[笔记.Oracle.LogMiner]使用LogMiner捕获数据变化 - CDC/redo log/online在线日志/归档日志
前段时间在验证用LogMiner读取分析Oracle 的 redo log 文件,得到DML和DDL的变化信息。
通过网上的一些资料还是很容易跑通,但要用得比较顺畅还是经过了一番研究和验证。
其中字典的使用又是其中的一个关键,特将一些要点和自己的理解整理如下:

本文链接:[笔记.Oracle.LogMiner]使用LogMiner捕获数据变化-俊哥V-CSDN博客
字典特性:
1、三种类型字典:在线字典、InRedoLog模式、FlatFile模式
2、在线字典只有当前最新的对象信息;
3、InRedoLog模式、FlatFile模式都是要创建出字典文件(创建过程会消耗数据库资源,最好在非高峰期时间进行);
4、创建出的字典文件,包含了创建时刻及之前的对象信息;
5、InRedoLog模式,创建字典时会切换在线日志并归档,然后将字典数据写入刚生成的归档日志文件;
6、InRedoLog模式生成的字典数据有可能是包含在多个redo log文件中,该信息可以查询视图V$ARCHIVED_LOG(DICTIONARY_BEGIN='YES', DICTIONARY_BEGIN='YES')
6、InRedoLog模式生成字典时,是不能执行DDL语句的,所以该字典肯定能正常分析相应的归档日志(FlatFile则不能保证);
7、FlatFile模式不建议优先使用它,提供该方式可能很大程度是为了提供向前兼容。验证时发现,用它分析时会额外产生170+MB的归档文件,且偶发报错。
使用“合适”的字典:
1、在线日志分析,直接用在线字典。
2、分析在线日志时,如果发现所要分析表的结构发生改变,则无法正确得到该表的字段信息(名字和值)。可以创建InRedoLog 模式的字典来分析。
3、“合适”的时候创建 InRedoLog 字典,避免频繁切换在线日志以及带来的存储空间浪费(字典本身数据的空间占用)。
另外,官网有个图,说明该如何选择字典文件:
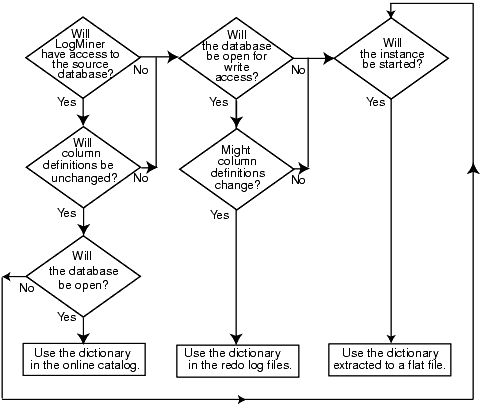
调用LogMiner分析日志:
1、在START_LOGMNR时应该只是做校验,根据查询条件检查是否包含了完整的日志文件。
a) 如果查询的时间范围或SCN超过了所添加日志的范围,则会报缺失日志文件;
b) 如果要分析DDL(指定了 DDL_DICT_TRACKING),那么需要添加的日志文件是连续完整的(添加顺序没要求,但需要加全),否则报缺失文件;
2、在每次查询V$LOGMNR_CONTENTS时会去实际分析日志文件内容。
3、在一个会话中,可以增删日志问文件,然后反复调用START_LOGMNR后去做查询。
4、特性1:加入了很多日志文件,是否都会去分析呢?
a) 实际要分析的日志文件是START_LOGMNR中过滤条件匹配的那些,未匹配上的不会去分析;
b) 查询V$LOGMNR_CONTENTS时给定的过滤条件,不会影响要分析的日志文件。即便按条件不会涉及的日志文件也会被纳入分析。
官网参考资料:
https://docs.oracle.com/en/database/oracle/oracle-database/19/sutil/oracle-logminer-utility.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号