redis系列:RDB持久化与AOF持久化
前言
什么是持久化?
持久化(Persistence),即把数据(如内存中的对象)保存到可永久保存的存储设备中(如磁盘)。持久化的主要应用是将内存中的对象存储在数据库中,或者存储在磁盘文件中、XML数据文件中等等。
持久化是将程序数据在持久状态和瞬时状态间转换的机制。 ----摘自百度百科
Redis的数据都是存储在内存中的,所以Redis持久化也就是要把Redis存储在内存中的数据保存到硬盘。
Redis提供了两种持久化方式
- RDB持久化(快照)
- AOF持久化(只追加操作的文件 Append-only file)
先来看看RDB持久化
RDB持久化
RDB持久化是指在客户端输入save、bgsave或者达到配置文件自动保存快照条件时,将Redis 在内存中的数据生成快照保存在名字为 dump.rdb(文件名可修改)的二进制文件中。
save命令
save命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止,在Redis服务器阻塞期间,服务器不能处理任何命令请求。
在客户端输入save
192.168.17.101:6379> save
OK
服务端会出现下方字符
1349:M 30 Jul 17:16:48.935 * DB saved on disk
bgsave命令
bgsave命令的工作原理如下
- 服务器进程pid为1349派生出一个pid为1357的子进程,
- 子进程将数据写入到一个临时 RDB 文件中
- 当子进程完成对新 RDB 文件的写入时,Redis 用新 RDB 文件替换原来的 RDB 文件,并删除旧的 RDB 文件。
在客户端输入bgsave
192.168.17.101:6379> bgsave
Background saving started
服务端会出现下方字符
1349:M 30 Jul 17:14:42.991 * Background saving started by pid 1357
1357:C 30 Jul 17:14:42.993 * DB saved on disk
1357:C 30 Jul 17:14:42.993 * RDB: 4 MB of memory used by copy-on-write
1349:M 30 Jul 17:14:43.066 * Background saving terminated with success
注:bgsave命令执行期间
SAVE命令会被拒绝
不能同时执行两个BGSAVE命令
不能同时执行BGREWRITEAOF和BGSAVE命令
自动保存
这个需要在配置文件redis.conf中修改,默认的保存策略如下
save 900 1 # 900 秒内有至少有 1 个键被改动
save 300 10 # 300 秒内有至少有 10 个键被改动
save 60 10000 # 60 秒内有至少有 1000 个键被改动
接下来看看RBD的配置有哪些
配置
################################ SNAPSHOTTING ################################
# 触发自动保存快照
# save <seconds> <changes>
# save <秒> <修改的次数>
save 900 1
save 300 10
save 60 10000
# 设置在保存快照出错时,是否停止redis命令的写入
stop-writes-on-bgsave-error yes
# 是否在导出.rdb数据库文件的时候采用LZF压缩
rdbcompression yes
# 是否开启CRC64校验
rdbchecksum yes
# 导出数据库的文件名称
dbfilename dump.rdb
# 导出的数据库所在的目录
dir ./
优点
- RDB是一个非常紧凑(有压缩)的文件,它保存了某个时间点的数据,非常适用于数据的备份。
- RDB作为一个非常紧凑(有压缩)的文件,可以很方便传送到另一个远端数据中心 ,非常适用于灾难恢复.
- RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能.
- 与AOF相比,在恢复大的数据集的时候,RDB方式会更快一些.
翻译来自http://www.redis.cn
缺点
- Redis意外宕机 时,会丢失部分数据
- 当Redis数据量比较大时,fork的过程是非常耗时的,fork子进程时是会阻塞的,在这期间Redis 是不能响应客户端的请求的。
AOF持久化
AOF持久化是通过保存Redis服务器所执行的写命令来记录数据库状态,也就是每当 Redis 执行一个改变数据集的命令时(比如 SET), 这个命令就会被追加到 AOF 文件的末尾。
那么我们如何开启AOF持久化功能呢?
开启AOF持久化
修改redis.conf配置文件,默认是appendonly no(关闭状态),将no改为yes即可
appendonly yes
在客户端输入如下命令也可,但是Redis服务器重启后会失效
192.168.17.101:6379> config set appendonly yes
OK
接下来看看AOF持久化功能的实现
实现
AOF持久化功能的实现可以分为命令追加(append)、文件写入和文件同步(sync)三个步骤。下面就是三个步骤的整个过程。
在Redis客户端输入如下命令
192.168.17.101:6379> set learnRedis testAOF
OK
appendonly.aof文件会增加如下内容
*2
$6
SELECT
$1
0
*3
$3
set
$10
learnRedis
$7
testAOF
命令追加
AOF持久化功能开启时,服务器在执行完一个写命令之后,会以协议格式将被执行的写命令追加到服务器状态的aof_buf缓冲区的末尾。此时缓冲区的记录还没有写入到appendonly.aof文件中。
文件的写入和同步
为什么将文件写入和文件同步合在一块讲呢?因为配置文件中提供了一个appendfsync参数,这个参数控制着文件写入和同步的行为。
关于文件的写入和同步的资料如下
因为为了提高文件的写入效率,在现代操作系统中,当用户调用write函数,将一些数据写入到文件的时候,os通常会将写入数据暂时保存在一个内存缓冲区里面(例如,unix系统实现在内核中设有缓冲区高速缓存或页高速缓存,当我们向文件写入数据时,内核通常先将数据复制到缓冲区中,然后排入队列,晚些时候再写入磁盘),这种方式称为延迟写,等到缓冲区的空间被填满,或者超过了指定的时限,或者内核需要重用缓冲区存放其它磁盘块数据时,才会真正将缓冲区中的所有数据写入到磁盘里面。
简单来说就是
文件写入:只是写入到了内存缓冲区,可能还没有写到文件所拥有的磁盘数据块上
文件同步:将缓冲区中的内容冲洗到磁盘上
appendfsync参数
| appendfsync选项的值 | 效果 |
|---|---|
| always | 每次有新命令时,就将缓冲区数据写入并同步到 AOF 文件 |
| everysec(默认) | 每秒将缓冲区的数据写入并同步到 AOF 文件 |
| no | 将缓冲区数据写入AOF 文件,但是同步操作到交给操作系统来处理 |
载入与数据还原
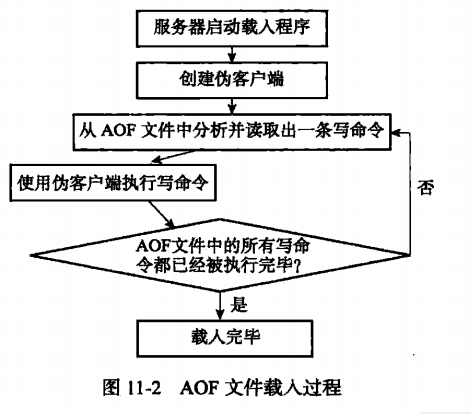
读取AOF文件并还原数据库的步骤如下
- 创建一个不带网络连接的伪客户端
- 从AOF文件中分析并读取出一条写命令
- 使用伪客户端执行被读出的写命令
- 一直执行步骤2、3,知道AOF文件中的所有写命令都被处理完毕为止
这时可能会出现一个问题。服务器可能在程序正在对 AOF 文件进行写入时停机,造成了 AOF 文件出错,那么 Redis 在重启时会拒绝载入这个 AOF 文件,从而确保数据的一致性不会被破坏 当发生这种情况时, 可以用以下方法来修复出错的 AOF 文件:
- 为现有的 AOF 文件创建一个备份。
- 使用 Redis 附带的 redis-check-aof 程序,对原来的 AOF 文件进行修复: redis-check-aof –fix
- (可选)使用 diff -u 对比修复后的 AOF 文件和原始 AOF 文件的备份,查看两个文件之间的不同之处。
- 重启 Redis 服务器,等待服务器载入修复后的 AOF 文件,并进行数据恢复。
另外redis.conf配置文件中还提供了一个参数来控制是否忽略最后一条可能存在问题的指令,如下
aof-load-truncated yes
重写
由于AOF 持久化是通过不断地将命令追加到文件的末尾来记录数据库状态的, 所以随着写入命令的不断增加, AOF 文件的体积也会变得越来越大。 且有些命令是改变同一数据,是可以合并成一条命令的。就好比对一个计数器调用了 100 次 INCR,AOF就会存入100 条记录,其实存入一条数据就可以了。
所以为了处理这种情况,Redis提供了AOF重写机制。
AOF重写机制的触发有两种机制,一个是通过调用命令BGREWRITEAOF
192.168.17.101:6379> BGREWRITEAOF
Background append only file rewriting started
另一种是根据配置文件中的参数触发,参数如下
auto-aof-rewrite-percentage 100 #当前AOF文件大小和上一次重写时AOF文件大小的比值
auto-aof-rewrite-min-size 64mb #文件的最小体积
服务端会出现如下信息
1349:M 30 Jul 17:19:25.311 * Background append only file rewriting started by pid 1392
1349:M 30 Jul 17:19:25.379 * AOF rewrite child asks to stop sending diffs.
1392:C 30 Jul 17:19:25.379 * Parent agreed to stop sending diffs. Finalizing AOF...
1392:C 30 Jul 17:19:25.380 * Concatenating 0.00 MB of AOF diff received from parent.
1392:C 30 Jul 17:19:25.380 * SYNC append only file rewrite performed
1392:C 30 Jul 17:19:25.381 * AOF rewrite: 4 MB of memory used by copy-on-write
1349:M 30 Jul 17:19:25.466 * Background AOF rewrite terminated with success
1349:M 30 Jul 17:19:25.467 * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
1349:M 30 Jul 17:19:25.467 * Background AOF rewrite finished successfully
重写步骤
- 创建子进程进行AOF重写
- 将客户端的写命令追加到AOF重写缓冲区
- 子进程完成AOF重写工作后,会向父进程发送一个信号
- 父进程接收到信号后,将AOF重写缓冲区的所有内容写入到新AOF文件中
- 对新的AOF文件进行改名,原子的覆盖现有的AOF文件
注:AOF重写不需要对现有的AOF文件进行任何读取、分析和写入操作。
配置
############################## APPEND ONLY MODE ###############################
# 是否开启AOF功能
appendonly no
# AOF文件件名称
appendfilename "appendonly.aof"
# 写入AOF文件的三种方式
# appendfsync always
appendfsync everysec
# appendfsync no
# 重写AOF时,是否继续写AOF文件
no-appendfsync-on-rewrite no
# 自动重写AOF文件的条件
auto-aof-rewrite-percentage 100 #百分比
auto-aof-rewrite-min-size 64mb #大小
# 是否忽略最后一条可能存在问题的指令
aof-load-truncated yes
优点
- 使用AOF 会让你的Redis更加持久化
- AOF文件是一个只进行追加的日志文件,不需要在写入时读取文件。
- Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写 。
- AOF文件可读性高,分析容易
缺点
- 对于相同的数据来说,AOF 文件大小通常要大于 RDB 文件
- 根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB
数据载入
RDB和AOF都是在启动时加载的,AOF开启时,会优先从AOF文件从恢复数据 ,AOF关闭时才会从RDB文件恢复数据。
注:不知从什么版本开始,开启AOF功能时AOF文件不存在也不会加载RDB文件了
作者: 云枭zd
Github: Github地址
出处: https://www.cnblogs.com/fixzd/
版权声明:本文欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则视为侵权。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号