机器学习(2)-- 衡量回归的性能指标
衡量回归的性能指标
机器学习通常都是将训练集上的数据对模型进行训练,然后再将测试集上的数据给训练好的模型进行预测,最后根据模型性能的好坏选择模型,对于分类问题,大家很容易想到,可以使用正确率来评估模型的性能,那么回归问题可以使用哪些指标用来评估呢?
- (均方误差) :
- 表示第个样本的真实标签,表示模型对第个样本的预测标签。线性回归的目的就是让损失函数最小。那么模型训练出来了,我们在测试集上用损失函数来评估模型就行了。
- (均方根误差) :
- (平均绝对误差) :
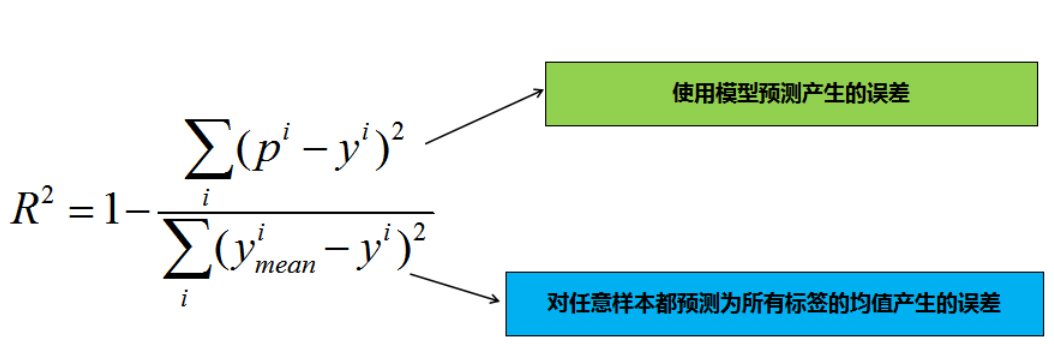
- :
- 其中表示所有测试样本标签值的均值(其实分子表示的是模型预测时产生的误差,分母表示的是对任意样本都预测为所有标签均值时产生的误差)
准确度的陷阱与混淆矩阵
准确度:
- 准确对越高就能说明模型的分类性能越好吗?非也!
混淆矩阵:(意义)
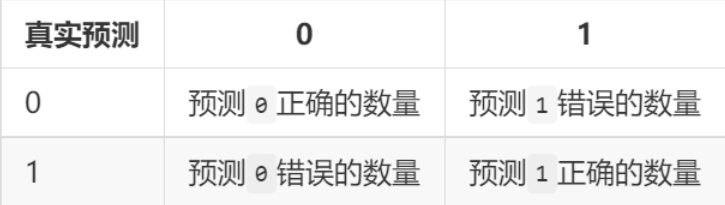
如果将正确看成是 ,错误看成是 , 看成是 , 看成是 。然后将上表中的文字替换掉,混淆矩阵如下:
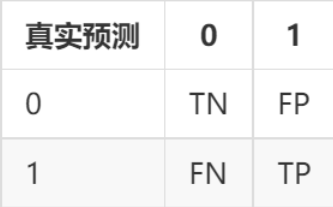
所以模型分类性能越好,混淆矩阵中非对角线上的数值越小。
精准率与召回率:
精准率(Precision) 指的是模型预测为 Positive 时的预测准确度,其计算公式如下:
- 精准率越高,那么癌症检测系统预测某人患有癌症的可信度就越高。
召回率(Recall) 指的是我们关注的事件发生了,并且模型预测正确了的比值,其计算公式如下:
- 召回率越高,那么我们感兴趣的对象成为漏网之鱼的可能性越低。
模型的精准率变高,召回率会变低,精准率变低,召回率会变高。
到底应该使用精准率还是召回率作为性能指标,其实是根据具体业务来决定的。
比如我现在想要训练一个模型来预测我关心的股票是涨( )还是跌( ),那么我们应该主要使用精准率作为性能指标。
因为精准率高的话,则模型预测该股票要涨的可信度就高(很有可能赚钱!)。
比如现在需要训练一个模型来预测人是( )否( )患有艾滋病,那么我们应该主要使用召回率作为性能指标。因为召回率太低的话,很有可能存在漏网之鱼(可能一个人本身患有艾滋病,但预测成了健康),这样就很可能导致病人错过了最佳的治疗时间,这是非常致命的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?