

OO第三单元总结分析
JML设计
JML语言基础
基本语法
一般对一个属性/方法的规格描述在其紧邻的上方
原子表达式
\result: 表示一个非void方法的返回值\old(expr): 表示一个表达式expr在方法执行前的值- 注意 : 当
expr为一个引用对象时只表示引用对象的地址值,不代表引用对象的引用值
- 注意 : 当
\not_assigned(x,y,...): 表示括号内的各个变量在方法前后没有改变(被赋值)\typeof(expr): 返回expr的数据类型,用来判断是否等于\type(type[int/boolean....])
量化表达式
-
全称量词 :
\forall表达式使用 :
\forall int i; P(i) ; P在i满足P(i)时,必须由P逻辑为真即在给定范围内的元素要保证
P恒为真 -
存在量词 :
\exists表达式使用 :
\exists int i; P(i); P即在给定范围内至少存在一个元素使
P为真 -
求和 :
\sum表达式使用 :
\sum int i; P(i); n(i)即求给定范围内的某一类数据的和
-
计数 :
num_of表达式使用 :
num_of int i; P(i); P即求给定范围内满足
P逻辑的元素个数
操作符
-
==>: 蕴含操作符,逻辑同离散数学中使用 :
expr1 ==> expr2:- 当
expr1为真时,expr2为真时整个表达式为真,否则为假 - 当
expr1为假时,整个表达式为真
- 当
分析阶段
针对于类中的属性与方法从逻辑上分析出行为规范约束
对属性
对类中的每个属性成员,分析:
- 在可见状态下必须满足的不变特性
- 在一次值变化时必须要满足的状态变化约束
注 :
- 可见状态指的是属性的值时稳定的,当处于所有会修改成员变量的值的方法内部时都是不可见状态
- 在该层次分析的是属性成员必须在任何行为中满足的基本约束条件,不考虑细节,只是宏观的类决定的逻辑层次
对方法
对类中的每个定义的方法,分析:
-
输入参数要求 : 前置条件
将所有输入的范围划分为不重合的区间,划分依据如下 :
- 从方法正常执行的逻辑上要求调用者必须满足的输入条件
- 多种不合法的输入分别抛出不同类型的异常
注 : 最好可以做到是一个划分,即对所有可能输入的全覆盖
-
返回值要求 : 后置条件
要求方法实现者确保方法执行的结果一定要满足的条件
注 :
- 显式的针对于不是
void类型的方法,其他方法也有隐含的后置条件,不在返回值体现,在其他方面体现 - 后置条件满足的前提是调用者满足正确输入的前置条件
- 显式的针对于不是
-
实现过程要求 : 副作用限定 :
对方法实现过程中是否可以对对象的属性进行改变的限定
实现阶段
实现从逻辑上分析出来的约束条件的建模层次的描述
对属性
使用类型规格语法来描述
注 : 由于安全性要求的私有属性对外部不可见使用spec_public来标记在JML中可见
-
不变特性 : 使用不变式
invariant P描述p为描述属性在可见状态下的约束条件的布尔表达式例 :
public class Path{ private /*@spec_public@*/ ArrayList <Integer> seq_nodes; private /*@spec_public@*/ Integer start_node; private /*@spec_public@*/ Integer end_node; /*@ invariant seq_nodes != null && @ seq_nodes[0] == start_node && @ seq_nodes[seq_nodes.legnth-1] == end_node && @ seq_nodes.length >=2; @*/ }注 : 可以实现一个函数
boolean repOK()用来检查某一时刻的属性是否满足不变式,方便测试- 例如可以在每次更新之前来检查满足不变式
-
状态变化约束 : 使用状态变化约束
constraint P来描述p为描述属性当前可见状态和前序可见状态的关系的布尔表达式例 :
public class ServiceCounter{ private /*@spec_public@*/ long counter; //@ invariant counter >= 0; //@ constraint counter == \old(counter)+1; }
对方法
使用方法规格语法来描述
-
对输入参数使用前置条件语法
requires P来描述P为方法输入参数在某一区间满足的布尔表达式 -
对返回值使用后置条件语法
ensures P来描述P为方法正常执行时输出满足的布尔表达式\后置条件约束的可能形式 :
-
通过显示的
return和throw来返回结果 :return使用ensure + P(\result)来描述约束throw使用signals (***Exception e) b_expr来描述约束
-
通过修改所在
this对象的状态返回结果使用
ensure + P(this)来描述约束 -
通过修改方法的输入参数的内容来返回结果
使用
ensure + P(args)来描述约束
注 : 后置条件约束是构造性的,即不要描述生成结果的算法,只需描述结果的自己的性质(从数学角度来描述)即可
-
-
对实现过程使用副作用范围限定语法
assignable / modifiable elems来描述assignable表示可赋值的,modifiable表示可修改的,elems为其描述对象,即一个变量列表
注 :
-
对异常的处理 :
使用
signals语句来描述可能抛出异常根据输入分一个正常执行描述,若干个异常描述处理 :
- 使用
public normal_behavior接下来的描述正常执行 - 使用
public exceptional_behavior接下来的描述异常行为 - 不同段之间使用
also连接
- 使用
-
层次化的描述规格 :
-
引用依赖对象中的
public的数据规格来描述 -
借用已定义的
pure方法来描述 :pure方法的要求- 无副作用
- 任何情况下都有结果,即正常结束或者抛出异常,不会陷入内部死循环
- 规格逻辑比较简单
-
例 :
/*@ public normal_behavior
@ requires z <= 99;
@ assignable \nothing;
@ ensures \result > z;
@ also
@ public exceptional_behavior
@ requires z < 0;
@ assignable \nothing;
@ signals (IllegalArgumentException e) true;
@*/
public abstract int cantBeSatisfied(int z) throws IllegalArgumentException;
继承下的规格设计
数据
- 在继承下不能修改父类的数据规格
- 在继承下子类可以规定自己的独有数据并设定规格
方法
首先构造方法保证父类与子类的数据有效性恒成立
在继承下其他有三种规格的情况 :
- 直接继承父类的方法不做修改 : 子类不需要考虑,该方法的规格正确性有父类保证
- 自己定义自己独有的方法 : 子类设定自己的规格要求并实现
- 子类重写父类的规格 : 首先要求规格的定义不能矛盾,即要求符合
LSP原则,具体:- 前置条件 : 子类只能减弱父类的前置条件(即范围可以放宽但是不能缩小)
- 后置条件 : 子类只能加强父类的后置条件(即增加(
&&)更多条件)
注 : 当子类不能直接访问父类属性(即父类都为private无protected),只能通过父类满足规格(即一定保证数据有效性)的方法来访问数据时数据有效性很容易维护
JML工具链
OpenJML工具
使用OpenJML对程序进行分析
openjml -check <source files>: 对JML规格语言描述的语法正确性的检查,检查包括经典的类型检查、变量可见性与可写性等.openjml -esc <source files>: 对实际实现代码的静态检查,该静态检查不依赖于JML,只是检查程序的实现中是否有错误的风险,例如整数的减法溢出等openjml -rac <source fils>: 对实际实现代码的动态检查,该动态检查依赖于JML,判断该实现是否符合规格的要求
注意 : 该验证只是浅层次的,对复杂逻辑的正确性还是不能保证
JMLUnitNG
使用JMLUnitNG生成测试所用数据并测试代码
- 使用
jmlunitng <source file>根据源文件生成测试所需文件 - 使用
javac -cp jmlunitng.jar files编译生成的文件 - 使用
openjml -rac <source file>编译待测试源文件生成运行时检查文件 - 使用
java -cp jmlunitng.jar <test file>运行测试
JMLUnitNG测试用例
测试文件
package com.oocourse.specs3.models;
import java.util.ArrayList;
public class MyPath{
public int[] nodes;
public MyPath(int... nodeList) {
nodes = new int[150];
for (int i = 0; i < nodeList.length; i++)
{
nodes[i] = nodeList[i];
}
}
//@ ensures \result == nodes.length;
public /*@pure@*/int size() {
return nodes.length;
}
/*@ requires index >= 0 && index < size();
@ assignable \nothing;
@ ensures \result == nodes[index];
@*/
public /*@pure@*/ int getNode(int index) {
return nodes[index];
}
//@ ensures \result == (\exists int i; 0 <= i && i < nodes.length; nodes[i] == node);
public /*@pure@*/ boolean containsNode(int node) {
for (int i = 0;i < nodes.length ;i++ ) {
if (nodes[i] == node) {
return true;
}
}
return false;
}
//@ ensures \result == (nodes.length >= 2);
public /*@pure@*/ boolean isValid() {
return (size() >= 2);
}
}
测试过程
java -jar jmlunitng.jar demo/Demo.java
-
javac -cp .\jmuniting.jar -Djava.ext.dirs=.\lib testJML\MyPath_JML_Data\*.java testJML\*.javajava -jar E:\JML\openjml.jar -encoding utf-8 -rac testJML\MyPath.java
java -cp jmlunitng.jar -Djava.ext.dirs=.\lib testJML.MyPath_JML_Test
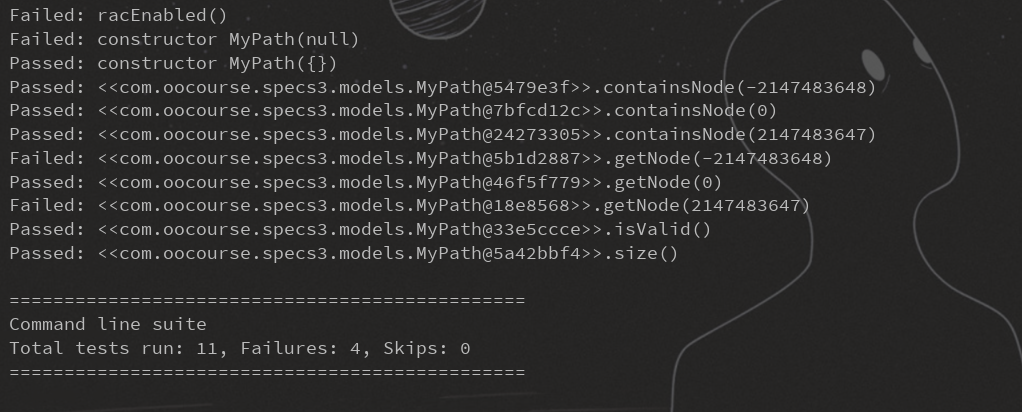
第一次作业
设计策略
MyPath
将MyPath设计为不可变对象 :
- 使用
ArrayList<Integer> nodes结构保存节点序列 - 内部维护一个
int distinctNodeCount来保存一个Path中的不同节点数目,该值在构造函数中初始化之后不再改变
MyPathContainer
- 使用
HashMap<Integer, Path> pathList与HashMap<Path, Integer> idList来实现Path与PathId的双向映射 - 使用
HashMap<Integer, Integer> nodeCount保存不同节点的出现次数
以上数据结构均在每次改变Container(即增加或者删除Path)时更新
基于度量分析
- 方法复杂度分析
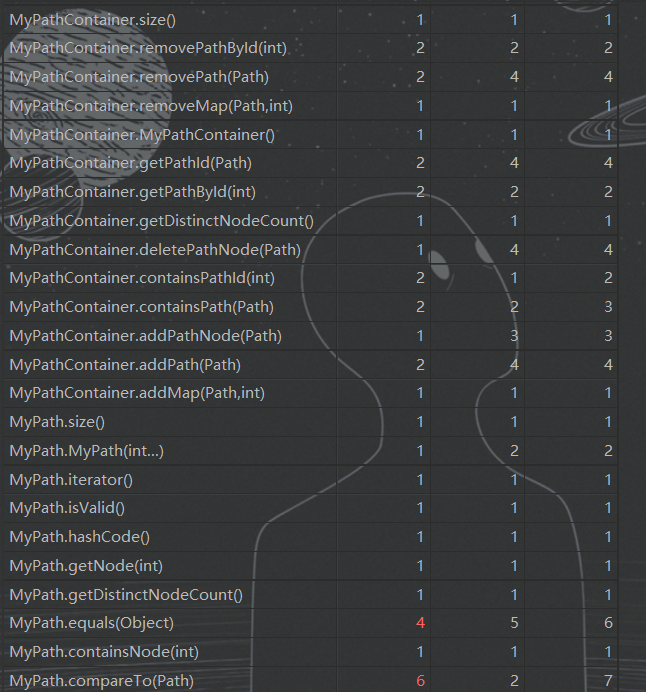
方法复杂度比较分散 - 类复杂度分析

类复杂度比较分散
第二次作业
设计策略
MyGraph
基于上次作业的MyPathContainer构建MyGraph,新增数据结构GraphData graphData
GraphData用来管理由路径容器生成的图的数据
GraphData
HashMap<Integer, Integer> nodeToIndex: 将整数类型范围内的节点离散化映射到0-120的范围内int [][] graph: 二维数据存储图的数据,值代表两个节点之间的路径数目int [][] dis: 二维数据存储最短路径,值代表两个节点之间的最短路径
以上数据结构均在每次改变Graph(即增加或者删除Path)时更新
最短路径算法
采用Floyd算法和BFS算法求最短路径
经过测试二者的性能在需求的数据范围内没有明显的差别
基于度量分析
- 方法复杂度分析
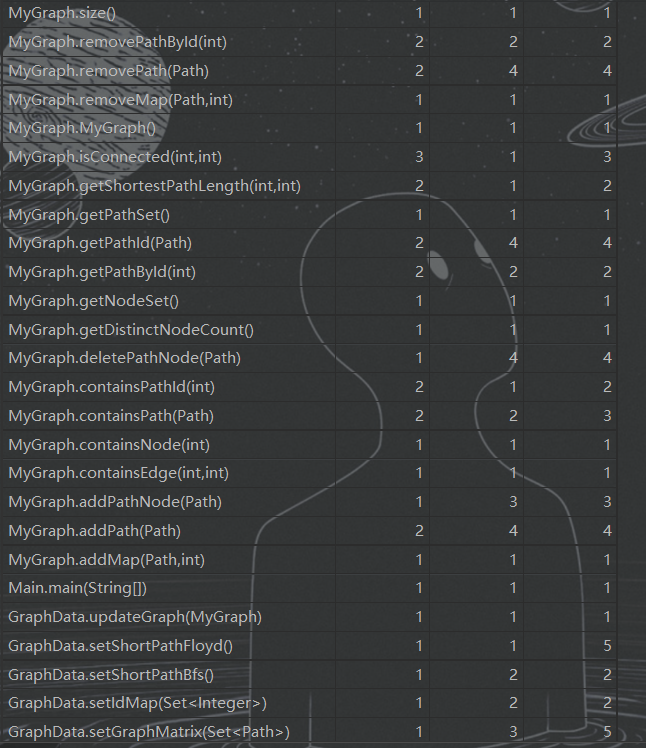
方法复杂度比较分散 - 类复杂度分析

可见出现了一点上帝类的征兆
第三次作业
设计策略
由于第二次作业中为了保证时间使用了静态数组作为邻接矩阵来表达图数据,该设计导致在第三次作业中进行扩展很不方便,因为在该次作业中节点集合是公有的,区别只是权值的不同,而使用静态数据的结构无法将节点集合与边集合二者分离开(现在想想当时应该果断重构的)最终使用了一种不太层次化的设计
设计思路
- 对每种功能需求建立一个图,图的边的矩阵的权值代表的含义即是需求(不满意度,票价,换乘次数)
- 对每个
Path的任意两点之间人为的添加一条路径,该路径的权值为在该Path中该两点之间的最短路径(基于权值的含义) - 当每次图进行改动时:
- 添加路径 : 先基于路径本身构建自身节点之间的最短路径图(基于权值含义)并将结果缓存,在将其合并(取小值)到总图中
- 删除路径 : 基于缓存重写生成功能图
- 每次查询时直接返回对应功能图中的数据即可
基于度量分析
- 方法复杂度分析
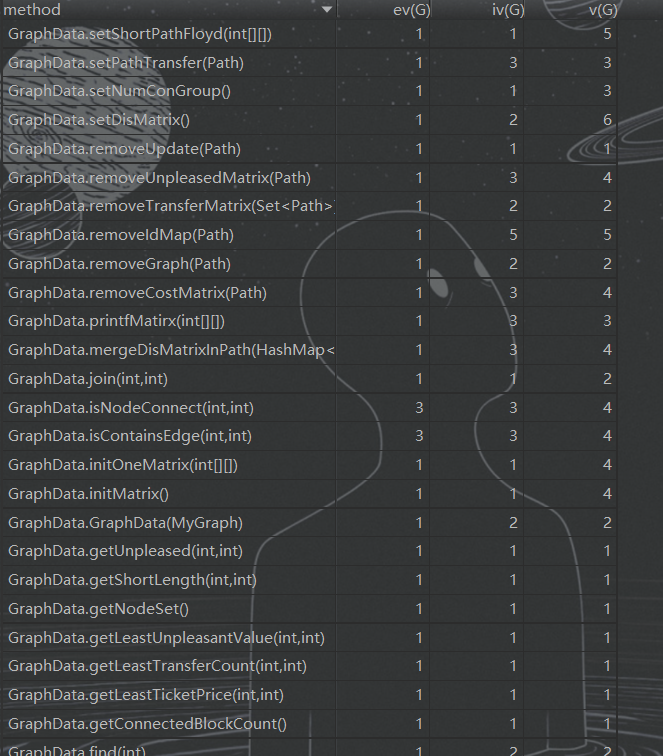
方法复杂度均摊 - 类复杂度分析
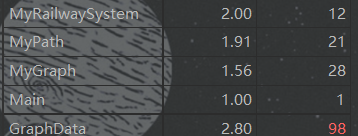
出现了上帝类,这个设计很糟糕
bug分析
第一次作业在公测与互测中均未被发现Bug
第二次作业在公测中未被发现Bug,在互测中被发现1个Bug
- 产生原因 : 当图结构改变时重新建立node到index的离散映射时没用清空原来的映射关系
- 修复 : 在每次重新建立映射前清空
HashMap
第三次作业在公测与互测中均未被发现Bug
心得体会
- 关于
JML:- 在写好规格的前提下实现程序还是很容易的,但是通过自己尝试定义规格发现规格的定义是很有难度的
JML只是对实现目标的需求描述,大多数是从数学层次上进行构造性描述的,在真正的实现过程中不能只拘泥于规格描述的数据结构,可以在合理的范围内加入更多的功能性数据结构
- 关于设计 :
- 我对本次的设计很不满意,导致这种后果主要有两个原因 :
- 由于过于重视对性能(即时间)的追求(主要是因为在本地时间与评测机时间不一致导致无法测试),导致选择了静态数组没有实现好的解耦合
- 没有在设计中留出足够好的扩展性,比如一直在当无向图处理,没有考虑转换为有向图的可能,没有考虑权值的多样性
- 由于在第3次没有果断重构导致后面也没有时间重构代码
- 在拜读了助教的标程之后,充分认识到了层次化化设计的强大之处 :
- 抽象数据模式 : 将图这一结构抽象出来,实现有向图与无向图两类
- 分离特性与共性 : 对图这一结构,节点集合一般是相同的,不同的只是边的结构,所以在一幅图中将二者分开
- 工厂模式根据路径集合建图
- 我对本次的设计很不满意,导致这种后果主要有两个原因 :
