一文弄懂js的执行上下文与执行上下文栈
执行上下文与执行上下文栈
变量提升与函数提升
变量提升
通过var关键字申明的变量,能够在定义语句之前访问到,值为undefined
console.log(a) // undefined
var a = 'Fitz'
// 以上代码的真正过程是:
var a
console.log(a)
a = 'Fitz'

函数提升
通过function关键字申明的函数,能够在函数定义前,成功完整的执行
// 在函数申明之前调用
sayName('Fitz') // 'Fitz'
function sayName (myName) {
console.log(myName)
}
// 以上代码的真正过程是:
function sayName (myName) {
console.log(myName)
}
sayName('Fitz') // 'Fitz'

注意: 函数提升必须是通过function关键字申明,使用直接量申明的函数不行,因为这样申明其实就是普通的变量申明,符合的是变量提升的情况
func() // 报错: func is not a function
var func = function () {
console.log('你好')
}
变量提升与函数提升的优先级
介绍完变量提升与函数提升,有人可能就会问: 如果我的变量名和函数名是一样的,那么哪个会被覆盖?(谁会成为最后的对象)
关于这个探究两者优先级的问题,我直接先说结论: 先执行函数提升,再执行变量提升
请牢记这个结论,接着来给大家上两道内心直喊WTF的题目
先看题目1:
var a = 123
function a () {
console.log('a()')
}
console.log(a) // 猜猜结果是啥
a() // 猜猜结果是啥
上面题目正确答案
var a = 123
function a() {
console.log('a()')
}
console.log(a) // 123
a() // 报错: a is not a function

为什么是这样呢,我来分析一下:
根据结论: 是先执行函数提升,再执行变量提升
根据结果,这结论完全是错误的呀,先别急
关于变量提升与函数提升完整的结论是这样的:
- 先执行函数提升,再执行变量提升
- 变量申明不会覆盖函数申明,如果同名变量申明会被忽略
- 变量赋值会覆盖函数申明(赋值)
于是根据完整的结论, 即题目的代码真正执行流程是这样的:
function a() { // 函数提升
console.log('a()')
}
var a // 变量提升 不会覆盖上面的函数
a = 123 // 函数a被重新赋值成了一个Number类型的数据(123), 因为变量赋值会覆盖函数申明(赋值)
console.log(a) // 123
a() // 报错: a is not a function
感觉良好?,快来看看题目2:
var a
function a() { }
console.log(typeof a) // 猜猜结果是啥
上面题目答案
var a
function a() { }
console.log(typeof a) // 'function'
是不是心中千万匹草泥马奔腾着,不管怎样跟着结论咱分析怎么回事,根据结论这道题目代码执行的流程应该是这样的:
function a() { } // 先函数提升
var a // 再变量提升 但是由于重名,编译器会忽略这次的变量申明
console.log(typeof a) // 'function'
所以记住完整结论是最重要的,不然遇到类似这两个题目,虽然知道有坑,但是大概率还是会直接往里面跳
最后给大家再来道题目巩固一下:
var c = 1
function c(c){
console.log(c)
}
c(2) // 结果是啥
跟着结论走,这些大家总不会出错了吧,还是错了的自觉在文章后面发评论!
var c = 1
function c(c){
console.log(c)
}
c(2) // 报错: c is not a function
// 上面代码的实际执行过程
function c(c){
console.log(c)
}
var c // 记住: 同名的变量申明会被忽略
c = 1
c(2) // 此时c是Number类型,值为1 不能作为函数执行!
变量提升的一道题目引出var关键字与let关键字各自的特性
话不多说,先上题目
if (!(b in window)){
var b = 1
}
console.log(b) // 结果是啥
答案是输出undefined
我大胆猜想,肯定有人的答案是: 报错
报错的人应该的想法跟我刚开始想的是一样的,但是忽略了var关键字的特性,那就是var关键字没有块级作用域
什么是块级作用域呢,它不同于函数作用域和全局作用域这种大的范围,在我的认知里,块级作用域指的就是for循环和if语句大括号里面的作用域
既然var没有块级作用域,那么if的一对大括号自然束缚不了它,所以题目代码的执行流程是这样的
var b
if (!(b in window)){ // window已经有b变量, 值为undefined
b = 1
}
console.log(b) // undefined
var关键字没有块级作用域,就引发了另一个经典问题: for循环的索引问题
for (var i=0; i<10; i++){
setTimeout(
()=>{
console.log(i) // 猜猜结果
},
2000
)
}
答案是: 大约在2s后直接输出10个10
这里的大约是为了更严谨一点,毕竟定时器在JS中也是个大坑呢,这个坑留着以后再填,现在还是先关注for循环索引的问题
引发这个问题的原因恰恰就是因为var关键字没有块级作用域,当定时器异步执行时,同步执行的for早已经执行完毕了,此时i早已经变成了10了,所以最终10个定时器输出的i就全部都是10了
那有什么方法解决呢? 我这里又引出另一个大坑----闭包,利用闭包的特性我们就能够解决这个问题
for (var i = 0; i < 10; i++) {
(function (outerIAsParm) {
setTimeout(
() => {
console.log(outerIAsParm)
},
2000
)
})(i) // 闭包产生
}
利用闭包解决这个问题显得有些复杂,况且闭包的概念还在难为我等一众新手,后面我也会对闭包的概念作出我的总结,大家也可以移步去看一下
那么还有什么方法更快速的解决这个问题呢?
最开始提到的,ES6中的let关键字就能解决,let关键字与var关键字有很大的不相同,这里不多介绍,重点介绍其中一个,let有其自己的块级作用域,这使得每次for循环的i都能被顺利被里面的定时器读到并保存。这有一个概念叫let的死域(这跟下面执行上下文部分要介绍的词法环境有关)
for (let i = 0; i < 10; i++) {
setTimeout(
() => {
console.log(i)
},
2000
}
执行上下文
开头先说结论: 变量提升与函数提升就是由于执行上下文导致的
根据代码编写的位置,与作用域一样,分为全局代码和局部代码
代码编写位置的不同,导致了执行上下文也分为了全局执行上下文与函数(局部)执行上下文两个
全局执行上下文
全局执行上下文是在全局的代码执行前,JS引擎自动进行的工作,它的工作有以下几部分
首先: 将window对象指定为全局执行上下文对象, 即: globalContext是window对象
console.log(window) // window
接着: 对在全局作用域中的数据进行预处理
-
收集所有在
全局作用域中使用var关键字定义的变量,将值赋值为undefined,并添加成为全局执行上下文对象window的属性 -
收集所有在全局作用域中使用function关键字申明的函数,添加成为
全局执行上下文对象window的方法 -
将上下文对象指向全局执行上下文对象, 即: this = window
最后: 开始执行全局代码,变量赋值的正常赋值,语句、表达式等执行的执行
所以根据以上概念,这个例子的代码执行应该是这样的
console.log(a) // undefined
test() // 'Fitz'
var a = 123
function test () {
console.log('Fitz')
}
// 真正代码执行过程应该是这样的
window.test = function () {
console.log('Fitz')
}
var a
console.log(a) // undefined
test() // 'Fitz'
a = 123
函数(局部)执行上下文
在调用函数,即准备执行函数体中的代码前,会创建函数的执行上下文对象,自动进行以下几部分的工作
首先: 对函数内部中的变量、参数进行预处理
-
形参变量会被赋值成实参的值,然后添加成为函数执行上下文对象的属性
function test (parm){} test(1) // parm在函数执行上下文时, 就是parm = 1 -
arguments对象被赋值由实参组成的伪数组,然后添加成为函数执行上下文对象的属性
function test (parm){ console.log(arguments) } test(1,2,3)
-
var关键字申明的变量与function关键字申明的函数,与全局执行上下文状况类似,但是被限制在了函数作用域中function test () { console.log(a) // undefined innerFunc() // 'hello' function innerFunc() { console.log('hello') } var a = 'haha' } test()
接着: 上下文对象根据调用函数的对象,动态变化 即: this是动态变化的,详细请了解我的this的指向相关笔记
最后: 开始执行函数体代码
所以根据以上概念,这个例子的代码执行应该是这样的
function func(a1) {
console.log(a1) // 666
console.log(a2) // undefined
a3() // a3()
console.log(this) // window
console.log(arguments) // 伪数组中有元素666 888
var a2 = 3
function a3() {
console.log('a3()')
}
}
func(666, 888)
// 以上代码的真正过程是:
function func(a1) {
/*
`var`关键字申明的变量与`function`关键字申明的函数,与全局执行上下文状况类似,但是被限制在了函数作用域中
*/
function a3() {
console.log('a3()')
}
var a2
console.log(a1) // 形参被实参赋值 a1 = 666
console.log(a2) // undefined
a3() // a3()
console.log(this) // 上下文对象根据调用函数的对象动态变化,这里属于默认绑定的情况 this => window
console.log(arguments) // arguments对象被赋值由实参组成的伪数组
a2 = 3
}
func(666, 888) // 只有到了调用函数这一步。才会在执行函数内语句前,自动进行上面介绍的那些函数执行上下文的操作
详细介绍执行上下文的过程
上面已经介绍完全局执行上下文和函数执行上下文在创建时会自动进行哪些工作,但是在这我们还将进行深入去剖析执行上下文对象在创建时究竟发生了什么(即上面介绍的那些步骤,在这是怎样的一个过程)
先声明这一部分的知识来自于博主: 听风是风博主的《一篇文章看懂JS执行上下文》
执行上下文对象的创建分为两个阶段: 创建阶段 和 执行阶段
执行阶段就是全局代码的执行或函数调用执行,没什么好介绍的。那么重点就放在创建阶段上
创建阶段
创建阶段主要负责三件事:
- 确定this
- 创建词法环境组件(LexicalEnvironment)
- 创建变量环境组件(VariableEnvironment)
对应这上面介绍的步骤(首先..., 接着..., 最后...)
引用参考博客中的伪代码来展示这个创建过程:
ExecutionContext = {
// 确定this的值
ThisBinding = <this value>,
// 创建词法环境组件
LexicalEnvironment = {},
// 创建变量环境组件
VariableEnvironment = {},
}
this在其他的笔记已经介绍过,我们需要重点关注的是词法环境组件和变量环境组件
词法环境组件由环境记录与对外部环境引入记录两个部分组成,是一个关于标识符(变量名/函数名)与实际对象的值(普通数据/地址值)的映射关系结构
var a = 123
var b = {}
/*
即: 标识符a 映射 Number类型的值123
标识符b 映射 对象所在堆内存的地址值
*/
环境记录用于存储当前环境中的变量和函数声明的实际位置,这里我认为可以理解为记录变量/函数提升前的位置,用于在标记实际的赋值位置
console.log(a)
var a = 123
// 这里代码实际执行过程是
var a
console.log(a)
a = 123
/*
环境记录就是用于标记 a真正是在console.log()后面被赋值的
** 注意: 这是个人猜测,真实度不确定
*/
外部环境引入记录用于保存当前自身环境可以访问到哪些外部环境,这就有点像作用域链下能够访问到哪些变量/变量值的意思
既然分为全局执行上下文与函数执行上下文,那么词法环境分为全局词法环境与函数词法环境两种
全局词法环境用伪代码展示
// 全局环境
GlobalExectionContext = {
// 全局词法环境
LexicalEnvironment: {
// 环境记录
EnvironmentRecord: {
Type: "Object", //类型为对象环境记录
// 标识符绑定在这里
},
// 对外部的引用记录是null
outer: [null]
}
}
函数词法环境用伪代码展示:
// 函数环境
FunctionExectionContext = {
// 函数词法环境
LexicalEnvironment: {
// 环境纪录
EnvironmentRecord: {
Type: "Declarative", //类型为声明性环境记录
// 标识符绑定在这里
arguments: {0: 'fitz', length: 1}
},
// 对外部的引用记录是可能是全局对象
// 也可能是另一个函数的环境,例如嵌套函数的对外部环境引入记录
outer: < Global or outerfunction environment reference >
}
}
下面介绍的是变量环境组件,变量环境组件是一种特殊的词法环境,它只用于存储var申明的变量
所以最后总结
var a = 123
let b = 'Fitz'
const c = 'Lx'
var d
function e (parm1, parm2) {}
d = e('p1', 'p2')
用伪代码完整的表示的上面这个实例的执行上下文对象创建过程:
//全局执行上下文
GlobalExectionContext = {
// this绑定为全局对象
ThisBinding: <Global Object>, // <Global Object> => window
// 词法环境组件
LexicalEnvironment: {
//环境记录
EnvironmentRecord: {
Type: "Object", // 对象环境记录
// 标识符绑定在这里 let const创建的变量a b在这
b: < uninitialized >,
c: < uninitialized >,
e: < function >
},
outer: <null> // 全局环境外部环境引入为null
},
// 变量环境组件
VariableEnvironment: {
EnvironmentRecord: {
Type: "Object", // 对象环境记录
// 标识符绑定在这里 var创建的全局变量在这
a: undefined,
d: undefined
},
// 全局环境外部环境引入为null
outer: <null>
}
}
//===========================分割线======================
// 函数执行上下文
FunctionExectionContext = {
//this根据函数的调用方式,动态改变 这里this => window
ThisBinding: <Global Object>,
// 词法环境
LexicalEnvironment: {
EnvironmentRecord: {
Type: "Declarative", // 声明性环境记录
// 标识符绑定在这里 arguments对象在这
arguments: {parm1: 'p1', parm1: 'p2', length: 2},
},
// 外部环境引入记录为</Global>
outer: <GlobalEnvironment>
},
VariableEnvironment: {
EnvironmentRecord: {
Type: "Declarative", // 声明性环境记录
// 标识符绑定在这里 var创建的局部变量在这
},
// 外部环境引入记录为</Global>
outer: <GlobalEnvironment>
}
}
执行上下文栈
在上面介绍执行上下文时,无论是全局执行上下文,还是函数(局部)执行上下文,我都提到了 执行上下文对象 这个概念,现在就来围绕这个执行上下文对象,来介绍什么是执行上下文栈。
首先,全局和局部的执行上下文对象的生命周期并不相同
- 全局执行上下文对象是在全局代码执行前产生。并且在浏览器关闭前,它都会一直存在
- 函数执行上下文对象是只要在函数调用,函数内部的语句执行前,才会产生。并且在函数调用结束后,这个函数执行上下文对象就会被销毁。这个概念就像函数作用域与JS垃圾回收器的关系
其次, 执行上下文对象并不是一个实实在在的JS对象, 它是一个虚拟的概念层次的对象,之所以称它为对象只是为了我们能够更方便的去理解
这里放一张英文网站的关于执行上下文栈的图

通过这道题目,解释执行上下文对象与执行上下文栈
var a = 10
var bar = function (x) {
var b = 5
foo(x + b)
}
var foo = function (y) {
var c = 5
console.log(a + c + y)
}
bar(10)
对于上面的题目,我的问题是: 以上产生了多少个执行上下文对象,它们与执行上下文栈的关系是如何的
带着问题,我们来边探讨边解答
首先上面我说过, 全局执行上下文对象window是在浏览器刚创建时就有了,而函数执行上下文对象只有在函数调用时才有。所以这个题目产生了3个执行上下文对象
// 1. 此时处在全局执行上下文对象中
var a = 10
var bar = function (x) {
var b = 5
foo(x + b) // 3. 函数调用,产生一个函数执行上下文
}
var foo = function (y) {
var c = 5
console.log(a + c + y)
}
bar(10) // 2. 函数调用,产生一个函数执行上下文
那假如调用两次bar()函数呢,答案是:产生5个执行上下文对象
// 1. 此时处在全局执行上下文对象中
var a = 10
var bar = function (x) {
var b = 5
foo(x + b) // 3. 函数调用,产生一个函数执行上下文
// 5. 函数调用,产生一个函数执行上下文
}
var foo = function (y) {
var c = 5
console.log(a + c + y)
}
bar(10) // 2. 函数调用,产生一个函数执行上下文
bar(10) // 4. 函数调用,产生一个函数执行上下文
/*
注意: 函数执行上下文对象在函数调用结束后是会销毁的
*/
对此,我们就能总结出执行上下文对象个数的公式了: 执行上下文对象 = 函数执行次数 + 1
说了这么多,这个执行上下文对象与执行上下文栈是什么关系呢?
是这样的, 在全局代码执行前, JS引擎会创建一个栈来储存管理所有的执行上下文对象
注意: 所有的意思就是无论全局的还是局部的都会放在这个栈中
我的很多笔记多次提到栈这一数据结构,都没好好解释。虽然不是什么难题,但力求将知识白痴化嘛,也不管啰不啰嗦了。
栈作为一种数据结构,拥有后进先出(LIFO)的特性,以我浅薄的学识,对栈的认识就这么多。光这么说难以理解,直接上图
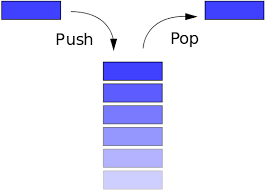
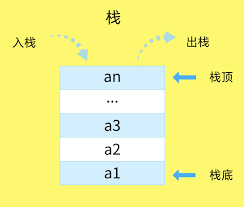
结合生活中的事物,还是比较好理解的

至此,我们就知道了执行上下文栈就是更好地管理执行上下文对象,还是以上面的题目,我们来简单可视化一下执行上下文栈
// 1. 此时处在全局执行上下文对象中
var a = 10
var bar = function (x) {
var b = 5
foo(x + b) // 3. 函数调用,产生一个函数执行上下文
}
var foo = function (y) {
var c = 5
console.log(a + c + y)
}
bar(10) // 2. 函数调用,产生一个函数执行上下文

执行上下文栈面试题及其解析
// 执行结果是什么
// 一共产生了多少个执行上下文(对象)
console.log('global begin: ' + i)
var i = 1
foo(1)
function foo(i) {
if (i === 4) {
return
}
console.log('foo() begin: ' + i)
foo(i + 1)
console.log('foo() end: ' + i)
}
console.log('global end: ' + i)
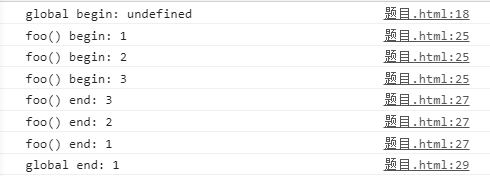
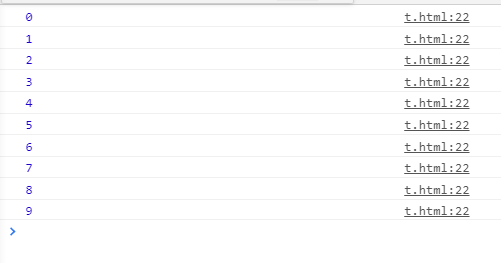
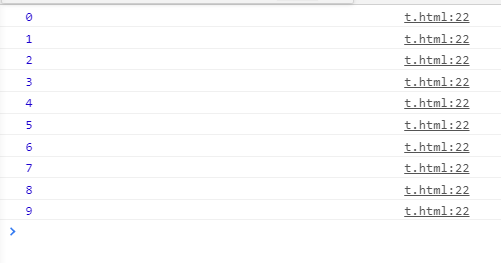
可视化解析:
// 执行结果是什么
// 一共产生了多少个执行上下文(对象)
console.log('global begin: ' + i) // 变量提升输出undefined
var i = 1
// 这部分重点看图片中我做的可视化解析
foo(1)
function foo(i) {
if (i === 4) {
return
}
console.log('foo() begin: ' + i)
foo(i + 1) // 递归调用
console.log('foo() end: ' + i)
}
console.log('global end: ' + i) //1, 全局作用域的i一直没变,不要被函数作用域内的i影响

 浙公网安备 33010602011771号
浙公网安备 33010602011771号