
MATLAB实现随机森林(RF)回归与自变量影响程度分析
本文介绍基于MATLAB,利用随机森林(RF)算法实现回归预测,以及自变量重要性排序的操作。
本文分为两部分,首先是对代码进行分段、详细讲解,方便大家理解;随后是完整代码,方便大家自行尝试。另外,关于基于MATLAB的神经网络(ANN)代码与详细解释,我们将在后期博客中介绍。
1 分解代码
1.1 最优叶子节点数与树数确定
首先,我们需要对RF对应的叶子节点数与树的数量加以择优选取。
%% Number of Leaves and Trees Optimization
for RFOptimizationNum=1:5
RFLeaf=[5,10,20,50,100,200,500];
col='rgbcmyk';
figure('Name','RF Leaves and Trees');
for i=1:length(RFLeaf)
RFModel=TreeBagger(2000,Input,Output,'Method','R','OOBPrediction','On','MinLeafSize',RFLeaf(i));
plot(oobError(RFModel),col(i));
hold on
end
xlabel('Number of Grown Trees');
ylabel('Mean Squared Error') ;
LeafTreelgd=legend({'5' '10' '20' '50' '100' '200' '500'},'Location','NorthEast');
title(LeafTreelgd,'Number of Leaves');
hold off;
disp(RFOptimizationNum);
end
其中,RFOptimizationNum是为了多次循环,防止最优结果受到随机干扰;大家如果不需要,可以将这句话删除。
RFLeaf定义初始的叶子节点个数,我这里设置了从5到500,也就是从5到500这个范围内找到最优叶子节点个数。
Input与Output分别是我的输入(自变量)与输出(因变量),大家自己设置即可。
运行后得到下图。
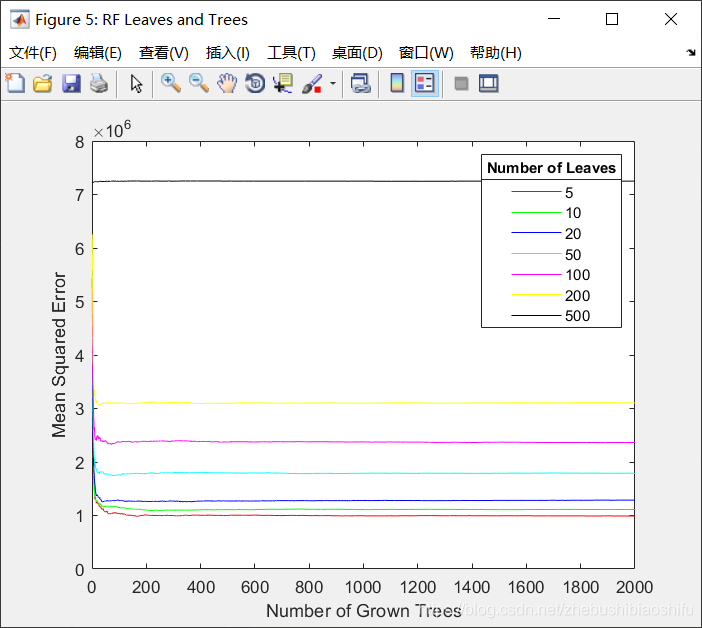
首先,我们看到MSE最低的线是红色的,也就是5左右的叶子节点数比较合适;再看各个线段大概到100左右就不再下降,那么树的个数就是100比较合适。
1.2 循环准备
由于机器学习往往需要多次执行,我们就在此先定义循环。
%% Cycle Preparation
RFScheduleBar=waitbar(0,'Random Forest is Solving...');
RFRMSEMatrix=[];
RFrAllMatrix=[];
RFRunNumSet=10;
for RFCycleRun=1:RFRunNumSet
其中,RFRMSEMatrix与RFrAllMatrix分别用来存放每一次运行的RMSE、r结果,RFRunNumSet是循环次数,也就是RF运行的次数。
1.3 数据划分
接下来,我们需要将数据划分为训练集与测试集。这里要注意:RF其实一般并不需要划分训练集与测试集,因为其可以采用袋外误差(Out of Bag Error,OOB Error)来衡量自身的性能。但是因为我是做了多种机器学习方法的对比,需要固定训练集与测试集,因此就还进行了数据划分的步骤。
%% Training Set and Test Set Division
RandomNumber=(randperm(length(Output),floor(length(Output)*0.2)))';
TrainYield=Output;
TestYield=zeros(length(RandomNumber),1);
TrainVARI=Input;
TestVARI=zeros(length(RandomNumber),size(TrainVARI,2));
for i=1:length(RandomNumber)
m=RandomNumber(i,1);
TestYield(i,1)=TrainYield(m,1);
TestVARI(i,:)=TrainVARI(m,:);
TrainYield(m,1)=0;
TrainVARI(m,:)=0;
end
TrainYield(all(TrainYield==0,2),:)=[];
TrainVARI(all(TrainVARI==0,2),:)=[];
其中,TrainYield是训练集的因变量,TrainVARI是训练集的自变量;TestYield是测试集的因变量,TestVARI是测试集的自变量。
因为我这里是做估产回归的,因此变量名称就带上了Yield,大家理解即可。
1.4 随机森林实现
这部分代码其实比较简单。
%% RF
nTree=100;
nLeaf=5;
RFModel=TreeBagger(nTree,TrainVARI,TrainYield,...
'Method','regression','OOBPredictorImportance','on', 'MinLeafSize',nLeaf);
[RFPredictYield,RFPredictConfidenceInterval]=predict(RFModel,TestVARI);
其中,nTree、nLeaf就是本文1.1部分中我们确定的最优树个数与最优叶子节点个数,RFModel就是我们所训练的模型,RFPredictYield是预测结果,RFPredictConfidenceInterval是预测结果的置信区间。
1.5 精度衡量
在这里,我们用RMSE与r衡量模型精度。
%% Accuracy of RF
RFRMSE=sqrt(sum(sum((RFPredictYield-TestYield).^2))/size(TestYield,1));
RFrMatrix=corrcoef(RFPredictYield,TestYield);
RFr=RFrMatrix(1,2);
RFRMSEMatrix=[RFRMSEMatrix,RFRMSE];
RFrAllMatrix=[RFrAllMatrix,RFr];
if RFRMSE<400
disp(RFRMSE);
break;
end
disp(RFCycleRun);
str=['Random Forest is Solving...',num2str(100*RFCycleRun/RFRunNumSet),'%'];
waitbar(RFCycleRun/RFRunNumSet,RFScheduleBar,str);
end
close(RFScheduleBar);
在这里,我定义了当RMSE满足<400这个条件时,模型将自动停止;否则将一直执行到本文1.2部分中我们指定的次数。其中,模型每一次运行都会将RMSE与r结果记录到对应的矩阵中。
1.6 变量重要程度排序
接下来,我们结合RF算法的一个功能,对所有的输入变量进行分析,去获取每一个自变量对因变量的解释程度。
%% Variable Importance Contrast
VariableImportanceX={};
XNum=1;
% for TifFileNum=1:length(TifFileNames)
% if ~(strcmp(TifFileNames(TifFileNum).name(4:end-4),'MaizeArea') | ...
% strcmp(TifFileNames(TifFileNum).name(4:end-4),'MaizeYield'))
% eval(['VariableImportanceX{1,XNum}=''',TifFileNames(TifFileNum).name(4:end-4),''';']);
% XNum=XNum+1;
% end
% end
for i=1:size(Input,2)
eval(['VariableImportanceX{1,XNum}=''',i,''';']);
XNum=XNum+1;
end
figure('Name','Variable Importance Contrast');
VariableImportanceX=categorical(VariableImportanceX);
bar(VariableImportanceX,RFModel.OOBPermutedPredictorDeltaError)
xtickangle(45);
set(gca, 'XDir','normal')
xlabel('Factor');
ylabel('Importance');
这里代码就不再具体解释了,大家会得到一幅图,是每一个自变量对因变量的重要程度,数值越大,重要性越大。
其中,我注释掉的这段是依据我当时的数据情况来的,大家就不用了。
更新:这里请大家注意,上述代码中我注释掉的内容,是依据每一幅图像的名称对重要性排序的X轴(也就是VariableImportanceX)加以注释(我当时做的是依据遥感图像估产,因此每一个输入变量的名称其实就是对应的图像的名称),所以使得得到的变量重要性柱状图的X轴会显示每一个变量的名称。大家用自己的数据来跑的时候,可以自己设置一个变量名称的字段元胞然后放到VariableImportanceX,然后开始figure绘图;如果在输入数据的特征个数(也就是列数)比较少的时候,也可以用我上述代码中间的这个for i=1:size(Input,2)循环——这是一个偷懒的办法,也就是将重要性排序图的X轴中每一个变量的名称显示为一个正方形,如下图红色圈内。这里比较复杂,因此如果大家这一部分没有搞明白或者是一直报错,在本文下方直接留言就好~

1.7 保存模型
接下来,就可以将合适的模型保存。
%% RF Model Storage
RFModelSavePath='G:\CropYield\02_CodeAndMap\00_SavedModel\';
save(sprintf('%sRF0410.mat',RFModelSavePath),'nLeaf','nTree',...
'RandomNumber','RFModel','RFPredictConfidenceInterval','RFPredictYield','RFr','RFRMSE',...
'TestVARI','TestYield','TrainVARI','TrainYield');
其中,RFModelSavePath是保存路径,save后的内容是需要保存的变量名称。
2 完整代码
完整代码如下:
%% Number of Leaves and Trees Optimization
for RFOptimizationNum=1:5
RFLeaf=[5,10,20,50,100,200,500];
col='rgbcmyk';
figure('Name','RF Leaves and Trees');
for i=1:length(RFLeaf)
RFModel=TreeBagger(2000,Input,Output,'Method','R','OOBPrediction','On','MinLeafSize',RFLeaf(i));
plot(oobError(RFModel),col(i));
hold on
end
xlabel('Number of Grown Trees');
ylabel('Mean Squared Error') ;
LeafTreelgd=legend({'5' '10' '20' '50' '100' '200' '500'},'Location','NorthEast');
title(LeafTreelgd,'Number of Leaves');
hold off;
disp(RFOptimizationNum);
end
%% Notification
% Set breakpoints here.
%% Cycle Preparation
RFScheduleBar=waitbar(0,'Random Forest is Solving...');
RFRMSEMatrix=[];
RFrAllMatrix=[];
RFRunNumSet=50000;
for RFCycleRun=1:RFRunNumSet
%% Training Set and Test Set Division
RandomNumber=(randperm(length(Output),floor(length(Output)*0.2)))';
TrainYield=Output;
TestYield=zeros(length(RandomNumber),1);
TrainVARI=Input;
TestVARI=zeros(length(RandomNumber),size(TrainVARI,2));
for i=1:length(RandomNumber)
m=RandomNumber(i,1);
TestYield(i,1)=TrainYield(m,1);
TestVARI(i,:)=TrainVARI(m,:);
TrainYield(m,1)=0;
TrainVARI(m,:)=0;
end
TrainYield(all(TrainYield==0,2),:)=[];
TrainVARI(all(TrainVARI==0,2),:)=[];
%% RF
nTree=100;
nLeaf=5;
RFModel=TreeBagger(nTree,TrainVARI,TrainYield,...
'Method','regression','OOBPredictorImportance','on', 'MinLeafSize',nLeaf);
[RFPredictYield,RFPredictConfidenceInterval]=predict(RFModel,TestVARI);
% PredictBC107=cellfun(@str2num,PredictBC107(1:end));
%% Accuracy of RF
RFRMSE=sqrt(sum(sum((RFPredictYield-TestYield).^2))/size(TestYield,1));
RFrMatrix=corrcoef(RFPredictYield,TestYield);
RFr=RFrMatrix(1,2);
RFRMSEMatrix=[RFRMSEMatrix,RFRMSE];
RFrAllMatrix=[RFrAllMatrix,RFr];
if RFRMSE<1000
disp(RFRMSE);
break;
end
disp(RFCycleRun);
str=['Random Forest is Solving...',num2str(100*RFCycleRun/RFRunNumSet),'%'];
waitbar(RFCycleRun/RFRunNumSet,RFScheduleBar,str);
end
close(RFScheduleBar);
%% Variable Importance Contrast
VariableImportanceX={};
XNum=1;
% for TifFileNum=1:length(TifFileNames)
% if ~(strcmp(TifFileNames(TifFileNum).name(4:end-4),'MaizeArea') | ...
% strcmp(TifFileNames(TifFileNum).name(4:end-4),'MaizeYield'))
% eval(['VariableImportanceX{1,XNum}=''',TifFileNames(TifFileNum).name(4:end-4),''';']);
% XNum=XNum+1;
% end
% end
for i=1:size(Input,2)
eval(['VariableImportanceX{1,XNum}=''',i,''';']);
XNum=XNum+1;
end
figure('Name','Variable Importance Contrast');
VariableImportanceX=categorical(VariableImportanceX);
bar(VariableImportanceX,RFModel.OOBPermutedPredictorDeltaError)
xtickangle(45);
set(gca, 'XDir','normal')
xlabel('Factor');
ylabel('Importance');
%% RF Model Storage
RFModelSavePath='G:\CropYield\02_CodeAndMap\00_SavedModel\';
save(sprintf('%sRF0410.mat',RFModelSavePath),'nLeaf','nTree',...
'RandomNumber','RFModel','RFPredictConfidenceInterval','RFPredictYield','RFr','RFRMSE',...
'TestVARI','TestYield','TrainVARI','TrainYield');
至此,大功告成。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律