redis系列:集群
1 简介
Redis 集群是Redis 的一个分布式实现,它是一个网状结构,每个节点都通过 TCP 连接跟其他每个节点连接。现在来看看Redis集群实现了哪些目标?
- 在1000个节点的时候仍能表现得很好并且可扩展性(scalability)是线性的。集群之间使用异步复制,并且没有合并的操作。
- 可接受的写入安全(Write safety)级别:那些与大多数节点相连的客户端所做的写入操作,系统尝试全部都保存下来。不过还是会有小部分写入会丢失。
- 可用性(Availability):在绝大多数的主节点(master node)是可达的,并且对于每一个不可达的主节点都至少有一个它的从节点(slave)可达的情况下,Redis 集群仍能进行分区(partitions)操作。
那么Redis集群环境与非分布式Redis环境在功能上有没有什么不同的呢?
- 集群的数据库只有0,且不支持SELECT
- 由于集群将键分布在不同的槽(slot)中,所以涉及到多键值的复制操作也是不支持的,像set里的并集(unions)和交集(intersections)操作
2 概念
在进入集群环境搭建时,先介绍集群的一些基本概念,例如节点、槽等等。
2.1 节点
节点(node)可以说是构成集群的基本元素.通常一个Redis集群中包含了多个节点,每个节点都有一个唯一的名字。
节点名字是一个十六进制表示的160 bit 随机数,这个随机数是节点第一次启动时获得的(通常是用 /dev/urandom)。 节点会把它的ID保存在配置文件里,以后永远使用这个ID.如果想要更换ID有如下两种方式:
- 删除掉节点配置文件。
- 执行
CLUSTER RESET命令。
那么这个节点ID有什么用处呢?
节点ID是用于每个节点。通过节点ID可以检测到节点 IP 或端口的变化。
如果节点发生了 IP 或端口变化时,其他节点是如何得知的呢?
集群会使用gossip 协议来发布广播消息,通知配置变更。
节点与节点之间知道对方的哪些信息?
-
节点的 IP 地址和 TCP 端口号。
-
各种标识。
-
节点使用的哈希槽。
-
最近一次用集群连接发送 ping 包的时间。
-
最近一次在回复中收到一个 pong 包的时间。
-
最近一次标识节点失效的时间。
-
该节点的从节点个数。
-
如果该节点是从节点,会有主节点ID信息。(如果它是个主节点则该信息置为0000000…)
我们可以通过使用CLUSTER NODES 命令可以获得以上的一些信息,如下

2.2 槽
Redis集群通过分片的方式来保存数据库中的键值对:整个键空间被分割为 16384 槽(slot),每个键都将存放在 16384 槽(slot)的其中一个位置上。
那么是什么决定一个键所存放的位置呢?
下方就是计算键存放的位置的算法。
HASH_SLOT = CRC16(key) mod 16384
通过CRC16算法获取键的16位输出结果,然后再对 16384 取余,结果就是键所在的位置。
既然整个键空间被分割为 16384 槽(slot),那么是如何将这些槽分配给不同的节点的?
可以通过以下命令将槽分片
CLUSTER ADDSLOTS slot1 [slot2] … [slotN]
3 搭建Redis集群
3.1 集群环境介绍
本文搭建的集群环境有3个主节点,每个主节点都有两个从节点,架构图如下
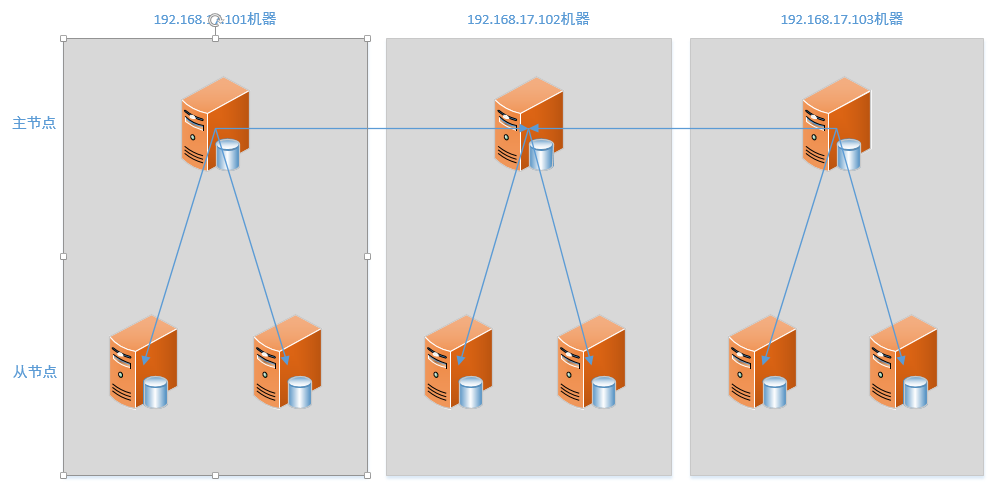
3.2 修改配置文件
关于集群的配置如下
################################ REDIS CLUSTER ###############################
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 5000
cluster-enabled 表示是否开启集群模式
cluster-conf-file 表示保存节点配置文件的路径
cluster-node-timeout表示节点超时时间
完整的配置文件在https://github.com/rainbowda/learnWay/tree/master/learnRedis/cluster ,有需要的可以去下载
3.3 节点配置及启动
由于采用一个服务器运行三个Redis实例,所以每个节点的配置有些许不同,像端口号、文件位置、文件名称等等。这里就不将每个配置文件贴出来了,Github上有主节点和两个从节点的配置文件。
我在redis文件夹下创建一个cluster文件夹,然后在cluster文件夹下创建一个master文件,存放主节点的配置文件master.conf和一些其他文件;再然后创建两个从节点文件7001和7002,也是存放配置文件等。
mkdir cluster
cd cluster
mkdir master 7001 7002
将配置文件拷贝到相应文件夹后,根据配置文件启动Redis,这里就不在说明了。
3.4 使用集群命令行工具redis-trib
我们已经有九个正在运行中的 Redis 实例 ,接下来需要使用这些实例来创建集群 。Redis中提供集群命令行工具 redis-trib 来简化集群操作
在执行redis-trib.rb文件之前需要安装ruby环境,嫌麻烦可以直接运行下面命令
yum install centos-release-scl-rh
yum install rh-ruby23 -y
scl enable rh-ruby23 bash
gem install redis
注:如果直接运行
yum install ruby命令时,再运行gem install redis会显示redis requires Ruby version >= 2.2.2错误
执行命令如下
./redis-trib.rb create --replicas 2 192.168.17.101:6379 192.168.17.102:6379 192.168.17.103:6379 192.168.17.101:7001 192.168.17.101:7002 192.168.17.102:7001 192.168.17.102:7002 192.168.17.103:7001 192.168.17.103:7002
命令中的create表示创建集群 ,参数 replicas表示需要一个主节点有几个从节点 ,后面就是节点ip和端口号。
命令执行后,会输出已下内容,内容里面包括主从节点的信息
接下来需要用户输入yes确认
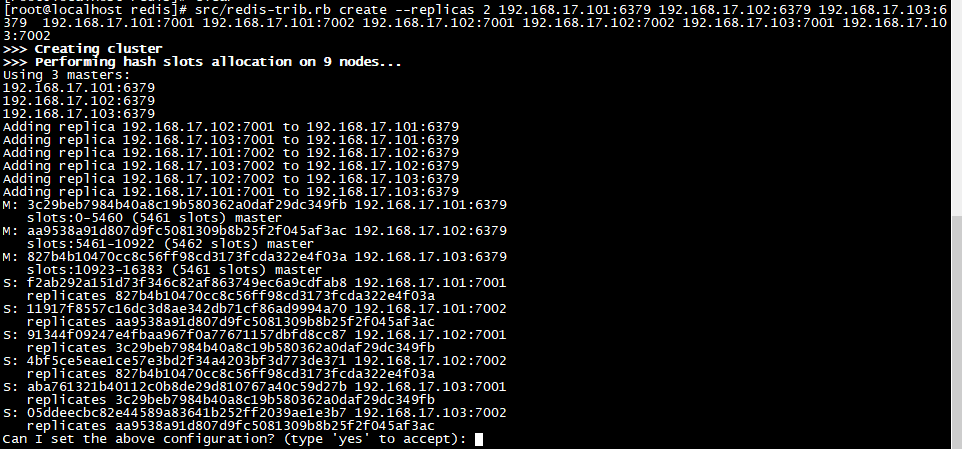
输入yes后, redis-trib 就会将这份配置应用到集群当中,让各个节点开始互相通讯,最后可以得到如下信息:
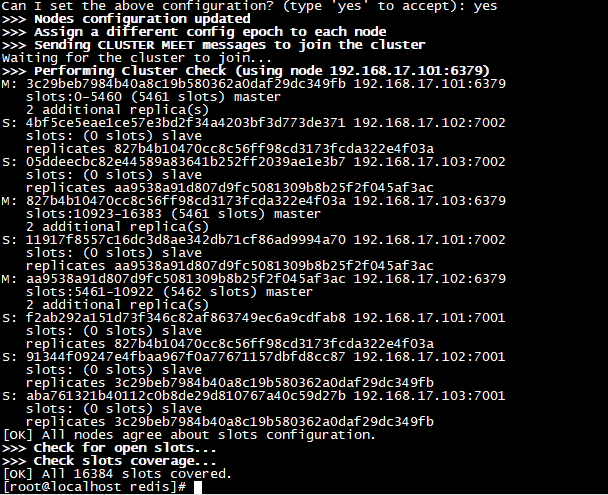
当输出已下内容时,表示集群环境已经搭建好了
[OK] All 16384 slots covered
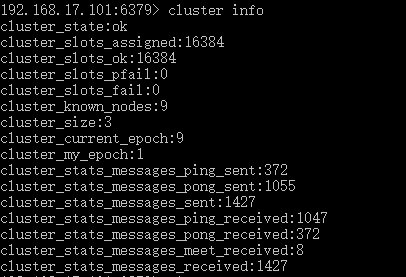
接下来输入cluster info命令看看集群状态,输出的结果如下
3.5 集群搭建过程
在使用redis-trib创建集群时,我们并不知道其内部发生了什么,接下来我将简单介绍下其过程。
- 接收到redis-trib创建集群命令后,检查传入的master节点数量是否大于等于3个。只有大于3个节点才能组成集群 。
- 计算每个主节点需要分配的槽数量,以及给主节点分配从节点。
- 输出分配的信息,等待用户输入
yes确认分配方案。 - 用户输入
yes之后,便开始执行分配方案。 - 给主节点分配槽。
- 从节点复制主节点。
- 让节点加入到同一个集群中。(发送cluster meet 命令)
大致的过程如上,接下来介绍下cluster meet 命令
3.6 CLUSTER MEET 命令
在没有使用 CLUSTER MEET 命令时,每个节点都是相互独立的, 它们都处于一个只包含自己的集群当中,通过使用 CLUSTER MEET 命令可以将各个独立的节点连接起来, 构成一个包含多个节点的集群 。使用 CLUSTER MEET 命令的格式如下
CLUSTER MEET <ip> <port>
看看这个命令的实现
3.7 CLUSTER MEET 命令实现
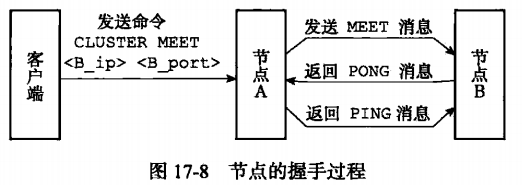
场景:有A(192.168.17.101)和B(192.168.17.102)两个节点,在B节点的客户端输入CLUSTER MEET 192.168.17.101 6379 ,表示B加入到A所在的集群中。A收到命令后便开始执行以下步骤
- 节点A为B创建一个节点结构,并添加到自己的节点字典中。
- 节点A向节点B发送一条MEET消息(消息后面会说明)
- 当节点B收到节点A的MEET消息时,节点B也会为A创建一个节点结构,并添加到自己的节点字典中。
- 节点B向节点A回复一条PONG消息。
- 当节点A收到节点B回复的PONG的消息时,表示节点B已经成功收到自己发送的MEET消息。
- 这时节点A会向节点B返回PING消息。
- 当节点B收到节点A返回的PING消息时,握手完成。
节点的握手过程如下
4 故障检测和转移
这里将模拟一个主节点故障,通过向主节点发送DEBUG SEGFAULT 命令来实现主节点故障效果。
在主节点101上执行DEBUG SEGFAULT命令之后,到103客户端上查看节点状态

可以从上图中看出101主节点多了个fail状态,而且103的一个从节点7001变成了主节点。现在再让101重新上线,再次查看状态

可以看到之前的101主节点变成了从节点。好了接下来看看集群是怎么发现故障及故障如何转移的。
4.1 故障检测
集群是通过什么方式来发现某个节点出现故障?
答:可以分为如下几个步骤.
定义:发送PING消息的节点-->节点A;接受PING消息的节点-->节点B
- 集群中的A节点向B节点发送PING消息
- 如果节点B没有在
NODE_TIMEOUT时间内返回PONG消息,那么节点A会将B节点标记为PFAIL** (疑似下线状态) - 节点 A 通过 gossip 字段收集到集群中大部分主节点标识的节点 B 的状态信息。
- 如果大部分主节点标记节点 B 为 PFAIL 状态,或者在
NODE_TIMEOUT *FAIL_REPORT_VALIDITY_MULT这个时间内是处于 PFAIL 状态。那么节点A会标记节点 B 为 FAIL (已下线状态)。 - 节点A向所有可达节点发送一个节点 B的 FAIL 消息 。
4.2 故障转移
故障转移步骤:
-
下线主节点的所有从节点,会有一个从节点被选中。
-
被选中的从节点会执行
SLAVEOF no one命令,成为新的主节点 -
新的主节点会撤销所有对已下线主节点的槽指派,并将这些槽全部指派给自己。
-
新的主节点向集群广播一条PONG消息,这条消息可以让集群中的其他节点立即知道这个节点已经由从节点变成了主节点,并且这个主节点已经接管了原本由已下线节点负责处理的槽。
-
新的主节点开始接收和自己负责处理的槽有关的命令请求,故障转移完成。
以下就是发生故障出现日志内容
2169:M 31 Jul 21:06:20.873 * Marking node 3c29beb7984b40a8c19b580362a0daf29dc349fb as failing (quorum reached).
2169:M 31 Jul 21:06:20.873 # Cluster state changed: fail
2169:M 31 Jul 21:06:21.546 # Failover auth granted to aba761321b40112c0b8de29d810767a40c59d27b for epoch 10
2169:M 31 Jul 21:06:21.586 # Cluster state changed: ok
2169:M 31 Jul 21:13:05.849 * Clear FAIL state for node 3c29beb7984b40a8c19b580362a0daf29dc349fb: master without slots is reachable again.
这篇文章主要介绍集群搭建和故障检测转移,当然集群中还有其他知识点像MOVED 重定向、ASK 重定向和重新分片等功能,这些功能官方文档都有相应的资料。
Redis官网:https://redis.io
Redis中文网:http://www.redis.cn
本篇的集群配置文件:https://github.com/rainbowda/learnWay/tree/master/learnRedis/cluster
作者: 云枭zd
Github: Github地址
出处: https://www.cnblogs.com/fixzd/
版权声明:本文欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则视为侵权。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号