一、MongoDB的应用场景及实现原理
二、MongoDB的常用命令及配置
三、手写基于MongoDB的ORM框架
四、基于MongoDB实现网络云盘实战
五、MongoDB 4.0新特性
一、MongoDB 中的应用场景及设计原理
MongoDB 是一个基于分布式文件存储的数据库。由 C++语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。 MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。在这里我们有必要先简单介绍一下非关系型数据库(NoSQL)
1.1 、什么是 NoSQL
NoSQL,指的是非关系型的数据库。NoSQL 有时也称作 Not Only SQL 的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。NoSQL 用于超大规模数据的存储。(例如谷歌或Facebook 每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
1.2 、关系型数据库 PK 非关系型数据库
|
关系型数据库 |
NoSQL 数据库 |
|
高度组织化结构化数据 |
代表着不仅仅是 SQL |
|
结构化查询语言(SQL) |
没有声明性查询语言 |
|
数据和关系都存储在单独的表中 |
没有预定义的模式 |
|
数据操作语言,数据定义语言 |
键-值对存储,列存储,文档存储,图形数据库 |
|
严格的一致性 |
最终一致性,而非 ACID 属性 |
|
基础事务 |
非结构化和不可预知的数据 |
|
|
CAP 定理 |
|
|
高性能,高可用性和可伸缩性 |
1.3 、NoSQL 数据库分类
|
类型 |
典型代表 |
特点 |
|
列存储 |
Hbase Cassandra Hypertable |
顾名思义,是按照列存储数据的。最大的特点是方便存储结构化和半结构化的数据,方便做数据压 缩,对针对某一列或者某几列的 |
|
|
|
查询有非常大的 IO 优势 |
|
文档存储 |
MongoDB CounchDB |
文档存储一般用类似 json 的格式存储,存储的内容是文档型的。这样也就有机会对某些字段建立索引,实现关系数据库的某些功 能。 |
|
Key-value 存储 |
Tokyo Cabinet/Tyrant Berkelery DB Memcache Redis |
可以通过 key 快速查询到其value 。一般来说, 存储不管value 的格式,照单全收。(Redis 包含了其他功能) |
|
图存储 |
Neo4J FlockDB |
图形关系的最佳存储。使用传统 关系数据库来解决的话性能低下,而且设计使用不方便。 |
|
对象存储 |
Db4o Versant |
通过类似面向对象语言的语法操作数据库,通过对象的方式存储 数据。 |
|
XML 数据库 |
Berkeley DB XML BaseX |
高效的存储XML 数据,并存储 XML 的 内 部 查 询 语 法 , 比 如 XQuery,Xpath。 |
1.4 、MongoDB 的数据结构与关系型数据库数据结构对比
|
关系型数据库术语/概念 |
MongoDB 术语/概念 |
解释/说明 |
|
Database |
Database |
数据库 |
|
Table |
Collection |
数据库表/集合 |
|
Row |
Document |
数据记录行/文档 |
|
Column |
Field |
数据列/数据字段 |
|
Index |
Index |
索引 |
|
Table joins |
|
表关联/MongoDB 不支持 |
|
Primary Key |
Object ID |
主键/MongoDB 自动将_id 设置为 主键 |
1.5 、MongoDB 中的数据类型
|
数据类型 |
说明 |
解释 |
举例 |
|
Null |
空值 |
表示空值或者未定义的 对象 |
{“x”:null} |
|
Boolean |
布尔值 |
真或者假: true 或者 false |
{“x”:true} |
|
Integer |
整数 |
整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
|
|
Double |
浮点数 |
双精度浮点值。 |
{“x”:3.14,”y”: 3} |
|
String |
字符串 |
UTF-8 字符串 |
|
|
Symbol |
符号 |
符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用 特殊符号类型的语言。 |
|
|
ObjectID |
对象 ID |
对象 ID。用于创建文档 的 ID。 |
{“id”: ObjectId()} |
|
Date |
日期 |
日期时间。用 UNIX 时 间格式来存储当前日期或时间。 |
{“date”:new Date()} |
|
Timestamp |
时间戳 |
从标准纪元开始的毫秒 数 |
|
|
Regular |
正则表达式 |
文档中可以包含正则表达式,遵循 JavaScript 的语法 |
{“foo”:/testdb/i} |
|
Code |
代码 |
可以包含 JavaScript 代码 |
{“x”:function() {}} |
|
Undefined |
未定义 |
已废弃 |
|
|
Array |
数组 |
值的集合或者列表 |
{“arr”: [“a”,”b”]} |
|
Binary Data |
二进制 |
用于存储二进制数据。 |
|
|
Object |
内嵌文档 |
文档可以作为文档中某 |
{“x”:{“foo”:”bar”}} |
|
|
|
个 key 的 value |
|
|
Min/Max keys |
最小/大值 |
将一个值与 BSON(二进 制的 JSON)元素的最低值和最高值相对比。 |
|
1.6 、图解 MongoDB 底层原理
MongoDB 的集群部署方案中有三类角色:实际数据存储结点、配置文件存储结点和路由接入结点。
连接的客户端直接与路由结点相连,从配置结点上查询数据,根据查询结果到实际的存储结点上查询和存储数据。MongoDB 的部署方案有单机部署、复本集(主备)部署、分片部署、复本集与分片混合部署。混合的部署方式如图:
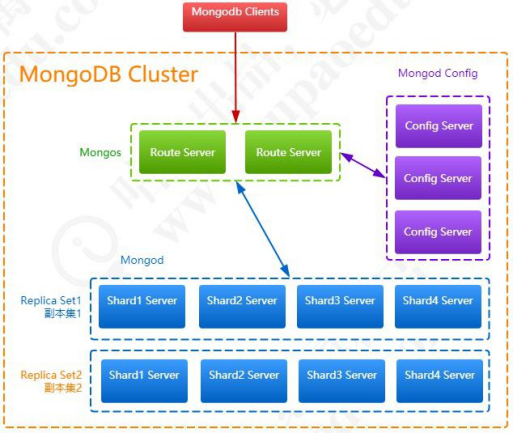
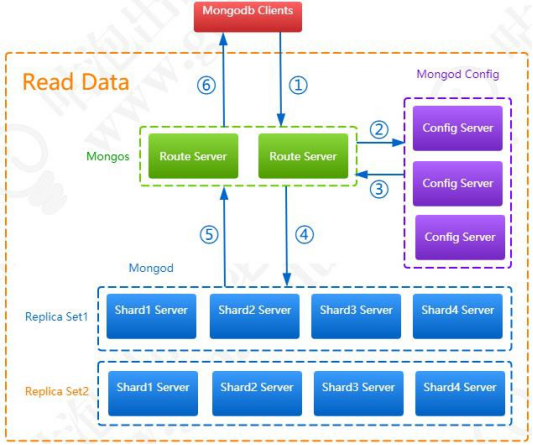
混合部署方式下向 MongoDB 写数据的流程如图:
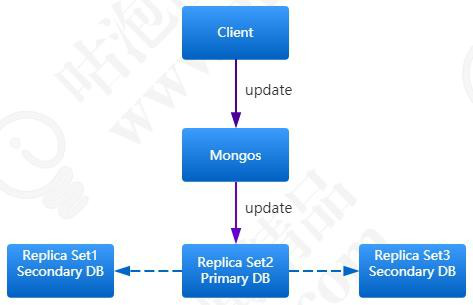
对于复本集,又有主和从两种角色,写数据和读数据也是不同,写数据的过程是只写到主结点中,由主结点以异步的方式同步到从结点中:
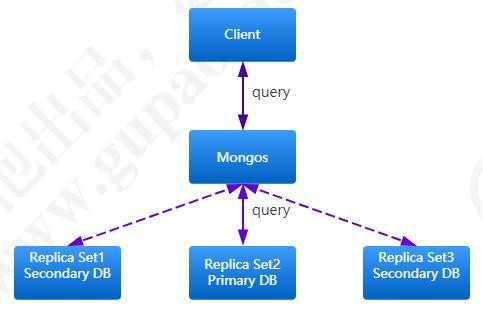
读数据则只要从任一结点中读取,具体到哪个结点读取是可以指定的:
对于 MongoDB 的分片,假设我们以某一索引键(ID)为片键,ID 的区间[0,50],划分成 5 个 chunk, 分别存储到 3 个片服务器中,如图所示:
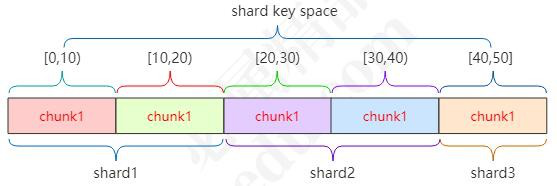
假如数据量很大,需要增加片服务器时可以只要移动 chunk 来均分数据即可。配置结点:
存储配置文件的服务器其实存储的是片键与 chunk 以及 chunk 与 server 的映射关系,用上面的数据表示的配置结点存储的数据模型如下表:
Map1
|
Key range |
chunk |
|
[0,10) |
chunk1 |
|
[10,20) |
chunk2 |
|
[20,30) |
chunk3 |
|
[30,40) |
chunk4 |
|
[40,50) |
chunk5 |
Map2
|
chunk |
shard |
|
chunk1 |
shard1 |
|
chunk2 |
shard1 |
|
chunk3 |
shard2 |
|
chunk4 |
shard2 |
|
chunk5 |
shard3 |
路由结点:
路由角色的结点在分片的情况下起到负载均衡的作用。1.7、MongoDB 的应用场景和不适用场景
1、适用场景
对于 MongoDB 实际应用来讲,是否使用 MongoDB 需要根据项目的特定特点进行一一甄别,这就要求我们对 MongoDB 适用和不适用的场景有一定的了解。
根据 MongoDB 官网的说明,MongoDB 的适用场景如下:
1) 网站实时数据:MongoDB 非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
2) 数据缓存:由于性能很高,MongoDB 也适合作为信息基础设施的缓存层。在系统重启之后,由 MongoDB
搭建的持久化缓存层可以避免下层的数据源过载。
3) 大尺寸、低价值数据存储:使用传统的关系型数据库存储一些数据时可能会比较昂贵,在此之前,很多时候程序员往往会选择传统的文件进行存储。
4) 高伸缩性场景:MongoDB 非常适合由数十或数百台服务器组成的数据库。MongoDB 的路线图中已经包含对 MapReduce 引擎的内置支持。
5) 对象或 JSON 数据存储:MongoDB 的 BSON 数据格式非常适合文档化格式的存储及查询。
2、不适用场景
了解了 MongoDB 适用场景之后,还需要了解哪些场景下不适合使用 MongoDB,具体如下:
1)高度事务性系统:例如银行或会计系统。传统的关系型数据库目前还是更适用于需要大量原子性复杂事务的应用程序。
2)传统的商业智能应用:针对特定问题的 BI 数据库会对产生高度优化的查询方式。对于此类应用, 数据仓库可能是更合适的选择。
3)需要复杂 SQL 查询的问题。
相信通过上面的说明,你已经大致了解了 MongoDB 的使用规则,需要说明一点的是,MongoDB 不仅仅是数据库,更多的使用是将 MongoDB 作为一个数据库中间件在实际应用中合理划分使用细节,这一点对于 MongoDB 应用来讲至关重要!
纲要
MySQL
memory 内存引擎
NoSQL最大的特点:
1、默认支持分布式(内置分布式解决方案)
2、高性能,高可用性和可伸缩性
在NoSQL界,
MongoDB是一个最像关系型数据库的非关系型数据库
MongoDB应用场景
适用范围
1)网站实时数据: 例如:日志、Timeline、用户行为(代替方案:用日志)
2)数据缓存:缓存的数据,它一定是临时的 (关系型数据有一份已经持久化)
3)大尺寸、低价值数据存储: 搜索引擎的图片文件、视频文件(结构化),
一份存磁盘、一份存Mongo
4)高伸缩性场景:机器可以任意的增减
5)对象或JSON数据存储: 完全可以选择用Redis
不适用范围
1)高度事务性系统: 例如:金融系统的核心数据
高机密的用户数据(只能选择传统关系型数据库)
2)传统的商业智能应用:结构化查询要求非常高,经常做关联查询统计
(如果都是单表查询,用Java程序来实现关联)
Map,List (id_az_a)
MongoDB 4.0 支持事务操作(分布式事务的一种解决方案)
学习,不要老是找乱七八糟的博客
看不懂,给大家补软肋(新东方英语)
来自文艺界
勤奋、思考(万变不离其宗)
mongo 客户端
mongos 路由器
mongod 数据存储
zookeeper 分布式协调(路由)
把整个集群下面的所有已经注册机器的信息,人手持一份(区块链)
leader选取(leader不存配置信息,监控)
套路差不多
mongos,协调所有的mongod
统一管理配置中心
Master
副本集,认为就是一台存储数据的机器(mongo),
一个副本集数据一定是一个完整的整体
Image镜像
高可用:把一个服务部署多份(一台坏了,另一台可以顶上)
M-S
M-A-S
数据热点:
数据的平均存储问题(传一个视频,切成四份分别存到四张表里面去)
每张表存储的极限(遇到瓶颈)
类似于Map(拆分)Reduce(归并)(Hadoop里面)
怎么切,那是策略
P2P?原来要1个小时,只需要1分钟
分表、分区?
微观的维度(你看不到的一个维度)
chunk(块)-->shard(片) --> Replica Set(副本) --> Data(数据)
宏观的维度(你能看到的)
Field(字段) --> Document(文档) --> Collection(集合) --> DataBase(数据库)
mongodb自3.0版本后新增了wiredTiger的数据存储引擎, 3.2版本后默认采用的wiredTiger, 但是linux32bit(注意自己linux的系统位数)不支持此引擎
既然默认的wiredTiger不能用, 那么采用指定引擎为mmapv1吧
mongod --dbpath=/root/mongodb/data --logpath=/root/mongodb/log/mongodb.log --storageEngine=mmapv1
后台启动
mongod --dbpath=/root/mongodb/data --fork --logpath=/root/mongodb/log/mongodb.log --storageEngine=mmapv1
本地客户端连接linux的mongoDb服务 mongo 192.168.25.128

 浙公网安备 33010602011771号
浙公网安备 33010602011771号