图书相关表关系建立/基于双下划线的跨表查询/ 聚合查询/ F查询
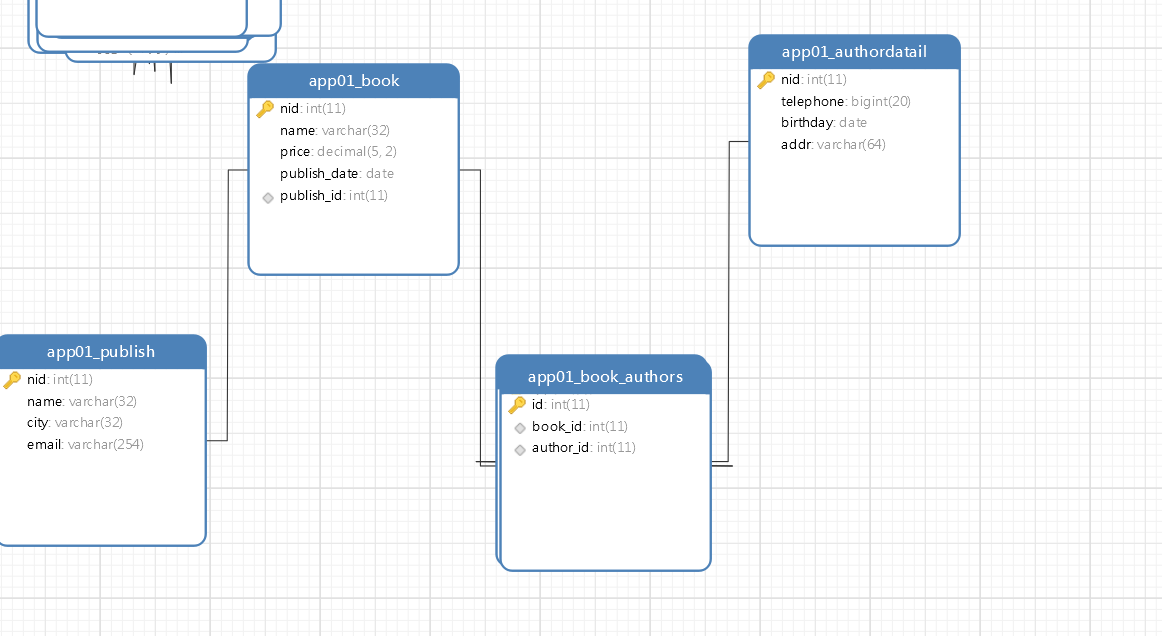
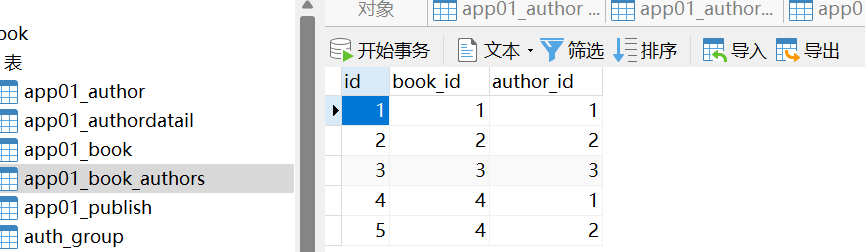
1 5个表 2 书籍表,作者表,作者详情表,出版社表,书籍和作者表(多对多关系) 3 一对一的关系,关联字段可以写在任意一方 4 一对多的关系,关联字段写在多的一方 5 多对多的关系,必须建立第三张表(orm中,可以用一个字段表示,这个字段可以写在任意一方) 5 把表关系同步到数据库中 -python3 manage.py makemigrations # 在migrations文件夹下记录一下 -python3 manage.py migrate # 把记录变更到数据库 6 表关系 from django.db import models class Publish(models.Model): nid = models.AutoField(primary_key=True) name = models.CharField(max_length=32) city = models.CharField(max_length=32) email = models.EmailField() # 本质是varchar类型 class Book(models.Model): nid = models.AutoField(primary_key=True) # 自增,主键 name = models.CharField(max_length=32) # varchar 32 price = models.DecimalField(max_digits=5, decimal_places=2) publish_date = models.DateField() # 年月日类型 # 阅读数 # reat_num=models.IntegerField(default=0) # 评论数 # commit_num=models.IntegerField(default=0) # 建议加引号,也可以不加引号 #models.CASCADE:级联删除,设为默认值,设为空,设为指定的值,不做处理 # 2.x以后必须加,否则报错 # publish = models.ForeignKey(to=Publish,to_field='nid',on_delete=models.CASCADE) publish = models.ForeignKey(to=Publish,to_field='nid',on_delete=models.CASCADE) # 在数据库中,根本没有这个字段,orm用来查中介模型询,映射成一个表了 # 如果我不这么写,手动建立第三张表, authors=models.ManyToManyField(to='Author') def __str__(self): return self.name class Author(models.Model): nid = models.AutoField(primary_key=True) name = models.CharField(max_length=32) age = models.IntegerField() author_detail = models.OneToOneField(to='AuthorDatail',to_field='nid',unique=True,on_delete=models.CASCADE) # author_detail = models.ForeignKey(to='AuthorDatail',to_field='nid',unique=True,on_delete=models.CASCADE) class AuthorDatail(models.Model): nid = models.AutoField(primary_key=True) telephone = models.BigIntegerField() birthday = models.DateField() addr = models.CharField(max_length=64)
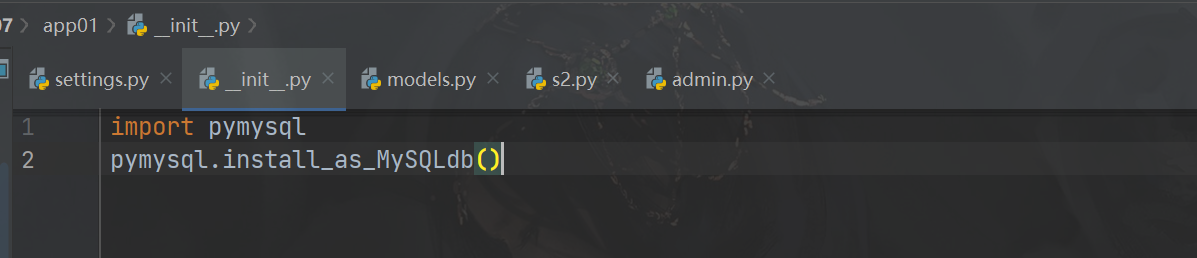
3 django 的orm使用pymysql连接mysql
-需要加这一句话(本质就是猴子补丁的应用)
import pymysql
pymysql.install_as_MySQLdb()
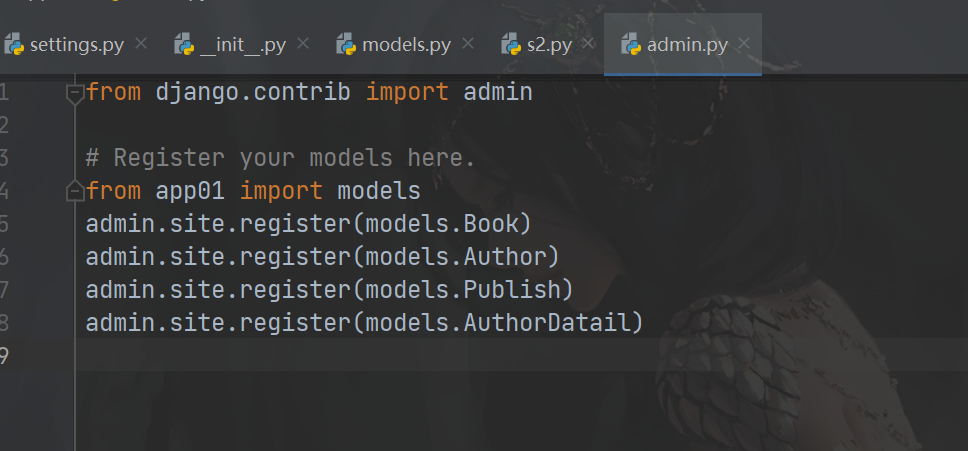
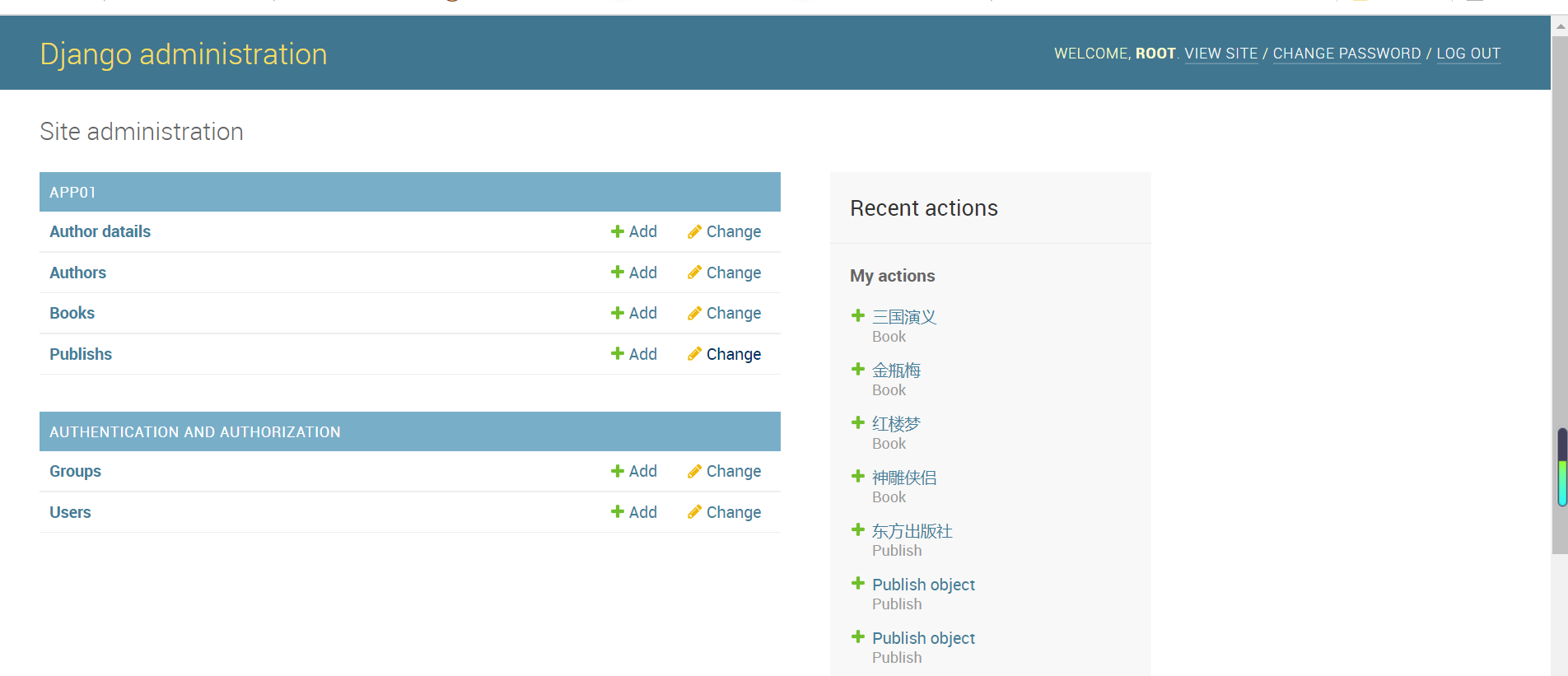
后台管理,方便我们快速的录入书籍 2 使用方法: 第一步:在admin.py 中把要使用的表注册 from app01 import models admin.site.register(models.Book) admin.site.register(models.Author) admin.site.register(models.AuthorDatail) admin.site.register(models.Publish) 第二步:创建个超级管理员 python3 manage.py createsuperuser 输入用户名,输入密码 第三步:登录,录入书籍 -http://127.0.0.1:8000/admin/
1 基于对象的跨表查 -子查询,多次查询 2 基于双下划线的跨表查 -多表连接查询
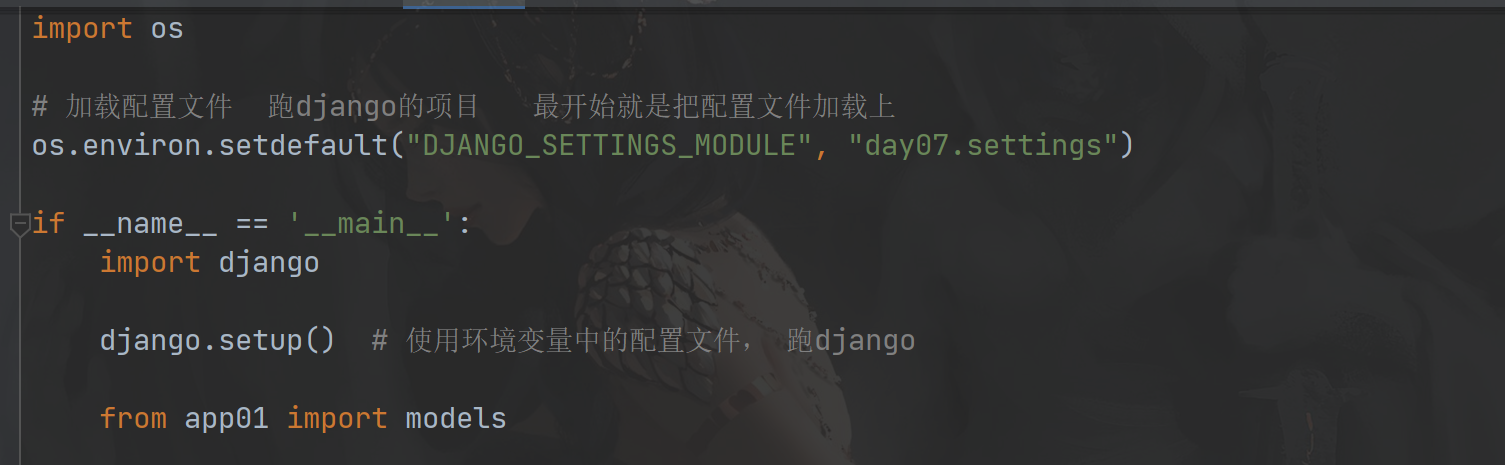
import os #加载配置文件,跑django的项目,最开始就是把配置文件加载上 os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day53.settings") if __name__ == '__main__': import django # 安装了django模块,就可以import django.setup() # 使用环境变量中的配置文件,跑django from app01 import models
查询主键为1 的书籍的出版社所在的城市 一对多的关系
基于对象的查询 # book = models.Book.objects.filter(pk=1).first() # print(book.publish.city) 基于下划线的 # res = models.Book.objects.filter(pk=1).values('publish__city') # print(res) # res = models.Publish.objects.filter(book__nid=1).values('city') # print(res)

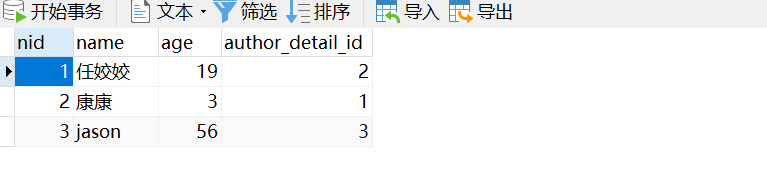
2、查询所有的住址在静宁的作者的姓名
res = models.Author.objects.filter(author_detail__addr='静宁').values('name') print(res) res = models.AuthorDatail.objects.filter(addr='平凉').values('author__name') print(res)
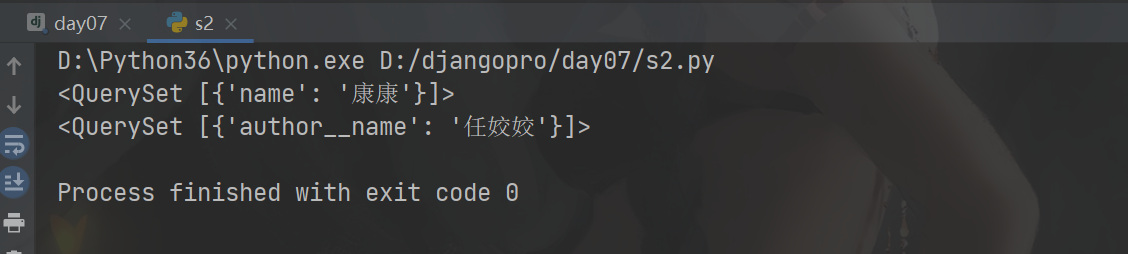
3、查询康康出过的所有书籍的名字
# 正向 # res = models.Book.objects.filter(authors__name='康康').values('name') # print(res) # # 反向 # res = models.Author.objects.filter(name='康康').values('book__name') # print(res)
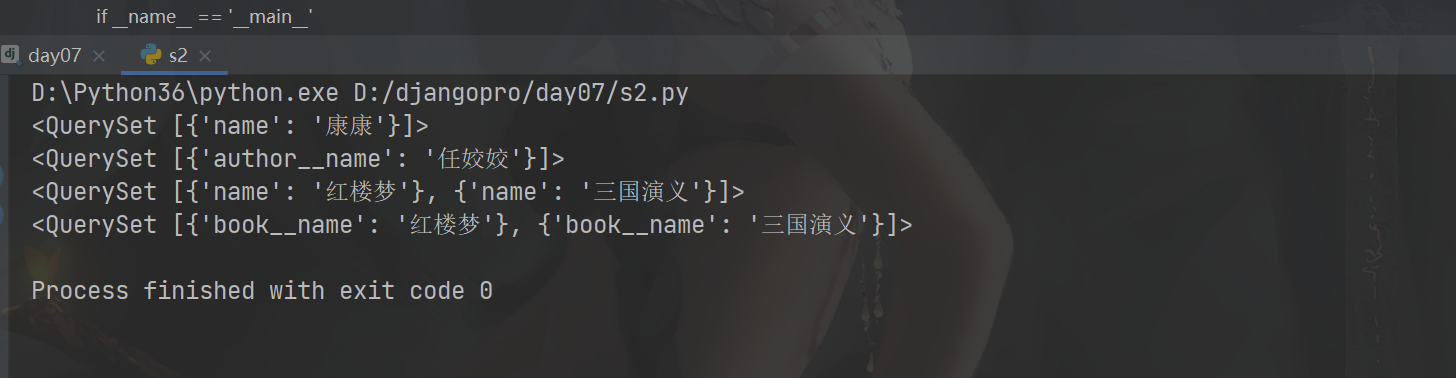
# 基于双下划线的最顶级的v版本
# 查询东京出版社出版过的所有的书籍的名字以及作者的姓名和地址
# res = models.Book.objects.filter(publish__name='东京出版社') .values('publish__name', 'name', 'authors__name','authors__author_detail__addr') # # print(res) # # res = models.Book.objects.filter(publish__name='东京出版社').values('publish__name','name','authors__author_detail__addr') # print(res) # res = models.Author.objects.filter(book__publish__name='东京出版社').values('book__publish__name','book__name','author_detail__addr') # print(res) # res = models.Publish.objects.filter(name='东京出版社').values('name','book__name','book__authors__name','book__authors__author_detail') # print(res) # res = models.AuthorDatail.objects.filter(author__book__publish__name='东京出版社').values('author__book__publish__name','author__book__name','author__name','addr') # print(res)
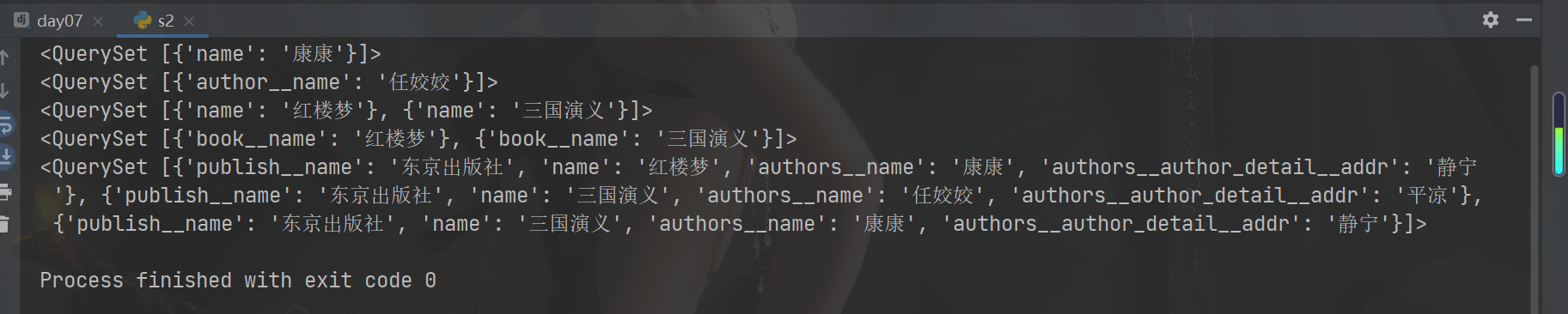
聚合查询
计算所有的图书平均价格
from django.db.models import Sum, Avg, Max, Min, Count # # res = models.Book.objects.all().aggregate(Avg('price')) # print(res)
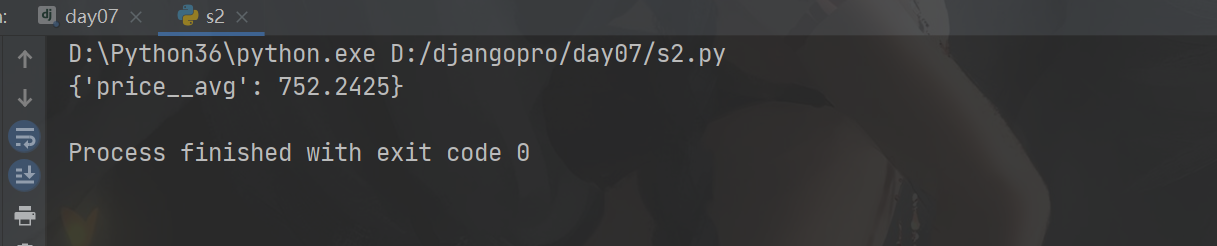
# 计算所有图书的总价格 # res = models.Book.objects.all().aggregate(book_sum=Sum('price')) # print(res) #计算所有图书的平均价格 # res =models.Book.objects.all().aggregate(book_avg=Avg('price')) # print(res)
F查询 取出某个字段对应的值
from django.db.models import F
查询评论数大于阅读数的书籍
查询评论数大于阅读数的书籍 # res = models.Book.objects.filter(commit_num__gt=F('reat_num')) # print(res) # res = models.Book.objects.filter(commit_num__gt=F('read_num')) # print(res)

# 把所有图书价格+1
# res=models.Book.objects.all().update(price=F('price')+1) # print(res)

# Q查询:构造出与& 或| 非~
from django.db.models import Q
# 查询名字叫红楼梦或者价格大于100的书
res=models.Book.objects.filter(name='红楼梦',price__gt=100)
# res=models.Book.objects.filter(Q(name='红楼梦')|Q(price__gt=100))
# res=models.Book.objects.filter(Q(name='红楼梦')|Q(price__gt=100)) # print(res)

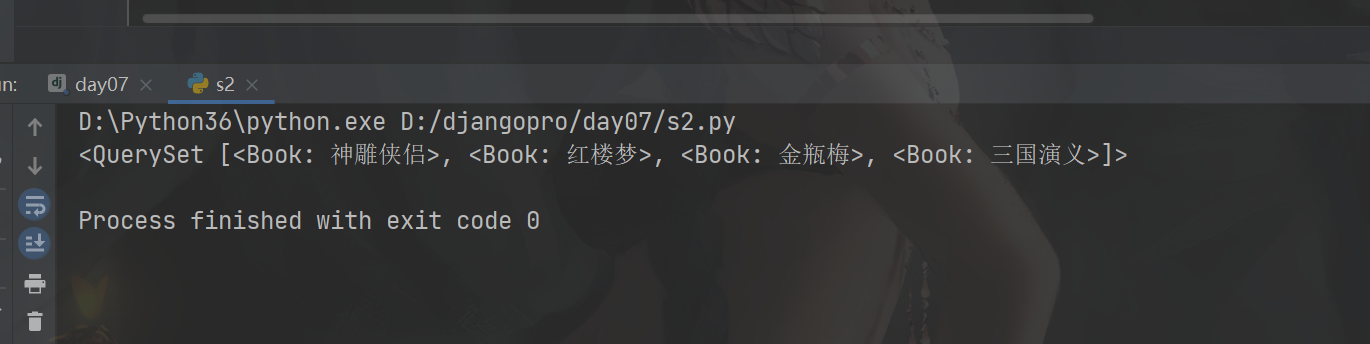
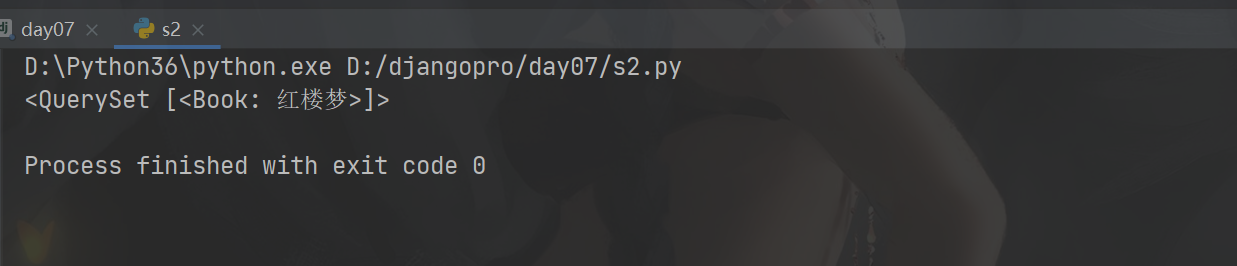
# 查询名字不是红楼梦的书
res=models.Book.objects.filter(~Q(name='红楼梦'))

#查询名字不是红楼梦,并且价格大于100的书
# res = models.Book.objects.filter(~Q(name='红楼梦'),price__gt='100') res = models.Book.objects.filter(~Q(name='红楼梦')&Q(price__gt='100')) print(res)

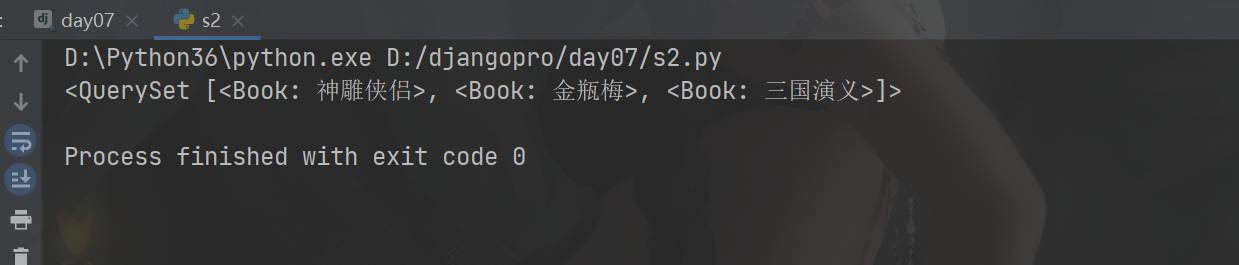


1 普通函数以__开头
-说明当前函数只在当前模块(py)下使用,尽量不在外部调用
2 mysql
-utf8:2个字节表示一个字符
-utf8mb4:等同于真正意义上的utf-8
-utf-8:1--4个字节,表示一个字符
1 queryset对象.query 2 通过日志,如下,配置到setting.py中 LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console':{ 'level':'DEBUG', 'class':'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level':'DEBUG', }, } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号