
集合类的由来:
JAVA是面向对象的,对象用来封装特有数据,对象多了就需要储存起来,当对象的个数不确定的时候,那么就用集合容器进行存储。
集合的特点:
1.集合的长度是可变的
2.用于存储对象的容器
3.不可以存储基本数据类型
体系:
集合容器因为内部的数据结构不同,有多种具体容器,不断的向上提取,形成了集合框架。
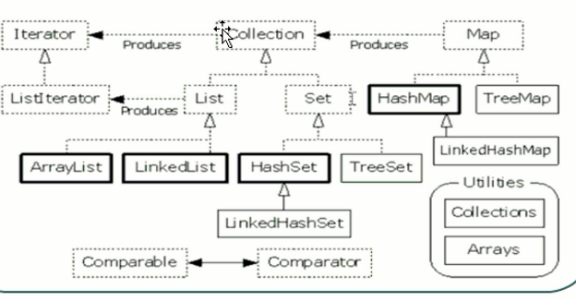
Collection接口:
常见的方法
1.增加
boolean add(Object obj)//添加一个对象 boolean addAll(Collection coll)//添加一个集合
2.删除
boolean remove(Object Obj)//删除一个对象 boolean removeAll(Collection coll)删除集合中所有与coll相同的对象 void clear()清空
3.判断
boolean contains(Object Obj)//判断一个对象是否存在 boolean containsAll(Collection coll)//判断集合中是否拥有coll总的所有对象 boolean isEmpty()//奇怪的很,没有元素返回true
4.获取
int size()//获取对象的个数 Iterator iterator()//获取对象,下面的代码是这个方法的实现
Iterator接口
对集合进行迭代迭代器
这个接口是对所有的Collection容器进行元素获取的公共接口
hasNext()如果next仍然有元素可以迭代,就返回true
next()返回迭代的下一个元素
方法一:
Iterator it = coll.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
方法二:节约空间,常用
for(Iterator it = coll.iterator();it.hasNext();){
System.out.println(it.next());
}
这种迭代的获取与直接打印( print(coll) )的区别在于,打印的是一串字符串,而迭代取得是单独的对象,可以对他们单独处理
5.其他
boolean retainAll(Collection coll)//取交集,删除与coll集合中不同的元素 Object toArray()//将集合转成数组
List:
1.有序(存入和取出顺序一致)
2.元素都有索引(脚标)
3.元素可以重复
常用子类:
1.Vector:内部是数组数据结构,同步的,增删查询都很慢。(基本淘汰)
2.ArrayList:内部是数组数据结构,不同步的,代替了Vector。查询很快
3.LinkedList:内部是链表数据结构的,不同步的。增删很快
常见的方法:
1.添加
void add(index,element)//在指定的位置插入对象 void add(index,collection)//在指定的位置插入集合
2.删除
Object remove(index)//删除指定位置的对象,返回值为被删除的对象
3.修改(只有List才具有增删改查,collection都不具备)
Object set(index,element)//返回值为被修改的对象,即修改前的对象
4.获取
Object get(index)//返回值为获取的对象 List subList(from,to)//返回指定范围的对象
int indexOf(Object)//返回对象的位置,从头开始找
int lastIndexOf(Object)//返回对象的位置,从尾开始找
list特有的取出元素的方法(只有list有set不具备):
for(int x=0;x<list.size();x++){
System.out.println(list.get(x));
}
ListIterator:
1.Iterator的子接口
2.可以实现在迭代过程中完成对元素的操作(增删改查)注意:只有List集合具备该迭代功能
如果有下面的代码(在迭代的过程中,增加元素)
Iterator it =list.iterator();
while(it.hasNext()){
Object obj=it.next();
if(obj=="b"){
list.add("e");
}else{
System.out.println(obj);
}
}
这里会发生异常,原因是在迭代的过程中,操作集合,产生了并发。
解决问题:
1.在迭代的时候不能操作集合,容易产生异常
2.使用ListIterator接口来完成在迭代过程中对元素的更多的操作
ListIterator it = list.listIterator();//获取列表迭代器对象
while(it.hasNext()){
Object obj=it.next();
if(obj=="b"){
it.add("e");
System.out.println(obj);
}else{
System.out.println(obj);
}
}
while(it.hasPrevious()){//如果前一个任然有元素可以迭代,那么就返回true
System.out.println(it.previous());//返回前一个元素
}
Enumeration:
1.这个接口淘汰了,基本不用
2.这个接口的功能与Iterator接口的功能是重复来的
3.Iterator接口添加了一个可选的移除操作,并且使用了较短的方法名。
4.新的实现应该考虑优先使用Iterator接口而不是Eumeration接口
elements:这个方法与List中的iterator方法有异曲同工之妙
Vector ve=new Vector();
ve.addElement("a");
ve.addElement("b");
ve.addElement("c");
Enumeration em=ve.elements();
while(em.hasMoreElements()){
System.out.println(em.nextElement());
}
Iterator it=ve.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
//这两个方法的作用基本一样,但是前一种基本上是淘汰了
LinkedList:
1.内部是链表数据结构,是不同步的,增删很快
2.堆栈:先进后出
队列:先进先出
3.常用方法
增加:
boolean add( Collection<? extends E> c)//在结尾添加一个元素
boolean addAll(int index, Collection<? extends E> c)//在指定位置插入一个集合
void addFirst(E o)//在开头加入一个元素
void addLast(E o)//在结尾加入一个元素
删除:
void clear()
E remove()
获取:
E getFirst()
E peek();
修改:
Object set(index,Objcet)
ArrayList:
下面的代码中的强转问题,可能会涉及到自动装箱问题,在这里也是可以使用的
ArrayList ar=new ArrayList();
Person a=new Person(19,"lao1");
Person b=new Person(16,"lao2");
Person c=new Person(11,"lao3");
ar.add(a);
ar.add(b);
ar.add(c);
for(Iterator it=ar.iterator();it.hasNext();){
//System.out.println(((Person)it.next()).getAge()+((Person)it.next()).getName());
//输出肯定是有问题的一直在next
//所以解决方法如下
Person d=(Person) it.next();//强转的原因是,在Aar.add()添加的时候,是使用Object接收的,所以person已经变成了上帝
System.out.println(d.getAge()+d.getName());
}
Set:
1.Set接口中的方法和Collection一致
2.Set获取元素的方法只有迭代器
3.常用实现子类HashSet,TreeSet
4.元素不可重复,无序(但是可以做到有限的有序)
HashSet:
1.内部数据结构是哈希表,不同步
2.如何保证该集合的元素唯一性呢?
a.通过对象的hashCode和equals方法来完成对象的唯一性
b.如果对象的hashCode值不同,那么不用判断equals方法,直接存储到嘻哈表中(int hashCode();boolean equals(Object obj))
c.如果对象的hashCode值相同,那么要再次判断对象的equals方法是否为true,true则视为相同元素,不存。
d.重点:如果元素要存储到HashSet集合中,必须覆盖hashCode方法和equals方法;一般情况下如果定义的类会产生很多对象,比如人,学生,书,通常都需要覆盖这两个方法,建立对象判断是否相同的依据。
e.扩展:Arraylist(如果要确保元素唯一的话)判断的依据是equals,而HashSet判断hashcode和equals
LinkedHashSet:
1.HashSet的直接已知实现子类
2.可以在唯一的情况下排序,怎么进就怎么出
HashSet/LinkedHashSet ha=new LinkedHashSet();
ha.add("a");
ha.add("d");
ha.add("s");
for(Iterator it=ha.iterator();it.hasNext();){
System.out.println(it.next());
}
//所以需要有序唯一的话可以直接使用LinkedHashSet类
TreeSet:
1.可以对set集合中的元素排序。是不同步的
2.判断元素唯一性的方式:就是根据比较方法返回结果是否为0,如果为0,就是相同元素,则不存储(所以要实现Comparable接口,覆盖compareTo方法元素和集合实现都可以;一般在做这一步的时候,也一起把排序给做了)
3.排序的两种方法
a.让元素自身具备比较功能
b.让集合自身具备比较功能(1.如果不按照对象具备的自然顺序排序2.对象不具备自然顺序;这两种情况时使用该功能)
4.比较器(即b)
定义一个类实现Comparator接口,覆盖compare方法,将该类对象最为参数传递给TreeSet集合的构造函数
//比较器,按照名字
class ComparatorByName implements Comparator {
public int compare(Object o1, Object o2) {
Person p1 = (Person)o1;
Person p2 = (Person)o2;
int temp = p1.getName().compareTo(p2.getName());
return temp==0?p1.getAge()-p2.getAge(): temp;
}
}
//比较器,按照年龄
class ComparatorByLength implements Comparator {
public int compare(Object o1, Object o2) {
Person s1 = (Person)o1;
Person s2 = (Person)o2;
int temp = s1.getAge()-s2.getAge();
return temp==0? s1.compareTo(s2): temp;
}
}
TreeSet tr=new TreeSet(new ComparatorByLength());//比较器的使用方法
Person a=new Person("lao3",11);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号