

def getText():
txt=open("D:\\test.txt","r").read()
txt=txt.lower()
punctuation = r"""!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~“”?,!【】()、。:;’‘……¥·"""
for ch in punctuation:
txt=txt.replace(ch,"")
return txt
hamletTxt=getText()
words=hamletTxt.split()
counts={}
for word in words:
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(100):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
#!/usr/bin/env python
import sys
for line in sys.stdin:
line = line.strip()
words=line.split()
for word in words:
print("{}\t{}".format(word,1))
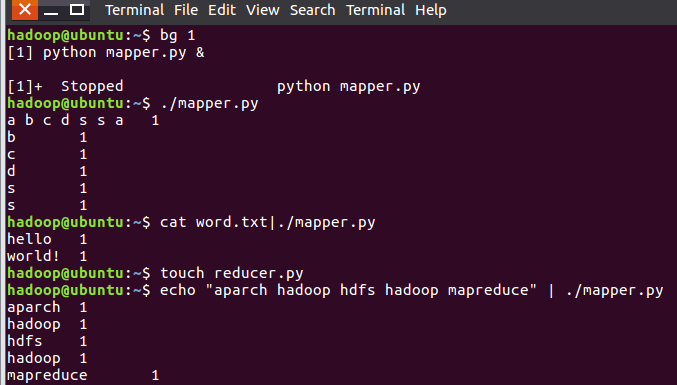
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
print "%s\t%s" % (current_word, current_count)
current_count = count
current_word = word
if word == current_word:
print "%s\t%s" % (current_word, current_count)
![]()

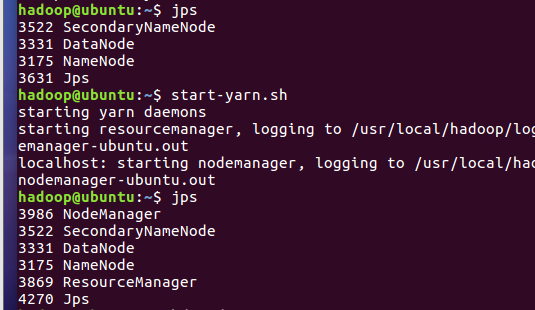
2.3分布式运行自带词频统计示例
- 启动HDFS与YARN
![]()
- 准备待处理文件
- 上传HDFS
![]()
- 运行hadoop-mapreduce-examples-2.7.1.jar
![]()
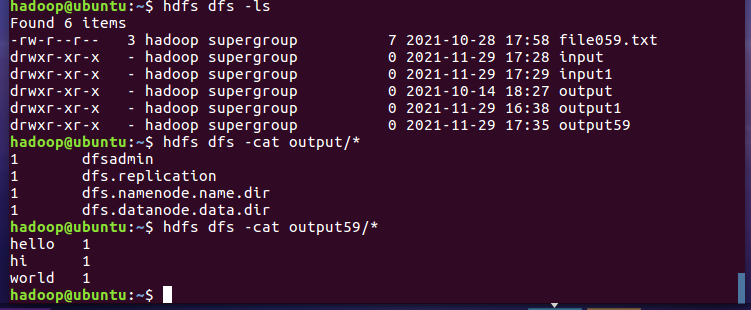
- 查看结果


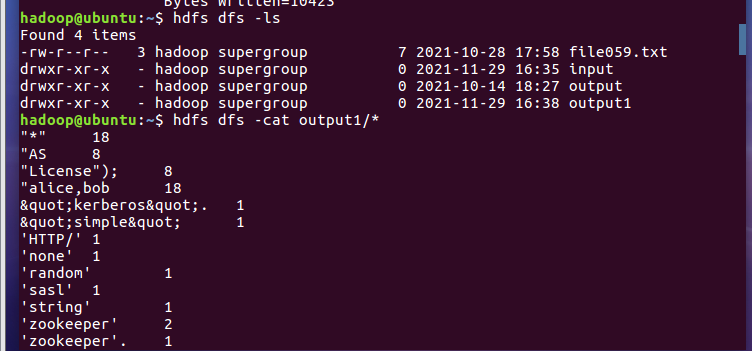
2.4 分布式运行自写的词频统计
-
- 停止HDFS与YARN


 浙公网安备 33010602011771号
浙公网安备 33010602011771号