线程池、进程池、协程
event事件
调用Event类实例化一个对象
e = Event()
若该方法出现在任务中,则为False,阻塞
e.wait() # False
若该方法出现在任务中,则将其他线程的Flase改为True,进入就绪态与运行态
e.set() # True
from threading import Event from threading import Thread import time # 调用Event类实例化一个对象 e = Event() def light(): print('红灯亮...') time.sleep(5) # 应该开始发送信号,告诉其他线程准备执行 e.set() # 将car中的False ---> True print('绿灯亮...') def car(name): print('正在等红灯....') # 让所有汽车任务进入阻塞态 e.wait() # False print(f'{name}正在加速漂移....') # 让一个light线程任务 控制多个car线程任务 t = Thread(target=light) t.start() for line in range(3): t = Thread(target=car, args=(f'童子军jason{line}号', )) t.start() #打印结果 红灯亮... 正在等红灯.... 正在等红灯.... 正在等红灯.... 绿灯亮... 童子军jason2号正在加速漂移.... 童子军jason0号正在加速漂移.... 童子军jason1号正在加速漂移....
线程池与进程池
1)什么是进程池与线程池?
进程池与线程池是用来控制当前程序允许创建(进程/线程)的数量.
2)进程池与线程池的作用:
保证在硬件允许的范围内创建 (进程/线程) 的数量.
3)如何使用:
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor import time # ProcessPoolExecutor(5) # 5代表只能开启5个进程 # ProcessPoolExecutor() # 默认以CPU的个数限制进程数 pool = ThreadPoolExecutor(5) # 5代表只能开启5个线程 -5 +1 -1 +1 -1 # ThreadPoolExecutor() # 默认以CPU个数 * 5 限制线程数 # t = Tread() # 异步提交 # t.start(0) # pool.submit('传函数地址') # 异步提交任务 # def task(): # print('线程任务开始了...') # time.sleep(1) # print('线程任务结束了...') # # # for line in range(5): # pool.submit(task) # 异步提交任务 # pool.submit('传函数地址').add_done_callback('回调函数地址') def task(res): # res == 1 print('线程任务开始了...') time.sleep(1) print('线程任务结束了...') return 123 # 回调函数 def call_back(res): print(type(res)) # 注意: 赋值操作不要与接收的res同名 res2 = res.result() print(res2) for line in range(5): pool.submit(task, 1).add_done_callback(call_back) #shutdown(wait=True)# wait=True,等待池内所有任务执行完毕回收完资源后才继续# wait=False,立即返回,并不会等待池内的任务执行完毕# 但不管wait参数为何值,整个程序都会等到所有任务执行完毕
# 会让所有线程池的任务结束后,才往下执行代码,相当于进程池的pool.close()+pool.join()操作
pool.shutdown() print('hello')
案例:高性能爬取梨视频
''' 网站主页: https://www.pearvideo.com/ requests: 用户封装底层socket套接字 - 打开CMD # 下载第三方模块 >> pip3 install requests https://www.pearvideo.com/video_1614813 https://www.pearvideo.com/video_1615201 1.从主页中获取所有的视频ID号(1615201,1614813...) - 拼接视频详情页url https://www.pearvideo.com/video_ + '视频ID号' 2.在视频详情页中获取真实视频url srcUrl="()" 3.往真实视频url地址发送请求获取 视频 二进制数据 4.最后把视频二进制数据保存到本地 ''' from concurrent.futures import ThreadPoolExecutor import requests import re import uuid pool = ThreadPoolExecutor(200) # 1.发送请求函数 def get_page(url): response = requests.get(url) return response # 2.解析主页获取视频ID号 def parse_index(response): id_list = re.findall( '<a href="video_(.*?)".*?>', response.text, re.S ) return id_list # 3.解析视频详情页获取真实 视频链接 def parse_detail(res): response = res.result() movie_detail_url = re.findall('srcUrl="(.*?)"', response.text, re.S)[0] print(f'往视频链接: {movie_detail_url}发送请求...') # 异步往视频详情页链接发送请求,把结果交给 pool.submit(get_page, movie_detail_url).add_done_callback(save_movie) return movie_detail_url # 4.往真实视频链接发送请求,获取数据并保存到本地 def save_movie(res): movie_response = res.result() # print(1111) # movie_response = get_page(movie_detail_url) # print(movie_response) name = str(uuid.uuid4()) print(f'{name}.mp4视频开始保存...') with open(f'{name}.mp4', 'wb') as f: f.write(movie_response.content) print('视频下载完毕!') if __name__ == '__main__': # 1.访问主页获取数据 index_response = get_page('https://www.pearvideo.com/') # # 2.解析主页获取所有的视频id号 id_list = parse_index(index_response) print(id_list) # 3.循环对每个视频详情页链接进行拼接 for id in id_list: print(id) detail_url = 'https://www.pearvideo.com/video_' + id # 异步提交爬取视频详情页,把返回的数据,交给parse_detail(回调函数) pool.submit(get_page, detail_url).add_done_callback(parse_detail)
协程
- 协程是通过手动模拟操作系统 "多道技术",实现 切换 + 保存状态
- 进程: 资源单位
- 线程: 执行单位
- 协程: 在单线程下实现并发
注意: 协程不是操作系统资源,他是程序起的名字,为让单线程能实现并发.
协程的目的:
- 操作系统:
多道技术, 切换 + 保存状态
1) 遇到IO
2) CPU执行时间过长
- 协程是通过手动模拟操作系统 "多道技术",实现 切换 + 保存状态
1)手动实现 遇到IO切换, 欺骗操作系统误以为没有IO操作.
- 单线程 遇到IO, 切换 + 保存状态
- 单线程 计算密集型, 来回切换 + 保存状态是,反而效率更低
优点:
在IO密集型的情况下, 会提高效率.
缺点:
若在计算密集型的情况下, 来回切换, 反而效率更低.
- 如何实现协程: 切换 + 保存状态
- yield: 保存状态
- 并发: 切换
# 验证计算密集型的情况下效率更低: # 1.4250171184539795 # 基于yield并发执行 import time def func1(): while True: 10000000+1 yield def func2(): # g生成器对象 g = func1() for i in range(10000000): time.sleep(100) # 模拟IO,yield并不会捕捉到并自动切换 i+1 next(g) start = time.time() func2() stop = time.time() print(stop-start)
'''gevent: 是一个第三方模块,可以帮你监听IO操作, 并切换. - 使用gevent目的: 为了实现单线程下,实现遇到IO, 保存状态 + 切换 pip3 install gevent ''' from gevent import monkey monkey.patch_all() # 可以监听该程序下所有的IO操作 import time from gevent import spawn, joinall # 用于做切换 + 保存状态 def func1(): print('1') # IO操作 time.sleep(1) def func2(): print('2') time.sleep(3) def func3(): print('3') time.sleep(5) start_time = time.time() s1 = spawn(func1) s2 = spawn(func2) s3 = spawn(func3) # s2.join() # 发送信号,相当于等待自己 (在单线程的情况下) # s1.join() # s3.join() # 必须传序列类型 joinall([s1, s2, s3]) end_time = time.time() print(end_time - start_time) 打印结果: 1 2 3 5.03183388710022
TCP服务端实现单
#客户端
import socket from threading import Thread, current_thread def client(): client = socket.socket() client.connect( ('127.0.0.1', 9527) ) print('启动客户端...') number = 0 while True: send_data = f'{current_thread().name} {number}' client.send(send_data.encode('utf-8')) data = client.recv(1024) print(data.decode('utf-8')) number += 1 # 模拟了300个用户并发去访问服务端 for i in range(300): t = Thread(target=client) t.start()
from gevent import monkey import socket from gevent import spawn monkey.patch_all() # 检测IO server = socket.socket() server.bind( ('127.0.0.1', 9527) ) server.listen(5) print('启动服务端...') # 线程任务,执行接收客户端消息与发送消息给客户端 def working(conn): while True: try: data = conn.recv(1024).decode('utf-8') if len(data) == 0: break print(data) # time.sleep(1) send_data = data.upper().encode('utf-8') conn.send(send_data) except Exception as e: print(e) break conn.close() def server2(): while True: conn, addr = server.accept() # print(addr) # t = Thread(target=working, args=(conn,)) # t.start() spawn(working, conn) if __name__ == '__main__': s1 = spawn(server2) s1.join()
IO模型
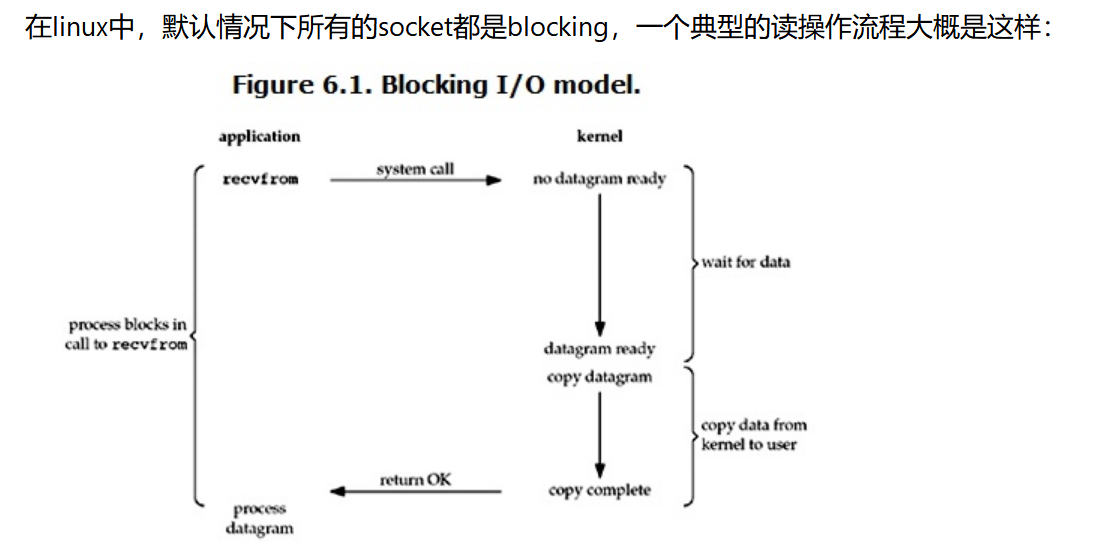
阻塞IO
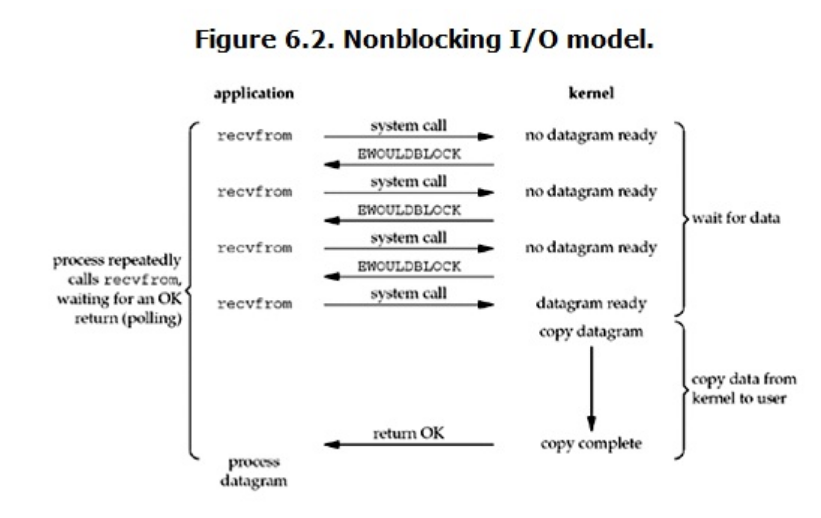
非阻塞IO
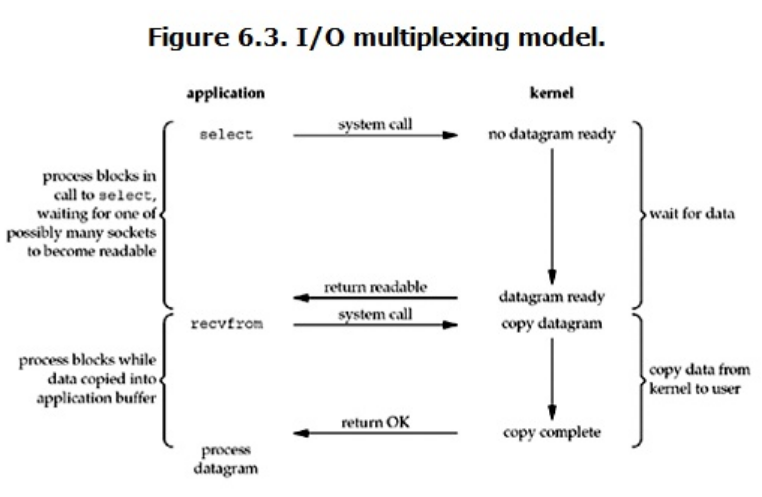
多路复用IO
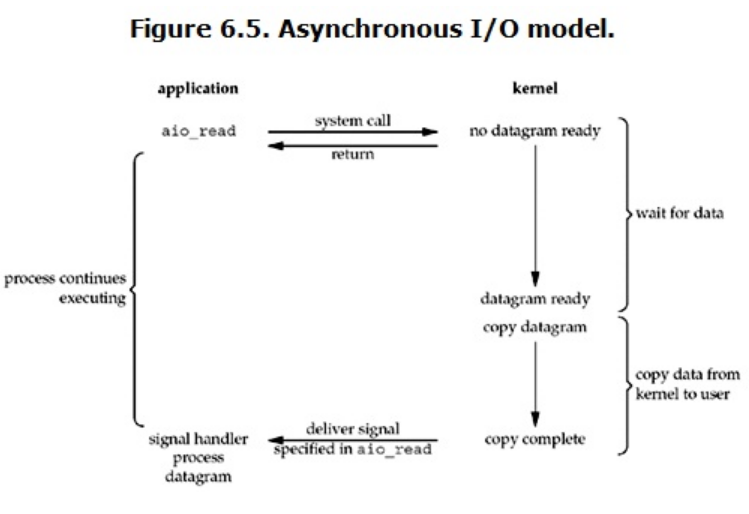
异步IO