
EF查询百万级数据的性能测试--单表查询
一、起因
个人还是比较喜欢EF的,毕竟不用写Sql,开发效率高,操作简单,不过总是听人说EF的性能不是很好,也看过别人做的测试,但是看了就以为真的是那样。但是实际上到底是怎么样,说实话我真的不知道。我只知道选什么的框架是基于实际情况的,博主在一个创业公司上班,选的就是EF框架,刚做了一个项目,数据也就几万不到,感觉性能没那么差劲。于是,就想多弄点数据测试一下。再说一遍,本着 求真务实的方针,是针对现实中的业务需求来测试的,不是来单比性能的。你要是做个ERP系统,都去考虑千万级并发的架构,那当我没说。毕竟不是基于实际项目的框架选择都是耍流氓。
二、声明
基于实际的项目,考虑到博主一般的遇到的上线项目对于数据的增删改操作时,操作的数据一般都是一个,两个,多了有十几个,对于一下同时提交几十个数据进行增删改的,原谅博主还没有见过,更有甚者,提交几百个数据进行增删改,博主想也是没有想过。但是在这个数量级下的增删改操作,我相信EF还是能够胜任的,所以本文不再测试EF的增删改性能,因为感觉完全能够满足一般项目的需要。本文只测试EF的单表查询功能,之后有时间会做复杂的链接查询的测试。
三、测试条件


老百姓的配置,自己的工作电脑。
Sql Server 2012,Entity Framework 6.1.3。
四、测试数据
鉴于以前看过的测试都是两三个字段,且数据过于简单,以防有这方面的影响,又因为实际项目中的字段可能较多,而且数据量也比较复杂,就模拟了一个较为接近的数据表,再说一遍,本着求真务实的革命主义方针,针对现实的项目来测试。

数据量100W:

五、开始测试
做了一个WinForm的测试,界面如下:

1.进行Find测试,随机生成id,左边显示查询用时,先上代码。
1 private PortalContext db = new PortalContext(); 2 private int count = 0; 3 private TimeSpan ts = new TimeSpan(); 4 private void btnFind_Click(object sender, EventArgs e) 5 { 6 7 count++; 8 Random r = new Random(); 9 var id = r.Next(0, 1000000); 10 txtId.Text = id.ToString(); 11 12 Stopwatch sw = new Stopwatch(); 13 sw.Start(); 14 var user = db.Users.Find(id); 15 sw.Stop(); 16 17 txtUserInfo.Text = UserToString(user); 18 ts += sw.Elapsed; 19 string time = sw.Elapsed + "(" + sw.Elapsed.Seconds + "s" + sw.Elapsed.Milliseconds + "ms)"; 20 txtDisplay.AppendText("Find查询id(" + id + ")用时:" + time + Environment.NewLine); 21 txtData.Text = "执行" + count + "次,平均耗时" + new TimeSpan((ts.Ticks / count)); 22 }
结果如下:

可以看出,在100w数据的情况下,利用Find根据主键id查询根本无压力,至于第一次很长时间,应该是连接数据花费了一些时间。
2.进行Where测试,代码如下。
1 private void btnWhere_Click(object sender, EventArgs e) 2 { 3 4 5 bool[] valids = new bool[] { false, true }; 6 string[] works = new[] { "程序猿", "攻城狮", "产品汪", "键盘侠", "代码狗" }; 7 UserType[] userTypes = new[] { UserType.合作方, UserType.普通用户, UserType.律师 }; 8 Random r = new Random(); 9 10 int num = r.Next(0, 4680); 11 int num2 = r.Next(0, 4680); 12 13 int max = Math.Max(num, num2); 14 int min = Math.Min(num, num2); 15 16 bool isValid = valids[num % 2]; 17 string work = works[num % 5]; 18 UserType type = userTypes[num % 2]; 19 20 txtIsValid.Text = isValid.ToString(); 21 txtWork.Text = work; 22 txtUserType.Text = type.ToString(); 23 txtAmountMin.Text = min.ToString(); 24 txtAmountMax.Text = max.ToString(); 25 26 Stopwatch sw = new Stopwatch(); 27 sw.Start(); 28 var query = db.Users.Where(u => true); 29 var queryWhere = query.Where(u =>u.UserType == type &&u.IsValid == isValid && u.Work == work && (u.Amount >= min && u.Amount <= max)).Take(1000); 30 var list = queryWhere.ToList(); 31 sw.Stop(); 32 33 labelWhere.Text = string.Format("where(u=> u.UserType=={0} && u.IsValid =={1} && u.Work == {2} u.Amount >= {3} && u.Amount <={4}).Take(1000)", 34 type,isValid,work, min, max); 35 36 string time = sw.Elapsed + "(" + sw.Elapsed.Seconds + "s" + sw.Elapsed.Milliseconds + "ms)"; 37 txtDisplay.AppendText("Where查询到"+list.Count()+"条数据,用时:" + time + Environment.NewLine); 38 39 }
在这里用Where获取了前1000条数据,实际项目中基本不可能这样来,或者全部ToList()出来,考虑到项目中有些情况下确实需要全部ToList()出来一些数据,但是取1000条应该足够了,对于其他情况下来讲,这项测试没有太大的意义,我们等会看分页的性能。

附上一些全部ToList()出来时的测试:

当然实际是不可能这样玩的,也就看看,看了一下内存,3w多条数据也就30M左右。
附:Where查询的一些优化,其实这个之前是知道的,忘了往上贴了,谢谢@搵中求胜 博友的提醒,再次接着机会又测试了一下。
1.200w的数据(数据大才能体现出来效果),在没有AsNoTracking的情况下

2.加上了AsNoTracking(),一般我们的查询基本上不用跟踪只要数据就行了。可以看出来性能明显提高,同样的数据,将近提高了一般的性能。
1 var query = db.Users.AsNoTracking().Where(u => true); 2 var queryWhere = query.Where(u =>u.UserType == type &&u.IsValid == isValid && u.Work == work && (u.Amount >= min && u.Amount <= max));

3.还有,许多情况下我们不需要全部的数据,直接先用Select()选出来一些需要的字段,也会提高不少性能。
1 var query = db.Users.AsNoTracking().Where(u => true); 2 var queryWhere = query.Where(u =>u.UserType == type &&u.IsValid == isValid && u.Work == work && (u.Amount >= min && u.Amount <= max)) 3 .Select(u=>new 4 { 5 u.Id, 6 u.UserName 7 }); 8 var list = queryWhere.ToList();

3.Any,First ,Count的测试
代码都基本一样,这里只附上一些图片参考。
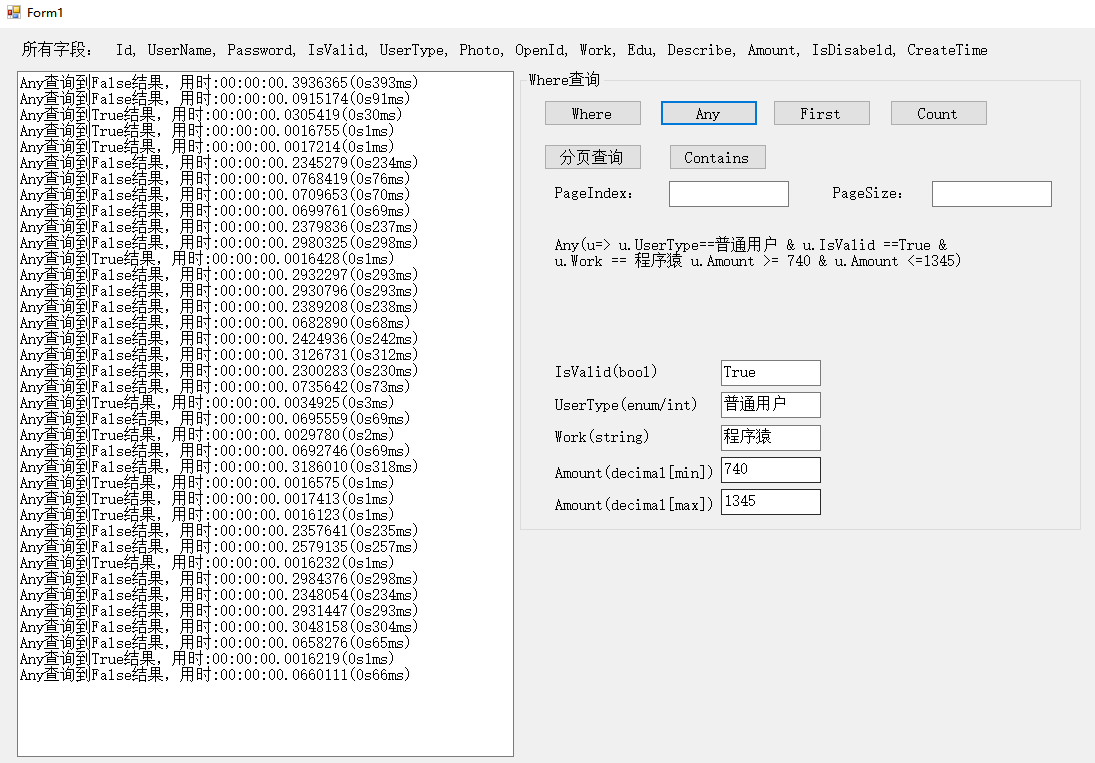


上边的都能查询存在不存在,但是相比来说,Any,First 对于存在的情况下,性能很好,而count对于不存在时性能却很好,我也不知道为什么的。感觉有时候真的可以用Count查询存在不存在的,毕竟平均效果好。PS:以前看一篇文章说Count比Any差了不知道多少倍,查询存在不存在推荐用Any。现在看来,也差不多啊。
4.分页查询。
从实际项目来看,用户在看分页数据时,一般都是翻看前10页左右,而且每页的数据量也大概在10-30个之间,太多了没必要。所有分页的pageIndex和pageSize都设置在了这些数据之间,可能页码的大小pageIndex,pageSize过大的时候也会影响性能,这个我们随后再加以测试。
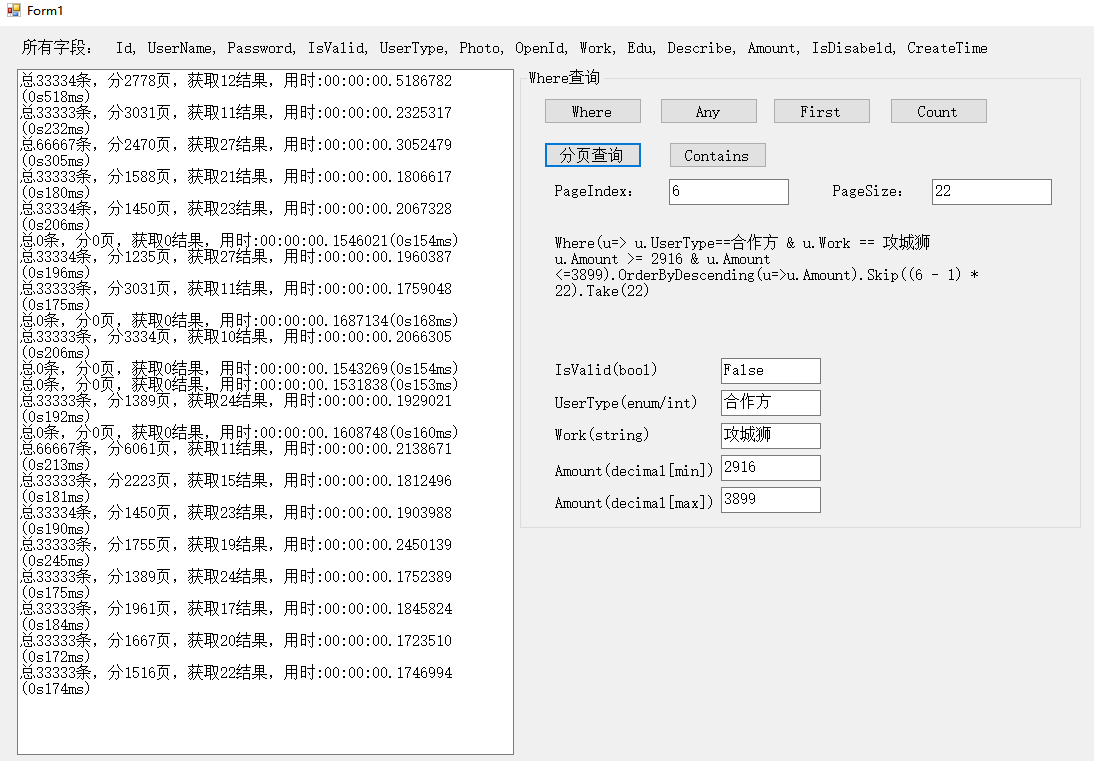
200ms左右吧,基本还说的过去,可能是在排序的问题上花费了太多的时间。
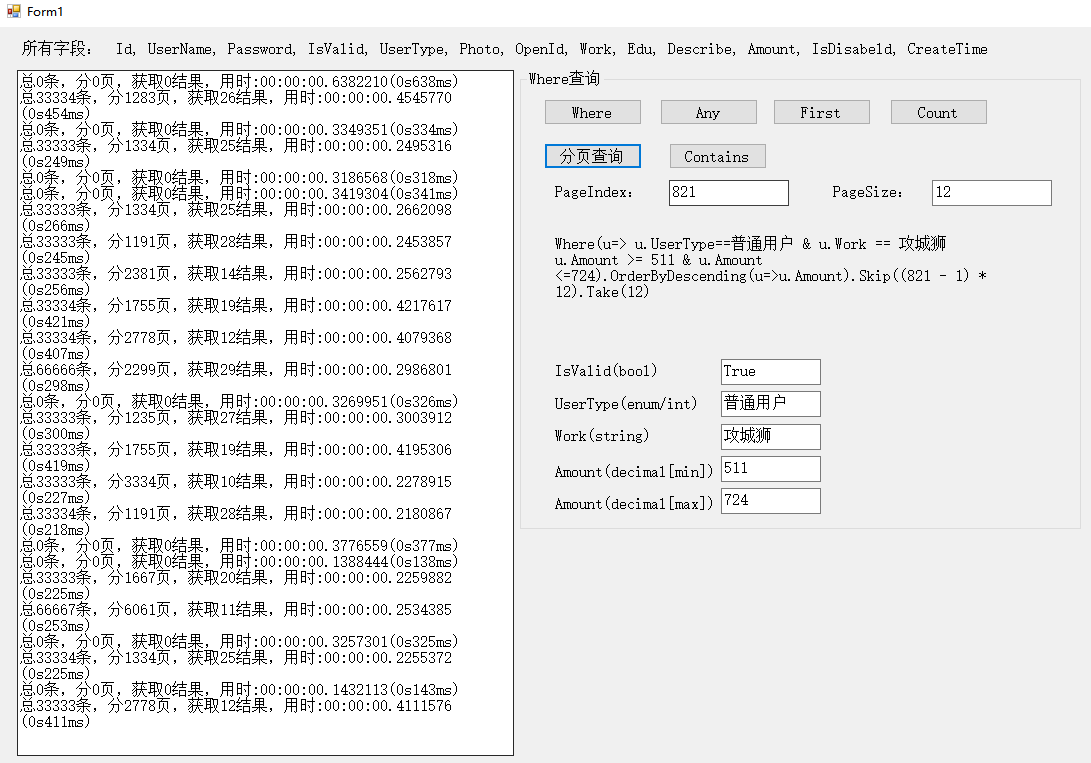
附上一张pageIndex比较大的测试结果(pageIndex在800-1000之间),果然页码比较大的时候花费时间变长了,pageSize就不用说了,肯定时间也会变长。
5.Contains查询
这里代码稍微做了改动,感觉也跟这个没关系
private void btnContains_Click(object sender, EventArgs e) { string[] usernames = new[] { "zhao", "wang", "li", "san", "zhaoliu" }; bool[] valids = new bool[] { false, true }; string[] works = new[] { "序猿", "攻城", "产品汪", "盘侠", "代码" }; .... //全名称改成了部分名称,能保证是模糊查询吧。。[笑] }
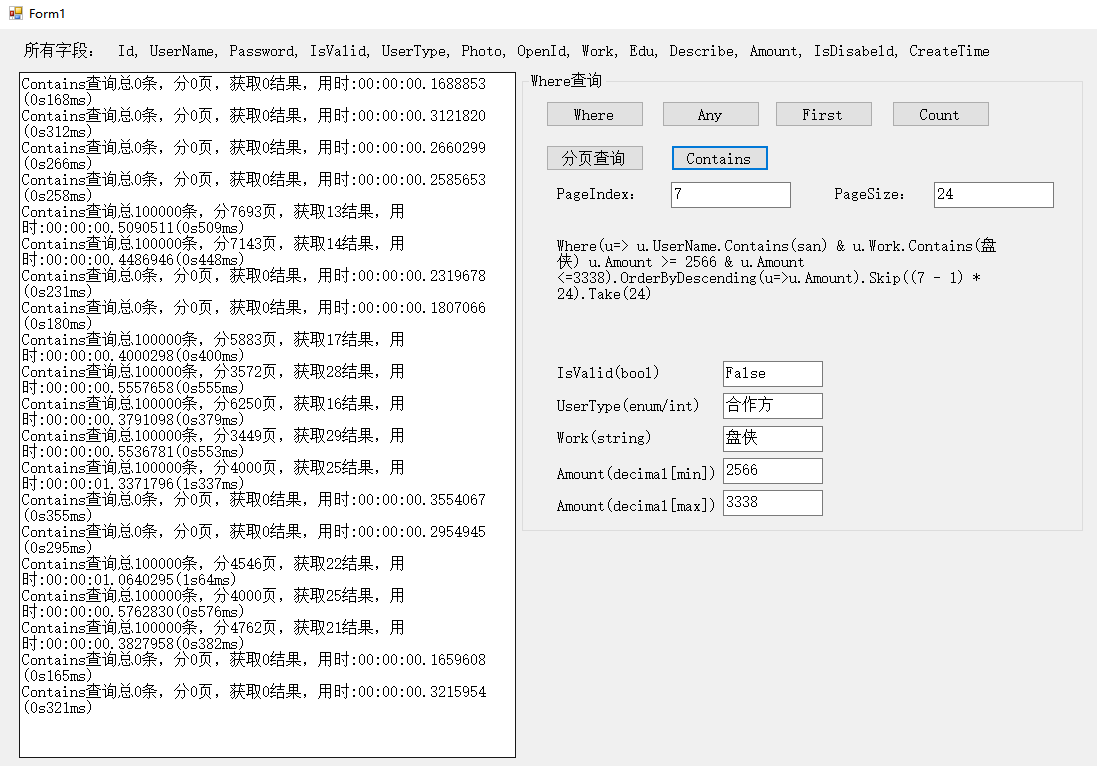
感觉确实有点慢,500ms左右,毕竟Contains,毕竟like,毕竟100w数据吧,有些条件下还是可以接受的,毕竟方便,做个自己用的查询还是可以的。
六、数据量加大
既然是百万级别,也不能只有一百万。
1.二百万的数据







总结一下:
Find无压力,没区别,大概是因为主键索引的缘故。
Any,First,Count都还在100ms左右,还能用。
分页已经到了400ms,感觉已经不能接受了。但是我真的还没咋见过能分几千页的,这里可以先用Where过滤到一些老旧数据或者不要的数据再进行分页应该还是不错的。
Contains已经到了1s了,这对于用户来说已经不能接受了,但是到了这个级别的数据,应该就用上检索引擎了。这个就不考虑了。
2.三百万的数据







总结一下:
Find无压力,还是没啥区别,大概是因为主键索引的缘故。
Any,First能查询到结果时还是挺快了,Count感觉在这里更好用了。
分页到了500ms,还是那句话,这里可以先用Where过滤到一些老旧数据或者不要的数据再进行分页,可以看一下,分页的总记录数都是一,二百万,算了自己想办法优化吧。
Contains不说了。
4.四百万的数据







总结一下:
Find无压力,还是没啥区别,大概是因为主键索引的缘故。
Any,First查不到就慢了,Count感觉在这里更好用了。
分页不说了。
Contains不说了。
七、结语
当写到这里的时候,我感觉我错了,这些好像和EF没有半毛钱关系,这么简单的查询,EF生成Sql语句应该不耗费什么时间。根本没有发挥出EF的linq语法什么的,各种复杂查询语句,各种连接语句的生成。纳尼!!!
但是既然都到这个地步了,那就算了,就当做是对Sql Server性能的考验吧。话说应该200w数据的情况下,EF应该还是可以随便这样用的,再说了,我的用的是自己的个人电脑,要是用服务器肯定无压力的。
感觉EF快不快还是和程序员写的语句有关吧,怎么获取数据,怎么查询,怎么拼接,毕竟到最后都是生成sql语句去查询,所以瓶颈应该在如何快速的生成高效的Sql语句。
对于一个创业公司,刚开始做的项目,数据连几十万都不到,肯定果断用EF啊,容易上手,开发方便,不用写Sql是最重要的,毕竟微软的东西,都迭代这么多版本了,应该优化的差不多了吧。
PS:第一次写博客,不知道测试的姿势对不对,方向对不对,有错了大神指出来,请不要喷我,我会哭的[哈哈],我只是一个只会写增删改查的小码农。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号