 分块大小 4M let blockSize = 1024 * 1024 * 4; if (fileLength > blockSize) { // 如果超过 4M 则分割文件 fileBuffer = splitBlock(blockSize, fileLength) } if (!Array.isArray(fileBuffer) || !fileBuffer.length) { // 小于 4M 的文件直接获取全部长度 fileBuffer = [{start: 0, end: fileLength}] }
然后拿着分段的信息去下载文件:
fileBuffer.forEach(({start, end}) => {
try {
let header = Object.assign({}, {
'etag': headers['etag'],
'Content-Type': headers['content-type'],
'Range': 'bytes=' + start + '-' + end
})
download(url, filePath, header)
} catch (e) {
throw e
}
})
键盘一顿啪啪啪,一看下载报错了。。。
createWriteStream 写入失败?哦,不能同时写入文件。。。那我就换个方法吧。
先把 download 方法改一改,改成直接返回buffer:
async function download(url, defaultHeaders) { let headers = Object.assign({ 'Cache-Control': 'no-cache', 'Connection': 'keep-alive', 'Pragma': 'no-cache' }, defaultHeaders) let response = await axios({ timeout: 60000, method: 'get', responseType: 'arraybuffer', // 改成获取文件 ArrayBuffer headers, url }) return response.data }
再把分段请求回来的数据组装上:
Promise.all(fileBuffer.map(({start, end}) => {
let header = Object.assign({}, {
'etag': headers['etag'],
'Content-Type': headers['content-type'],
'Range': 'bytes=' + start + '-' + end
})
return download(url, filePath, header)
})).then(resultList => {
resultList.forEach(data => {
fs.appendFileSync(filePath, data)
})
})
耶!成功了?
下几个大文件试试。。。
蓝屏了。。。

看来还是只能用 createWriteStream 来写入文件了,不然我这破电脑内存根本不够用啊。
可是 stream 谁知道他会按什么顺序下载完成啊,还组装个锤子,写入的时候还占着文件,没法搞啊。
既然写入的时候占着文件,那我每个分段都写入一个文件不就好了嘛,真是天才想法啊

先引入 fs-extra ,这样文件操作会简单一点,在下载目录下新加一个缓存目录用来存放临时文件,等所有文件下载完成,再组装起来
先改造download方法,下载 stream流,并且只有在文件片段下载完成后才返回:
async function download(url, tempPath, headers) { try { let response = await axios({ timeout: 60000, method: 'get', responseType: 'stream', headers: Object.assign({ 'Cache-Control': 'no-cache', 'Connection': 'keep-alive', 'Pragma': 'no-cache' }, headers), url }) let responseHeaders = formatHeaders(response.headers) let fileLength = Number(responseHeaders['content-length']) return new Promise((resolve, reject) => { let readerStream = response.data.pipe(fs.createWriteStream(tempPath, {start: 0, flags: 'r+', autoClose: true})) readerStream.on('finish', () => { // 如果下载的片段长度跟分割的长度一致则下载完成 if (fileLength === readerStream.bytesWritten) { resolve() } else { reject(new Error('下载失败')) } }) readerStream.on('error', (err) => { reject(err) }) }) } catch (e) { throw e } }
并行下载所有片段:
async function multiThreadDownload (fileBuffer, url, fileName, filePath, headers) { // 生成临时文件目录 let downloadList = fileBuffer.map(({start, end}) => { // 将临时文件放到下载的同级目录下的.download_cache 文件夹 let tempPath = path.join(filePath, '../.download_cache/' + fileName + '/' ) // 根据每一段文件的长度命名临时文件 let tempFilePath = path.join(tempPath, start + '-' + end + '.tmp') return { start, end, tempPath, tempFilePath } }) await Promise.all(fileBuffer.map(async ({start, end, tempFilePath, tempPath}) => { // 创建临时文件 fse.ensureDirSync(tempPath); // 判断临时文件是否存在 if (fs.existsSync(tempFilePath)) { let fileLength = await new Promise((resolve, reject) => { fs.readFile(tempFilePath, (err, data) => { if (err) { reject(err) } resolve(data.length) }) }) // 如果临时文件存在则直接返回,不再进入下载 if (fileLength >= end - start) { return Promise.resolve() } } // 针对每一段文件创建临时文件 fs.appendFileSync(tempFilePath, new Uint8Array(0)) try { let header = Object.assign({}, { 'etag': headers['etag'], 'Content-Type': headers['content-type'], 'Range': 'bytes=' + start + '-' + end }) return download(url, tempFilePath, header) } catch (e) { fse.removeSync(tempFilePath) throw e } })) // 所有片段下载完成后开始组装 // 创建文件写入流 let writeStream = fs.createWriteStream(filePath) for (let i = 0; i < downloadList.length; i++) { let tempFilePath = downloadList[i].tempFilePath await new Promise((resolve, reject) => { let readerStream = fs.createReadStream(tempFilePath) readerStream.pipe(writeStream, {end: false}) readerStream.on('end', () => { resolve() }) readerStream.on('error', (err) => { reject(err) }) }) } writeStream.end('down') // 写入完毕,删除临时文件和文件夹 fse.removeSync(downloadList[0].tempPath) }
组装完成!

完整demo地址:https://github.com/flicat/fast-bird-download


 浙公网安备 33010602011771号
浙公网安备 33010602011771号