
HBASE工作原理
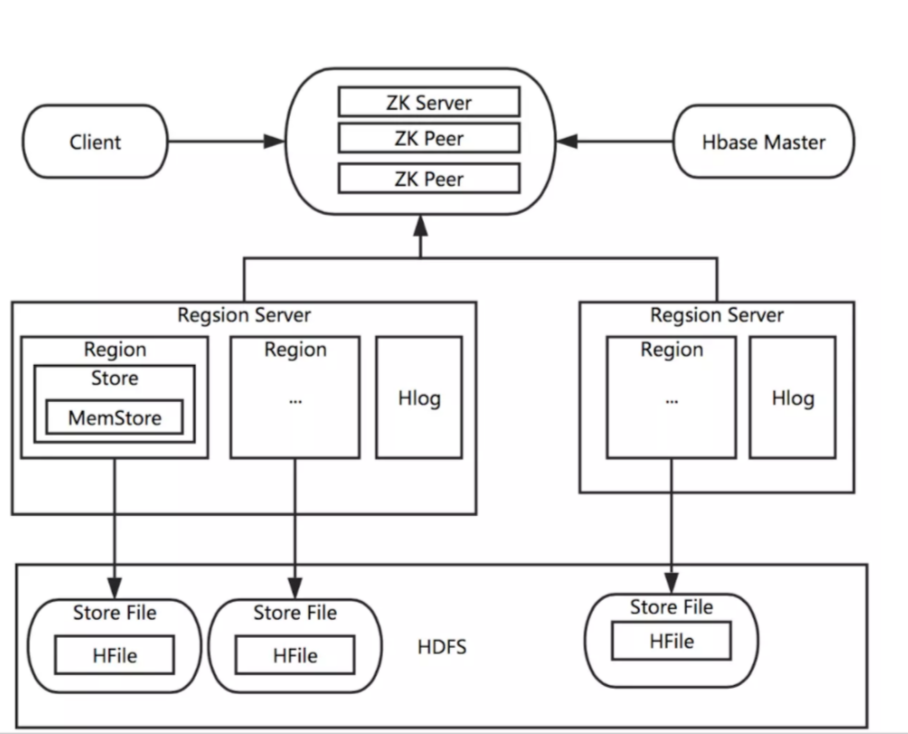
如上图所示;首先我们需要知道 HBase 的集群是通过 Zookeeper 来进行机器之前的协调,也就是说 HBase Master 与 Region Server 之间的关系是依赖 Zookeeper 来维护。当一个 Client 需要访问 HBase 集群时,Client 需要先和 Zookeeper 来通信,然后才会找到对应的 Region Server。每一个 Region Server 管理着很多个 Region。对于 HBase 来说,Region 是 HBase 并行化的基本单元。因此,数据也都存储在 Region 中。这里我们需要特别注意,每一个 Region 都只存储一个 Column Family 的数据,并且是该 CF 中的一段(按 Row 的区间分成多个 Region)。Region 所能存储的数据大小是有上限的,当达到该上限时(Threshold),Region 会进行分裂,数据也会分裂到多个 Region 中,这样便可以提高数据的并行化,以及提高数据的容量。每个 Region 包含着多个 Store 对象。每个 Store 包含一个 MemStore,和一个或多个 HFile。MemStore 便是数据在内存中的实体,并且一般都是有序的。当数据向 Region 写入的时候,会先写入 MemStore。当 MemStore 中的数据需要向底层文件系统倾倒(Dump)时(例如 MemStore 中的数据体积到达 MemStore 配置的最大值),Store 便会创建 StoreFile,而 StoreFile 就是对 HFile 一层封装。所以 MemStore 中的数据会最终写入到 HFile 中,也就是磁盘 IO。由于 HBase 底层依靠 HDFS,因此 HFile 都存储在 HDFS 之中。这便是整个 HBase 工作的原理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号