

1.解释编译 :
计算机程序设计语言通常分为机器语言、汇编语言和高级语言三类。高级语言需要翻译成机器语言才能执行,而翻译的方式分为两种,一种是编译,另一种是解释。下面会总结编译和解释的区别。
编译的过程和解释的过程
编译(Compile)的过程是把整个源程序代码翻译成另外一种代码,翻译后的代码等待被执行或者被优化等等,发生在运行之前,产物是另一份代码。
解释(Interpret)的过程是把源程序代码一行一行的读懂,然后一行一行的执行,发生在运行时,产物是运行结果。
所以,编译和解释的输入都是源程序代码(有可能是源码,字节码等等),但是输出是不同的。有一张图可以比较形象的解释他们的区别:
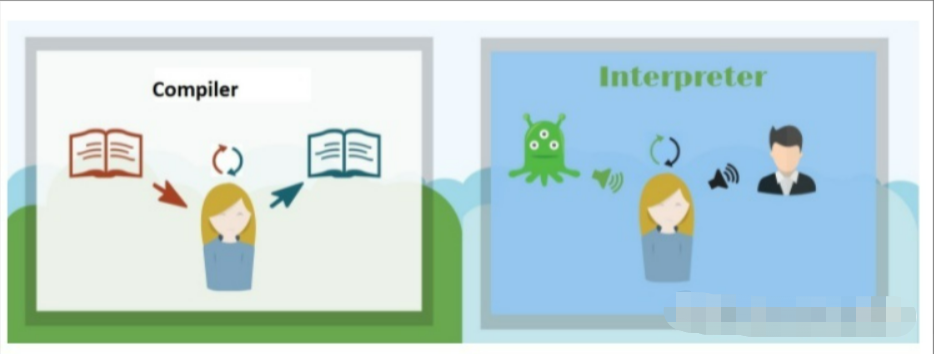
编译器和解释器
编译器(Compiler)是一种计算机程序,它会将某种编程语言编写的源代码(原始语言)转换成另一种编程语言(目标语言),其实就是完成上文中所说的编译的过程。主要目的是将便于人编写、阅读维护的高级计算机语言所编写的源代码程序,翻译为计算机能运行的机器语言程序。
解释器(interpreter),是一种计算机程序,能够把解释型语言解释执行。其实就是执行解释的过程。
编译器和解释器都是计算机程序,只不过他们运行不同过程。
编译型语言和解释型语言
语言一般只会定义其抽象语义,而不会强制性要求采用某种实现方式。理论上,任何编程语言都可以是编译型或解释型的。但是,会根据其主流实现方式来把语言分为“编译型语言”和“解释型语言”。
C/C++/C#等都是编译型语言。以C语言为例,源代码被编译之后生成中间文件(.o和.obj),然后用链接器和汇编器生成机器码,也就是一系列基本操作的序列,机器码最后被执行生成最终动作。
Lisp/R/Python等都是解释型语言。
其实许多编程语言同时采用编译器与解释器来实现,这就包括Python,Java等,先将代码编译为字节码,在运行时再进行解释。所谓“解释型语言”并不是不用编译,而只是不需要用户显式去使用编译器得到可执行代码而已 。
总结
编译和解释的过程上的区别:编译是将源程序翻译成可执行的目标代码,翻译与执行是分开的;而解释是对源程序的翻译与执行一次性完成,不生成可存储的目标代码。
编译和解释结果上的区别:编译的话会把输入的源程序翻译生成为目标代码,并存下来(无论是存在内存中还是磁盘上),后续执行可以复用;解释的话则是把源程序中的指令逐条解释,不生成也不存下目标代码,后续执行没有多少可复用的信息。
2.动静态 强弱型语言
概念:
动态语言:是运行时才确定数据类型的语言,变量在使用之前无需申明类型,通常变量的值是被赋值的那个值的类型。比如Php、Asp、JavaScript、Python、Perl等等。
var s ="hello"; var i = 0; var b = true;
静态语言:是编译时变量的数据类型就可以确定的语言,大多数静态语言要求在使用变量之前必须声明数据类型。比如Java、C、C++、C#等。
String s="hello"; //String 类型的变量 boolean b=true; //boolean 类型的变量 int i=0; //int 类型的变量
弱类型语言是数据类型可以被忽略的语言。一个变量可以赋不同数据类型的值。一个变量的类型是由其上下文决定的,效率更高。
强类型语言是必须强制确定数据类型的语言,一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这种数据类型,不允许隐式的类型转换。一个变量的类型是申明的时候就已经确定的,更安全。
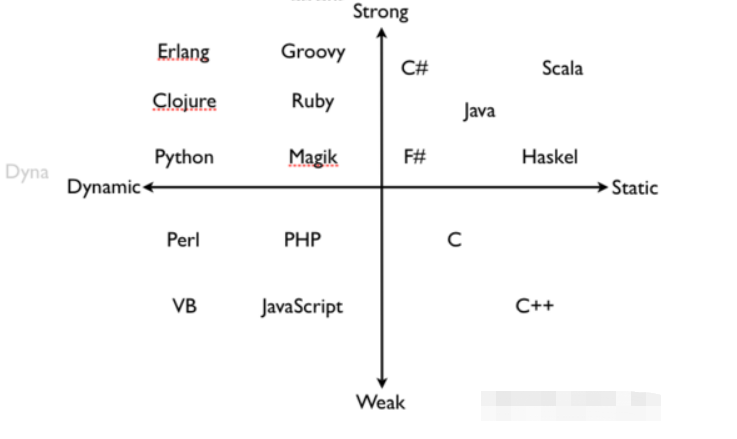
区别:
静态语言由于强制声明数据类型,让开发工具(IDE)对代码有很强的判断能力,在实现复杂的业务逻辑和开发大型商业系统、以及那些声明周期很长的应用中,开发者可以依托强大的IDE来更高效、更安全地开发。
动态语言思维不受约束,可以任意发挥,把更多的精力放在产品本身上;集中思考业务逻辑实现,思考过程就是实现过程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号