面试官问我redis数据类型,我回答了8种
面试官:小明呀,redis 有几种数据结构呀?
小明:8 种
面试官:那你说一下分别是什么?
小明:raw,int,ht,zipmap,linkedlist,ziplist,intset,skiplist,embstr
面试官:额,你在说什么?
小明:在回答你的问题呀,这个问题我可是有过研究的,不会错的
面试官:好吧,今天的面试先到这里,你回去等通知吧
小明:...
上面发生的对话,到底是面试官有问题,还是小明有问题呢?其实是都有问题的,面试官的提问不准确,小明的回答也不准确。
但可以看出,面试官的水平一般,因为听到这些名词并不知道小明说的是 redis 底层的编码类型,进而错失了深入挖掘小明技术潜力的机会。而小明也有些自作聪明,忽略了面试官想考察的知识点,把自己最近看的一些皮毛拿出来秀了秀,结果导致了一场误会。
就着上面这个引子,我们本篇文章就来聊聊,redis 中的数据结构那些事。
redis 源码选取的版本: 3.0.0
本篇文章的目标:知道 redis 的编码类型这个概念,并按照源码级的深度去理解为什么要设置不同的编码类型,但不会过多展开各种底层数据结构的细节
redis 的对象类型与编码类型
redis 的对象类型,就是面试中常考的 redis 数据类型有哪些 这个问题所问的准确说法,这个对于我们这些只会面试不会开发的程序员来说,简直再熟悉不过啦,就是字符串、哈希、列表、集合、有序集合,这个在 redis 源码中能找到准确的定义:
redis.c
/* Object types */
#define REDIS_STRING 0
#define REDIS_LIST 1
#define REDIS_SET 2
#define REDIS_ZSET 3
#define REDIS_HASH 4
好多人对 redis 数据结构的理解可能就止步于此了,但其实这只是 redis 对外暴露的抽象结构,其底层实现要看其编码类型来决定使用该编码类型对应的数据结构。
如果一个对象类型只有一种底层数据结构的实现方式,那么这个编码类型就完全多余了,早期的 redis 的确没有这个概念。但后来为了优化性能,一种对象类型可能对应多种不同的编码实现,于是乎关于 redis 底层数据结构的知识点,就开始复杂起来了。编码类型在 redis 源码中也有准确定义:
redis.c
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define REDIS_ENCODING_RAW 0 /* Raw representation */
#define REDIS_ENCODING_INT 1 /* Encoded as integer */
#define REDIS_ENCODING_HT 2 /* Encoded as hash table */
#define REDIS_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define REDIS_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */
#define REDIS_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define REDIS_ENCODING_INTSET 6 /* Encoded as intset */
#define REDIS_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define REDIS_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
其实我们不用寻找任何额外的二手资料来解释编码类型的作用,直接看源码中的英文注释即可。
对象编码(编码类型):有些对象类型如字符串、哈希,其内部实现可以有多种方式,一个 redis 对象的 encoding 字段可以设置下面几个值来表示这个对象的底层编码类型
同一个对象类型,可以有不同的编码类型作为底层实现。而同一种编码类型,也可以支持上层的多种对象类型。他们的关系如下:
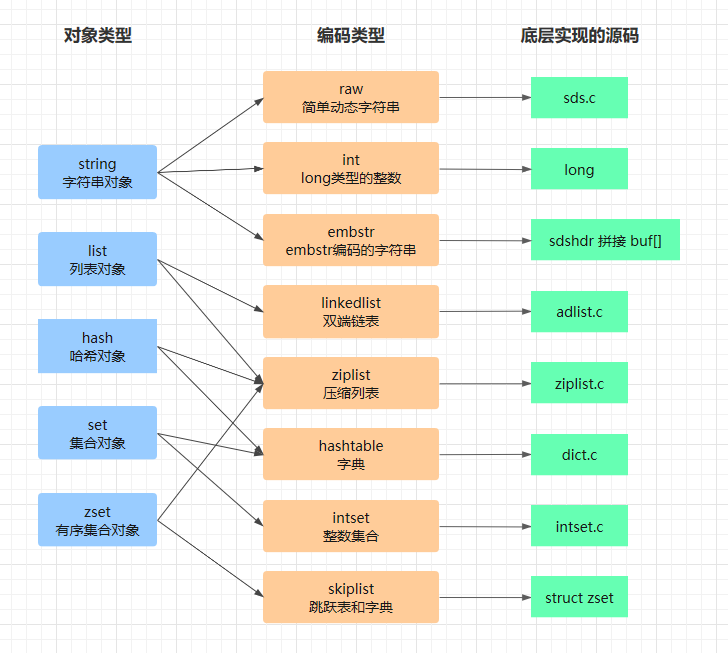
读到这里你一定有至少三个疑问:
- 为什么一种对象类型要对应多种编码类型,是为了解决什问题?
- redis 怎么知道什么时候该用这种编码类型,什么时候该用那种编码类型呢,并且编码类型可以随时改变么?
- 各种编码类型的实现原理是什么?(本章不做重点,会贯穿全文介绍一些基本思想,具体的各种实现会在其他篇章专门讲解)
别急,这一部分只是让你知道,redis 面对使用者暴露的只是一个抽象的数据结构,并不代表其底层的具体实现。接下来带你慢慢深入。
为什么一种对象类型要对应多种编码类型
写 redis 的大牛也是程序员,总不能他给自己增加了代码的复杂性,又对性能提升毫无帮助吧?毕竟 redis 这种中间组件必须以性能来取胜同类产品。没错,就是为了 性能提升。
直观感受编码类型的不同
首先我们来直观感受一下同一对象对应不同编码类型这一场景,这里用到了 object encoding xxx 这个 redis 命令来查看某一个 key 其 value 对象所使用的编码类型
127.0.0.1:6379> set number 100
OK
127.0.0.1:6379> object encoding number
"int"
127.0.0.1:6379> set number "100"
OK
127.0.0.1:6379> object encoding number
"int"
127.0.0.1:6379> set number abc
OK
127.0.0.1:6379> object encoding number
"embstr"
127.0.0.1:6379> set number aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
OK
127.0.0.1:6379> object encoding number
"raw"
127.0.0.1:6379> set number 9999999999999999999999999
OK
127.0.0.1:6379> object encoding number
"embstr"
127.0.0.1:6379> set number 99999999999999999999999999999999999999999999999999999999999999
OK
127.0.0.1:6379> object encoding number
"raw"
我们用我们最常使用的字符串做了测试,观察到其编码类型随着我设置的 value 值不同而改变,我整理了如下表格来表示上面的测试结果
| value | 编码类型 |
|---|---|
| 100 | int |
| "100" | int |
| abc | embstr |
| aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa | raw |
| 9999999999999999999999999 | embstr |
| 99999999999999999999999999999999999999999 | raw |
当然,我是因为知道字符串的编码类型的条件,踩专门选取了这些有代表性的值进行测试,我们可以总结出一个规律
- 不论是 100 还是 "100",编码类型都是 int,说明 redis 在判断是否可以用整数这个编码类型表示对象的时候,就只是看这个值是否能转换成一个整数
- 比较短的字符串 abc 被编码为 embstr,比较长的字符串 aaaaaaa..a 被编码为 raw,说明长短字符串的编码类型不一样,由此可以猜测 redis 可能是对短的字符串进行了存储上的优化策略(当然目前只是合理猜测,还有可能是对长字符串进行了某种优化)
- 整数 999...9 和更长的整数 9999999...9 也都被转换成了相应的表示字符串的类型,说明可以用整数编码类型表示的值,是有一定大小限制的
redis 对字符串编码类型的优化浅析
上面的实验我们了解到,字符串对象的编码类型确实有三种:int,raw,embstr。
int 类型分析起来没什么意思,想想就知道肯定是能用整型存储的,尽量用整型存储,一定比字符串方式更节省空间嘛。下面我们分析一下,长字符串和短字符串的编码类型做了区分,这是为什么呢?
不只是字符串类型,包括哈希、列表这些对象类型,都是用一个统一的结构体 redisObject 来表示的。他的结构如下:
redis.h
typedef struct redisObject {
unsigned type:4; // 对象类型
unsigned encoding:4; // 编码类型
void *ptr; // 值的指针
...(省略一些不重要的字段)
} robj;
占了 4 位的 type 表示 对象类型(5 种那个),同样占了 4 位的 encoding 字段表示 编码类型(8 种那个),指针字段 ptr 表示实际值的 内存地址。
如果该对象的编码类型为整数(encoding=REDIS_ENCODING_INT),那么这个 ptr 指向的将会是一个 long 类型的变量。
util.c
if (!string2ll(s,slen,&llval))
return 0;
...
*lval = (long)llval;
return 1;
object.c
...
o->ptr = (void*) value;
如果该对象的编码类型为 raw 或者 embstr,那么这个 ptr 指向的将会是一个 sdshdr 结构的变量
sds.h
struct sdshdr {
unsigned int len; // 字符串长度
unsigned int free; // buf空闲数
char buf[]; // 字符数组
};
既然都是指向同一个结构,那是怎么优化的呢?那就得进入如下两个方法具体看看了
object.c
robj *createStringObject(char *ptr, size_t len) {
if (len <= 39)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}
你看,这段代码非常清晰,字符串长度 <=39 时,就创建 embstr 类型的字符串对象,否则创建 raw 类型的字符串对象。那么这两个创建方式的区别,一定就隐藏在这两个方法里,我们点进去!
embstr 类型
robj *createEmbeddedStringObject(char *ptr, size_t len) {
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr)+len+1);
struct sdshdr *sh = (void*)(o+1);
o->type = REDIS_STRING;
o->encoding = REDIS_ENCODING_EMBSTR;
o->ptr = sh+1;
... (一些赋值操作)
return o;
}
raw 类型
robj *createRawStringObject(char *ptr, size_t len) {
return createObject(REDIS_STRING,sdsnewlen(ptr,len));
}
sds sdsnewlen(const void *init, size_t initlen) {
...
struct sdshdr *sh = zmalloc(sizeof(struct sdshdr)+initlen+1);
...
}
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = REDIS_ENCODING_RAW;
o->ptr = ptr;
...(一些赋值操作)
return o;
}
对于阅读源码比较多的同学,可能立刻就察觉到了他们的区别。其实很简单,就是 raw 类型这种方式,为 redisObject 和 sdshdr 结构分别申请了内存空间,而 embstr 只申请了一次内存空间,然后将这两个结构紧挨着放。除此之外没有其他任何区别了。直观图如下(图画反了,不想改了哈哈哈):
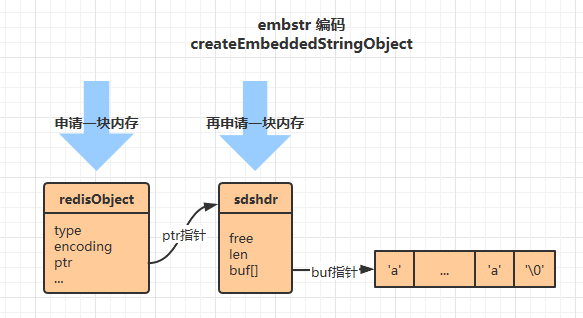
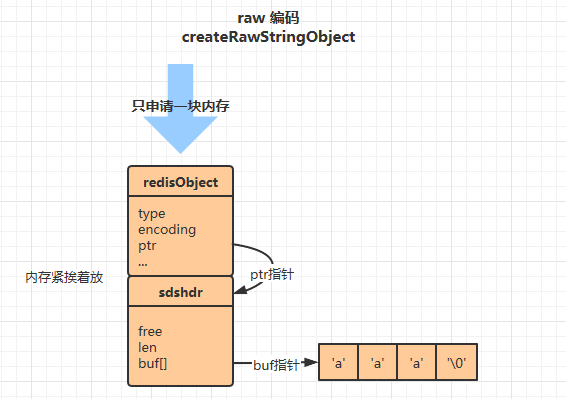
看到这,一切就都解释通了,非常简单,就只是申请内存这一步的区别而已。但对于我们这些什么简单的事情都要包装成高端大气话术的程序员来说,还是要想办法装一下,我们总结出使用 embstr 编码相比于 raw 编码的好处:
- embstr 只申请了一次内存,而 raw 需要申请两次,因此节约了一次申请内存的消耗
- 释放 embstr 只需要释放一次内存,而 raw 需要两次,因此节约了一次释放内存的消耗
- embstr 的 redisObject 和 sdshdr 放在一块连续的内存里,因此更能利用 缓存 带来的优势
怎么样,源码级的理解,加上迷倒面试官的总结话术,够意思吧。
不同编码类型的条件
上个部分我们通过字符串,观察了不同的编码类型,也理解了为什么要有不同的编码类型的实现。接下来我们总结下其他的对象与编码类型,原理就不深入源码分析了,和字符串的基本思想是一样的。
字符串的编码类型
- int:8 个字节的长整型
- embstr:小于等于 39 字节的字符串
- raw:大于 39 字节的字符串
哈希的编码类型
- ziplist:元素个数小于 512,且所有值都小于 64 字节
- hashtable:除上述条件外
列表的编码类型
- ziplist:元素个数小于 512,且所有值都小于 64 字节
- hashtable:除上述条件外
集合的编码类型
- intset:元素个数小于 512,且所有值都是整数
- hashtable:除上述条件外
有序集合的编码类型
- ziplist:元素个数小于 128,且所有值都小于 64 字节
- hashtable:除上述条件外
由于不展开讲解,纯记忆的东西我觉得用最干净的办法描述给大家即可,无多余部分。具体数据结构的细节,我会用其他文章来讲解。
此时,经过一番修炼的小明,再次遇到了一位专业的面试官
专业的面试官:小明呀,redis 有几种数据结...
进化的小明:面试官面试官,你这个问题分两种情况,redis 的对象类型,也就是我们常说的对外暴露的数据类型,有 5 种,分别是.... 底层对应的编码类型,在 3.0.0 源码中有 8 种,分别是....
专业的面试官:谁让你抢答了?
进化的小明:...
专业的面试官:行了,今天的面试先到这里,你回去等通知吧
进化的小明:...
完
公众号 - 低并发编程


 浙公网安备 33010602011771号
浙公网安备 33010602011771号