
最大回撤的快速算法
最大回撤的快速算法
飞麦 2022-05-12
1 摘要
本文描述了最大回撤的问题概述,算法分析,各算法在C++、Java、Python、Ruby语言上的实现,各语言一致的伪随机数生成,各语言各算法的性能。
2 问题概述
2.1 背景
先看个2022-03-16的新闻:百只基金净值回撤超50%
简单地说,回撤相当于钱包的亏损比例=(现值-原值)/原值=现值/原值-1=缩水比例-1。最大回撤相当于一位最不幸的投资者,在一个最糟糕的日期买入,随后在另一个最糟糕的日期卖出,亏损比例(绝对值)比任何两个其它日期之间的买卖都高。
许多金融机构经常会对大量金融产品进行最大回撤的计算,本文给出了优化的算法,较被普遍使用的遍历算法提升效率500~4000倍,可减少大量无效CPU资源的消耗。
2.2 图示
用走势图形象地展示回撤,有助于更直观地理解这个概念。但不应使用普通走势图,而应使用对数走势图,我们通过实例说明原因。
600519 贵州茅台的复权收盘价,下跌A段从2007-12-28的1043.43元下跌到2008-06-23的615.43元,下跌B段从2008-07-28的739.07元下跌到2008-11-07的391.34元。从下跌走势图看,A段(蓝色点)下跌了428.00元,B段(绿色点)下跌了347.73元,A段下跌幅度明显大于B段。
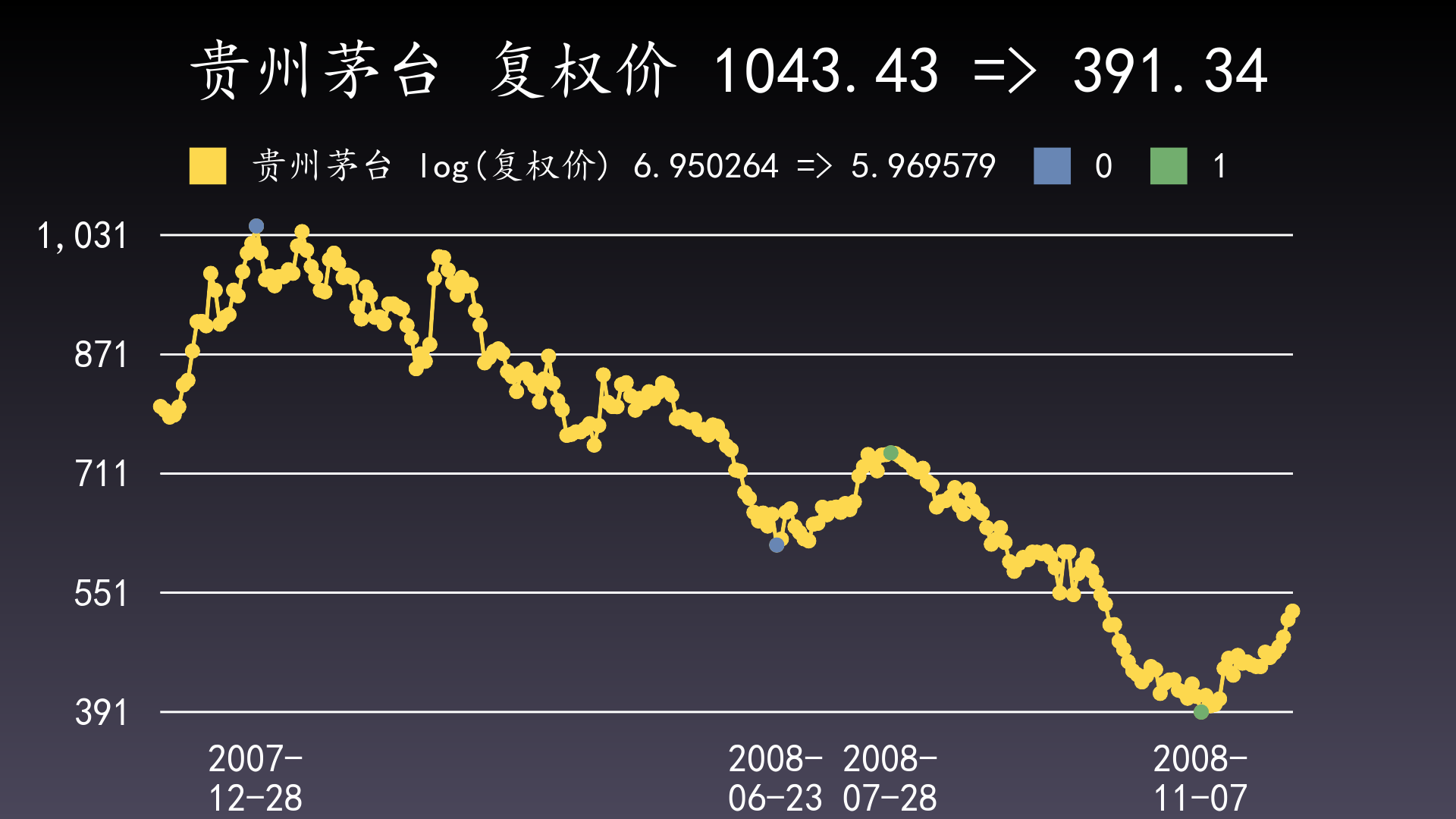
但我们计算一下缩水比例:A段=615.43/1043.43=0.5898;B段=391.34/739.07=0.5295,也就是B段缩水得更厉害。看对数图就能看出这种差别了。
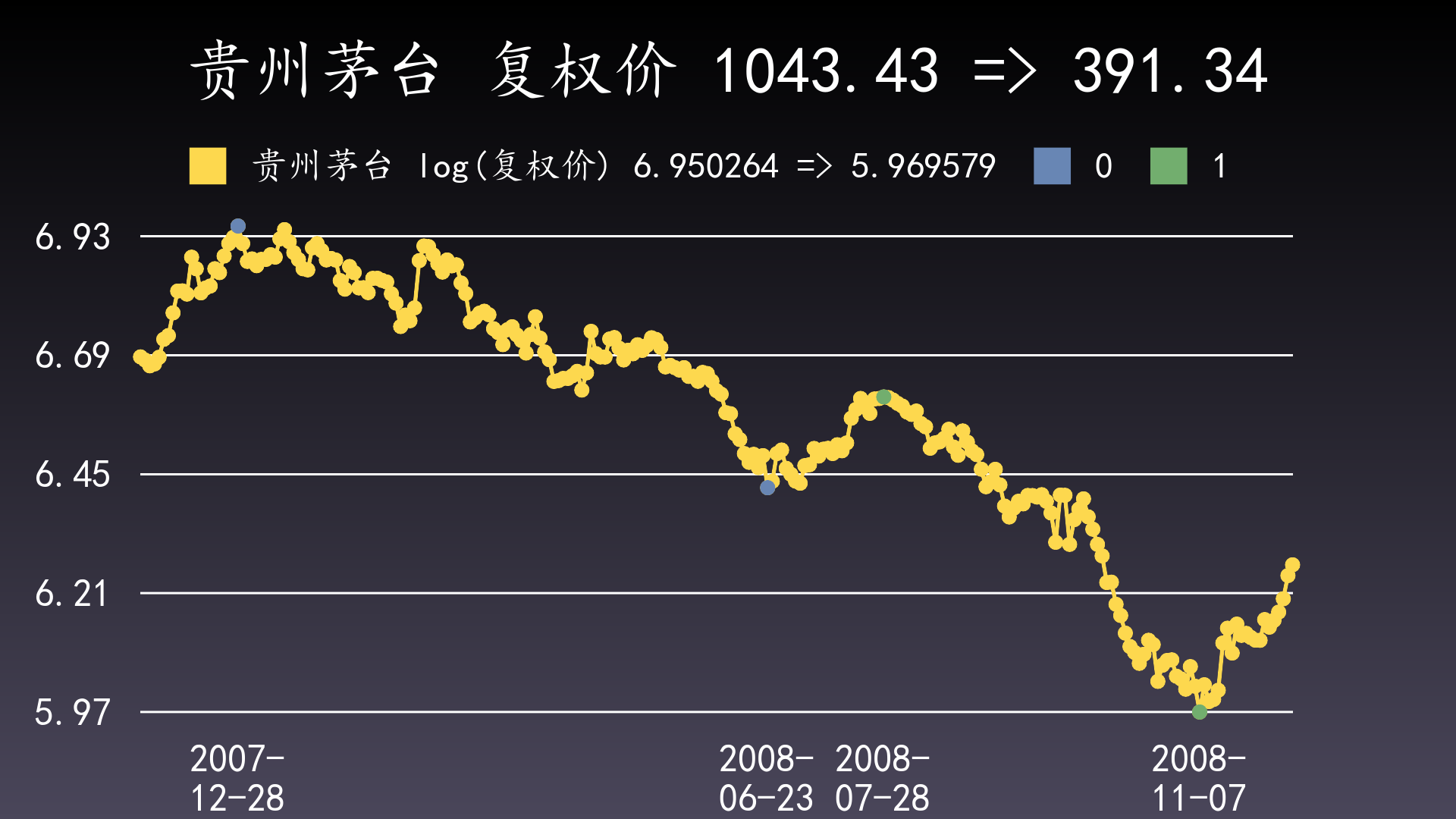
查看金融产品的走势图,都应使用对数图,或与对数图等价的等比例图。等比例图与对数图的水平线是一致的,但标示的数值是原数值而不是它的对数。等比例的含义是:任何3条相邻距离相等的水平线,上2条水平线的数值比例,与下2条水平线的数值比例相等,也就是它们的对数的差相等。
在对数图上,两个值的对数之间的垂直距离与缩水比例线性相关,而缩水比例与回撤正相关,回撤=(结束值-起始值)/起始值=结束值/起始值-1=缩水比例-1。原因:log(low / high) = log(low) - log(high),其中log为自然对数函数。对数是人类的重大发现,将除法等价地转换为减法。
2.3 概念
研究对象:给定的一系列有序日期及其对应的数值。例如:股票上市期间每个交易日的复权收盘价,基金运作期间每个交易日收盘后的累计净值,每个交易日收盘后的股票大盘指数/成份指数/行业指数等等。其中日期范围可以是研究对象整个生命周期内的所有日期,也可以是其中的一段,如10年、5年、某基金经理的任期等等。
日期区间:在给定范围的所有日期中,任意两个日期对应的区间;这两个日期被称为区间的起始日期与结束日期,其中起始日期<=结束日期。例如:贵州茅台于2001-08-27上市,则2001-08-27至今是日期区间,2001-08-272011-08-26这十年也是日期区间,甚至2001-08-272001-08-27这一天也是日期区间。
回撤:对任意日期区间,结束日期的值相对起始日期的值下降的比例=(结束值-起始值)/起始值;若结束值相对起始值未下降,则回撤为0.0。
样例:600519 贵州茅台2007-12-28的后复权价为1043.43元,2008-11-07的后复权价为391.34元,这个日期区间的回撤=(391.34-1043.43)/1043.43=-0.6249。
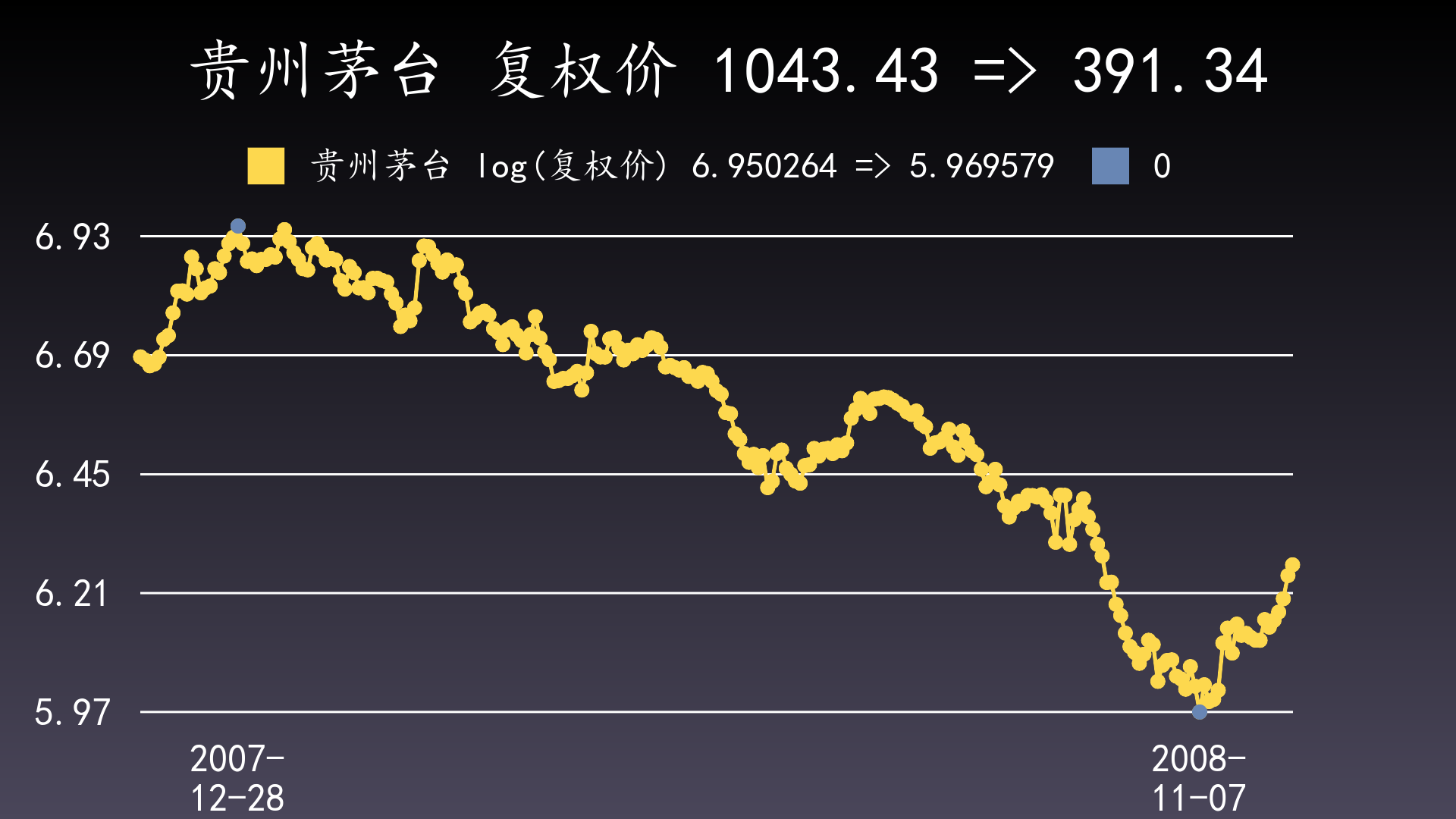
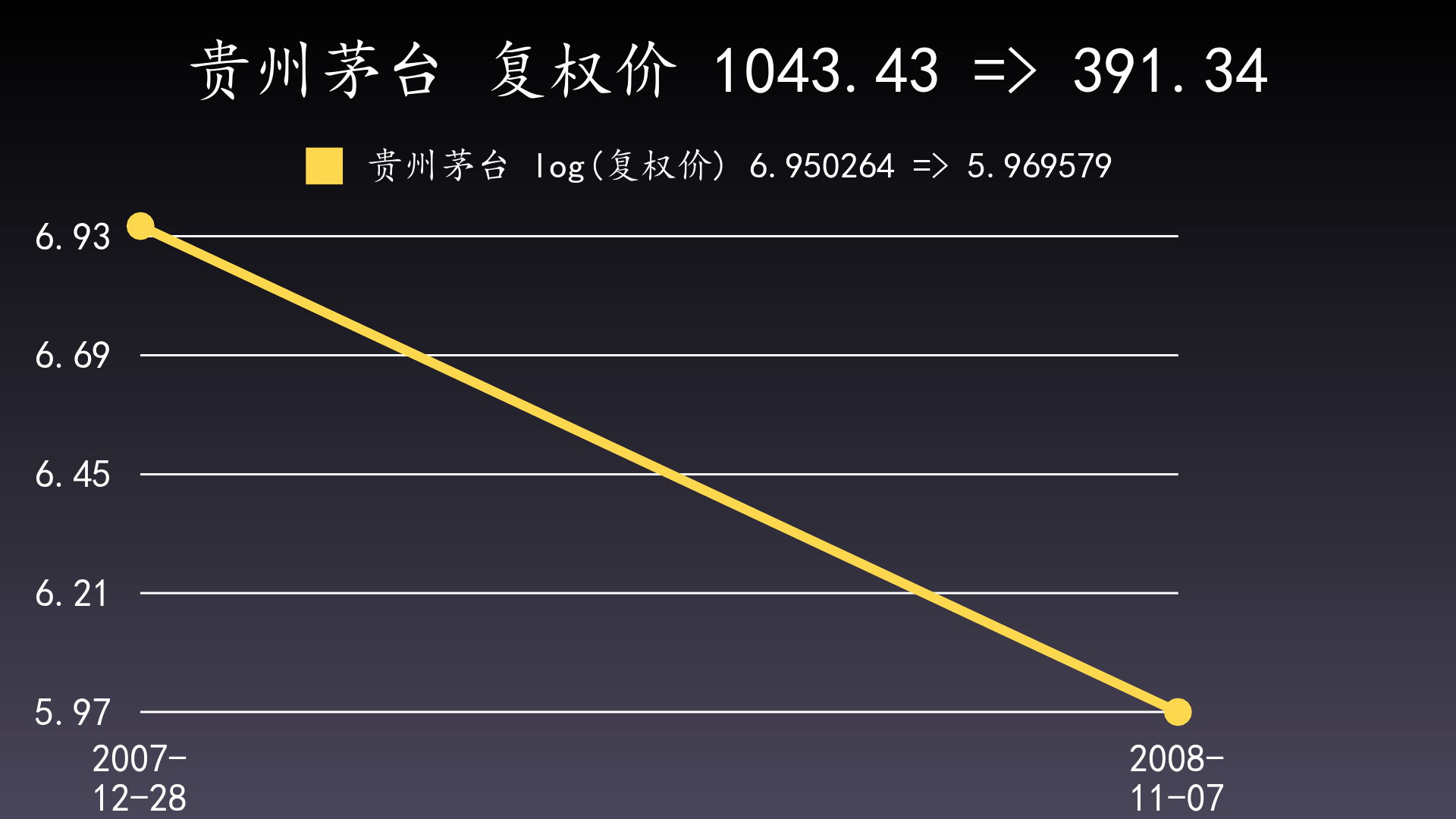
从回撤的定义可以看出,从一个起点到一个终点的回撤,只与这个起点和这个终点的值相关,与其它点的值无关,因此上图可以简化为下面的图:
最大回撤:所有日期区间中回撤绝对值最大的,当有多个最大回撤相等时,只选一个,选择规则为:
- 等值最大回撤对应的日期区间重叠时:选日期区间最狭窄的;
- 等值最大回撤对应的日期区间不重叠时:选日期区间最晚的。
下面详细解释这两个选择规则。
【1】等值最大回撤对应的日期区间重叠时:选日期区间最狭窄的;
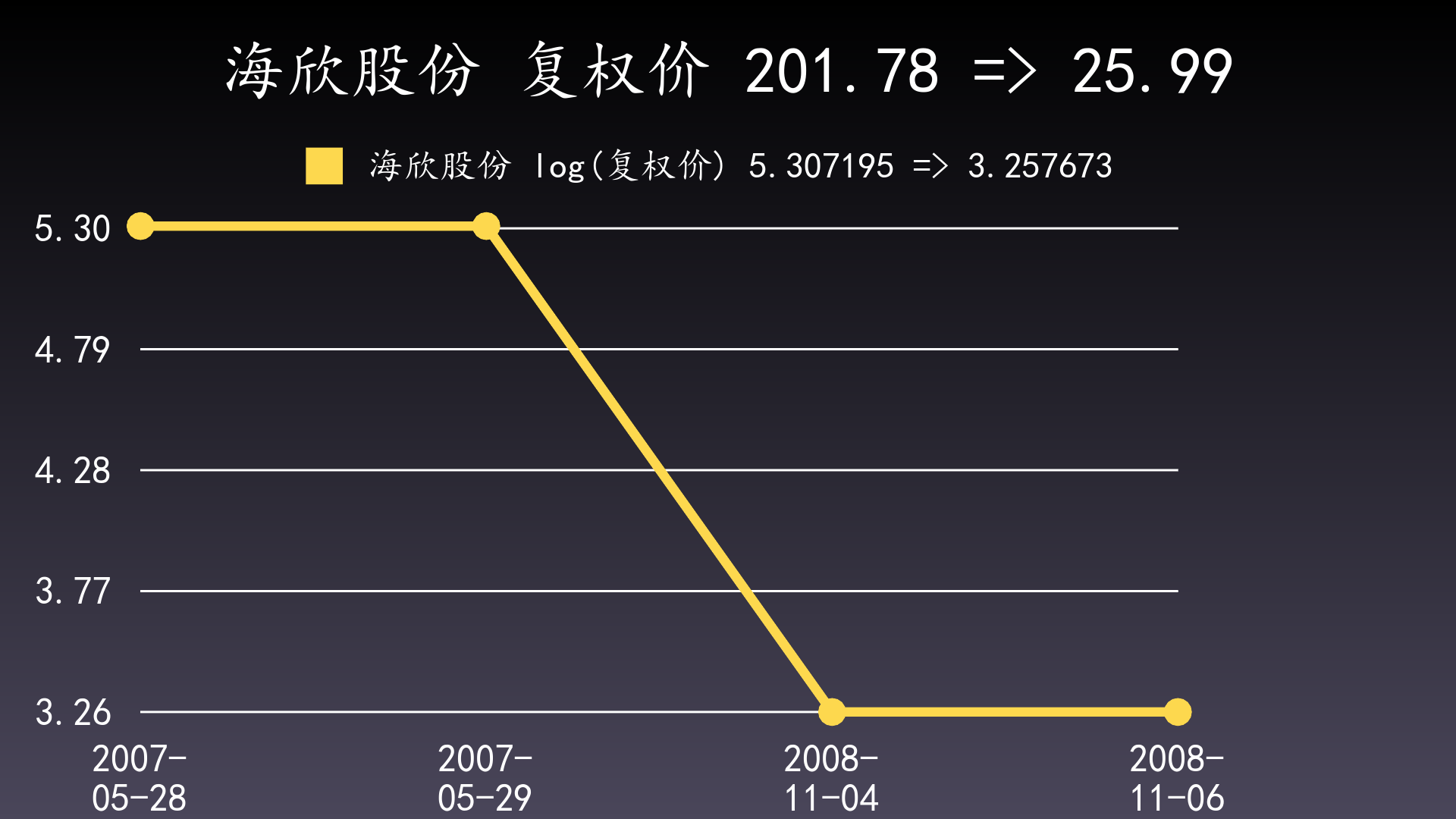
样例:600851 海欣股份2007-05-28与2007-05-29均出现最大回撤峰值201.78元(后复权价),2008-11-04与2008-11-06均出现最大回撤谷值25.99(后复权价),从两个起点的任一个到两个终点的任一个,共4个区间,最大回撤都相同。此时应选择的最狭窄的最大回撤区间,即2007-05-29到2008-11-04。
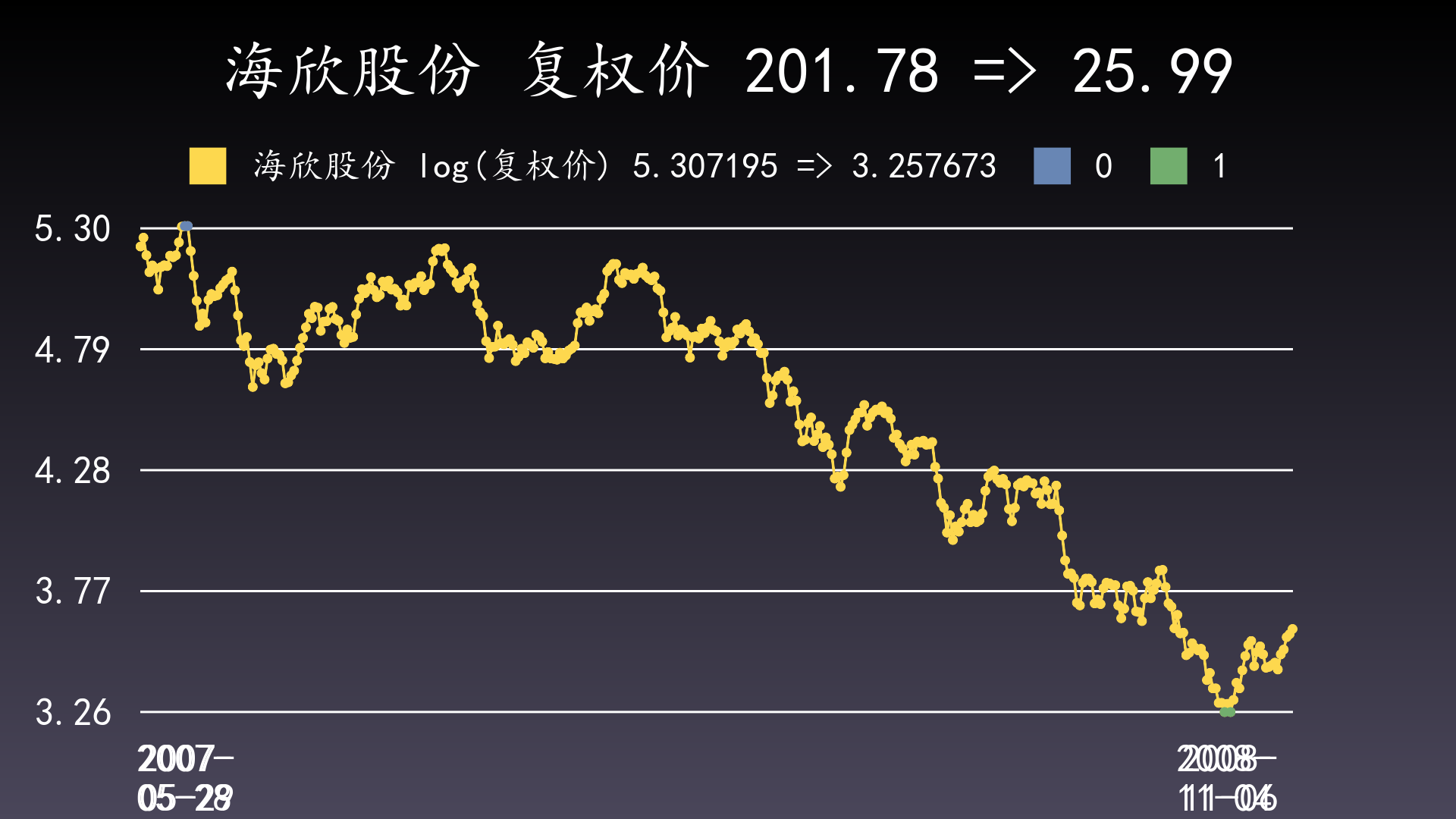
只绘制这4个区间的2个起点和2个终点:
【2】等值最大回撤对应的日期区间不重叠时:选日期区间最晚的。
样例:现实中出现此种情况的概率极低,举个非常接近的例子进行说明:002299 圣农发展,从2011-03-09的40.82元下跌到2014-03-04的16.39元,回撤为-0.5985;从2016-08-02的64.02元下跌到2018-02-09的25.70元,回撤为-0.5985,仅仅由于小数4位之后的数值略微小于前一段,因此没有被纳入最大回撤;假设两个回撤完全相等,则按照选最晚日期区间的规则,应优选后面这段为最大回撤区间。
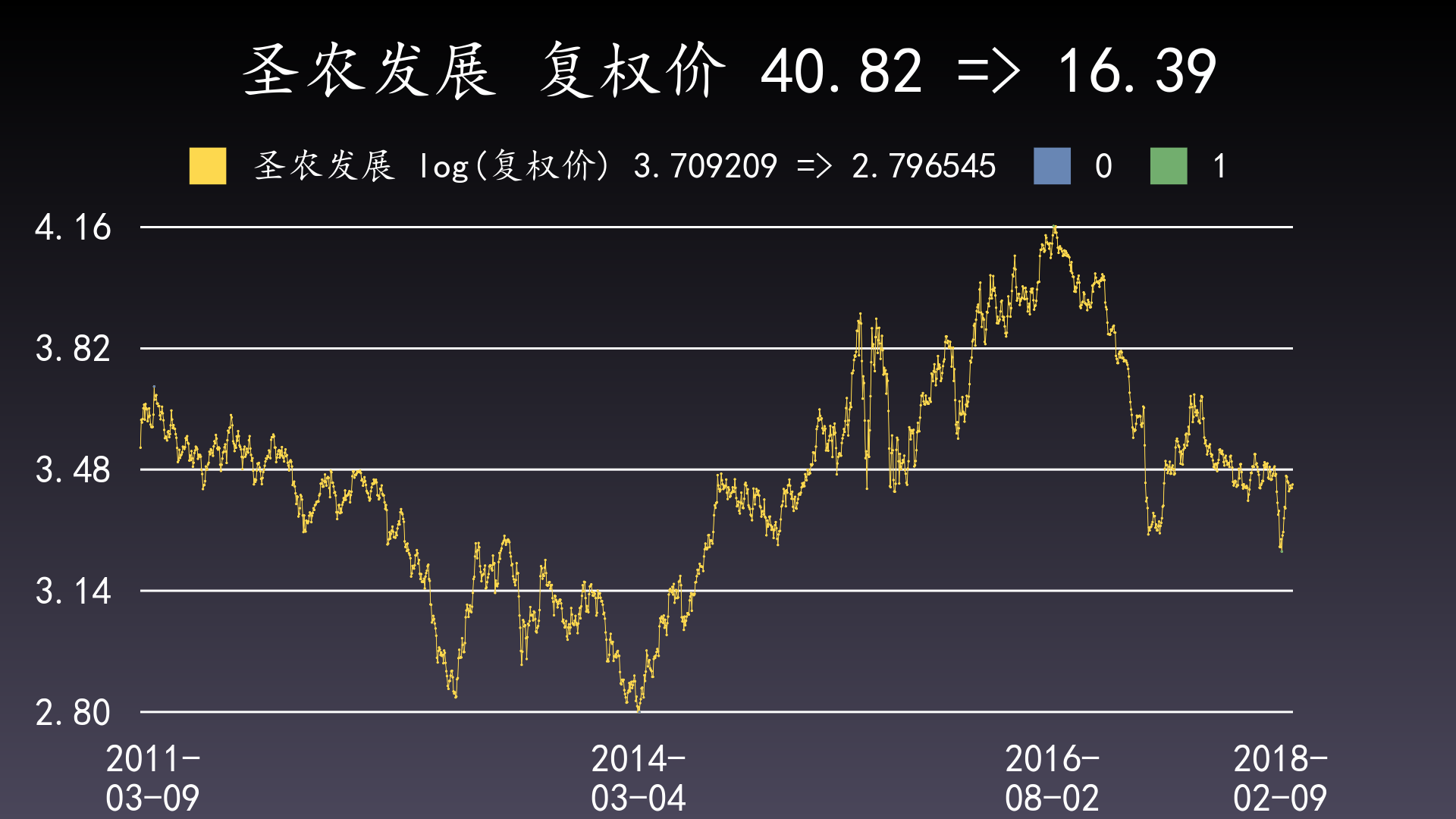
只绘制这2个区间的起点和终点:
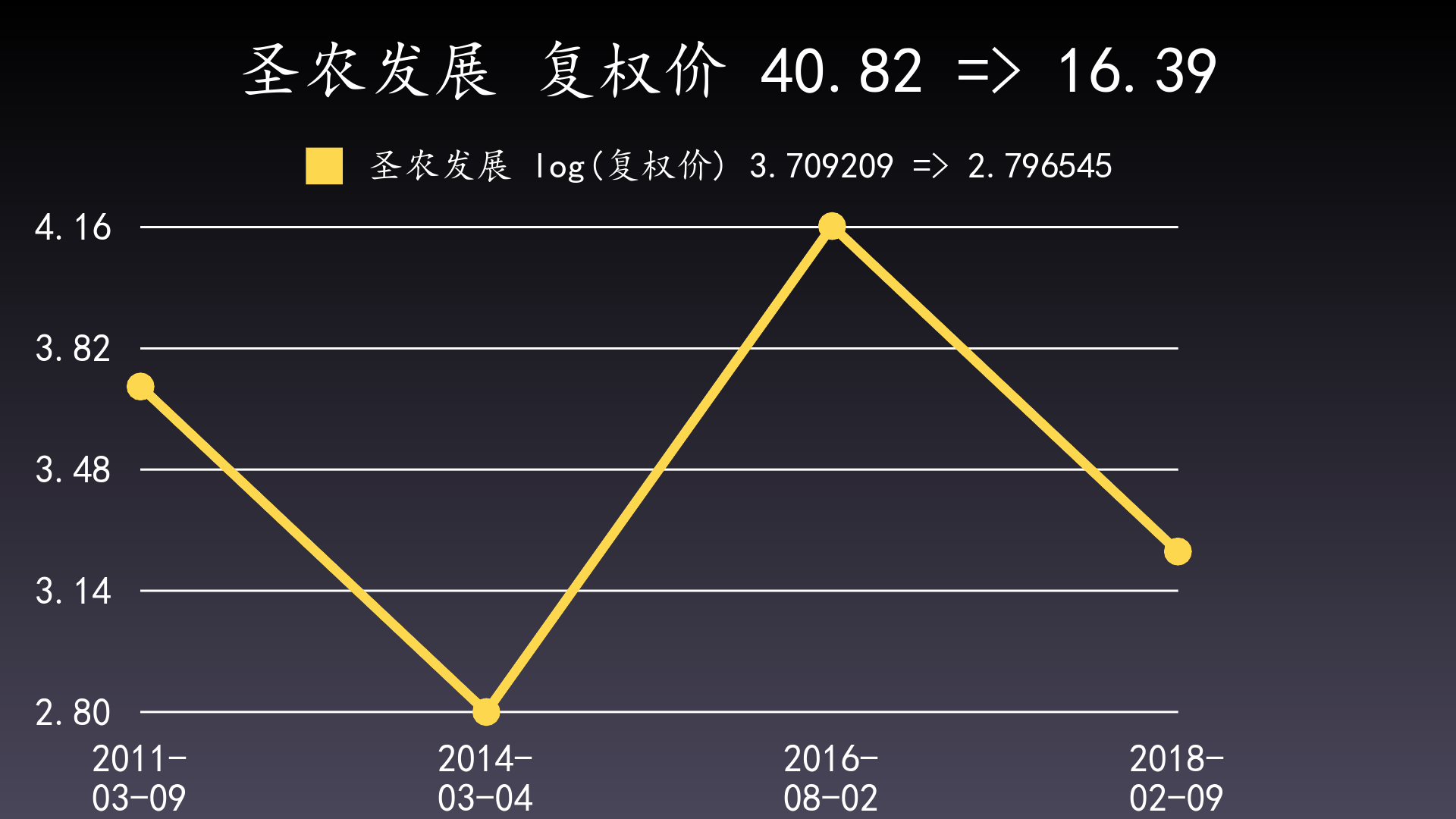
另外注意:出现上面最大回撤相等但区间不重叠的情况时,晚的区间的峰值与谷值一定高于或等于早的区间的峰值与谷值,即2016-08-02的64.02元>=2011-03-09的40.82元,2018-02-09的25.70元>=2014-03-04的16.39元。否则最大回撤区间将变成2011-03-09到2018-02-09,并且其值将超过原来的两个区间的最大回撤,这与原来的两个区间都是最大回撤相矛盾,因此不能成立。
最大回撤区间:最大回撤对应的起始日期与结束日期。
最大回撤的意义:最大回撤通常用于衡量和比较股票、基金、指数的波动下行风险;在经历长期波动后,最大回撤较小的股票,通常有更大的长期涨幅;也对挑选合适的入场时机有一定的参考价值。
2.4 样例
从上市起截至2022-05-12:
| 代码 | 名称 | 最大回撤 | 峰值 | 峰日期 | 谷值 | 谷日期 |
|---|---|---|---|---|---|---|
| 000661 | 长春高新 | -0.8461 | 50.78 | 2001-01-05 | 7.82 | 2005-07-18 |
| 600111 | 北方稀土 | -0.8229 | 30.34 | 2001-01-05 | 5.37 | 2005-07-15 |
| 600309 | 万华化学 | -0.8134 | 778.29 | 2007-09-03 | 145.22 | 2008-10-27 |
| 600809 | 山西汾酒 | -0.8117 | 85.12 | 2007-01-19 | 16.03 | 2008-10-16 |
| 600887 | 伊利股份 | -0.7858 | 319.60 | 2007-05-29 | 68.46 | 2008-10-27 |
| 000858 | 五粮液 | -0.7645 | 737.06 | 2007-10-15 | 173.58 | 2008-10-27 |
| 000568 | 泸州老窖 | -0.7616 | 148.85 | 1997-05-09 | 35.49 | 2005-06-15 |
| 600276 | 恒瑞医药 | -0.7099 | 6139.05 | 2020-12-25 | 1781.09 | 2022-04-26 |
| 000651 | 格力电器 | -0.6503 | 1035.40 | 2008-02-19 | 362.03 | 2008-10-29 |
| 600519 | 贵州茅台 | -0.6249 | 1043.43 | 2007-12-28 | 391.34 | 2008-11-07 |
2.5 输入
一个结构或类型(struct or class)的列表或数组(array or list),每个结构至少包含两个域或属性(field or attribute):
【1】日期:按升序排列并且没有重复;
【2】数值:通常代表指数、后复权价、累计净值等,均为正的实数(对应计算机中的正浮点数)。
2.6 处理
根据输入计算出列表或数组中的最大回撤及其区间的起止点。
2.7 输出
最大回撤(<=0.0),最大回撤区间起始日期及其数值,最大回撤区间结束日期及其数值。本质上是求出回撤区间的起止位置,这样就可以进一步获取相关数据。
3 算法分析
注:根据《民法典》,“以后”包含其自身,“之后”则不包含其自身。下面的“回撤最大”,均指回撤的绝对值最大。按定义回撤只能是0.0或负数。
只要列表或数组非空,从任意点出发,到它以后的点,都一定有个最大回撤。
如果某个点是最后一个点,则它只有一个以后的点,就是它自身,那么从此点开始的最大回撤就是0.0。
如果某个点的值,比它之后的所有点的值都低或相等,那么从此点到其以后任意点的回撤全部都是0.0。
每个点到它以后的任一点,都可以计算出回撤,这些回撤中一定有个最大的(多个最大回撤相同时按最大回撤区间的选取要求,总能选出固定的一个区间)。
所有起始点的最大回撤之中,再选出最大的,就是整个列表或数组的最大回撤。
这就是最原始的遍历算法,目前仍然被相当一部分金融机构在使用。
3.1 遍历算法
设定整个列表或数组的最大回撤初值为1.0(不可能的值)。
对于列表或数组中的每个点,计算它到它以后的所有点的回撤,记录其中最大的回撤及其位置作为本轮最大回撤,当出现等值的最大回撤时,这些回撤起点相同,因此必然重叠,选终点最早的就能实现区间最狭窄。
当这个点到它以后的所有点的回撤计算完,就能确定以它为起点的最大回撤,即本轮最大回撤。本轮最大回撤与整体最大回撤比较,若本轮最大回撤<=整体最大回撤,则将整体最大回撤替换为本轮最大回撤。之所以相等时也替换,是因为:【1】若区间重叠,晚的起点区间更狭窄;【2】若区间不重叠,也要选晚的。
当所有点都作为起点按上述方法运算一轮之后,整体最大回撤就计算出来了。
3.1.1 略微优化
在上述遍历算法中,每一轮都对一个起点以后的每个点计算回撤,要消耗大量的计算资源,而在这轮中,只有此起点以后的最低点才具有本轮的最大回撤。当有多个相等的最低点时,只有最前面的最低点因回撤区间最狭窄而被优选出来。
因此,可以找到起点以后的最低点,当出现多个最低点时,选最早的一个,然后计算最大回撤即可。这样可以减少第一轮的计算量。
但这样仍然要将所有的点作为起点来计算,总的运算量仍然相当大。
3.2 简洁算法
3.2.1 按最低点分解
从整个列表或数组的最低点(如有多个相等的最低点,取最早的一个)来分析,将整个列表或数组划分为最低点以前与最低点之后两段,再次提醒注意“以前”与“之后”的含义。
对于前半段来说,最低点是最后一个点,它之前的所有点都比它高,因此找到前半段的最高点(如有多个取最晚的一个),则此最高点到此最低点的回撤,是前半段的最大回撤,前半段内的其它区间,由于起点均比最高点低(其它相等最高点因日期较早,在重叠区间竞争中失败),终点均比最低点高,因此回撤必然比上述最大回撤小(注意是指绝对值)。这样前半段的最大回撤就计算出来了。
而前半段的最高点,到后半段的任意点,这些终点要么比上述全局最低点高,要么比上述全局最低点日期晚,均无法产生比前半段的最大回撤更大的回撤。同理,以前半段的其它点为起点,到后半段的任意点,由于起点低(相同时日期早),终点高(相同时日期晚),其回撤也只能比上述最大回撤小(绝对值)。
这样就得出结论,以前半段为起点的任意区间,其最大回撤都不会超过上述的最高点与最低点的回撤,即前半段的最大回撤。
那么后半段是否会产生更大的回撤呢?完全有可能,虽然后半段的最低点不低于上述最低点(可能相等,当出现多个相同的最低点时),但后半段可能会出现比前半段更高的最高点(类似上述002299 圣农发展2016-08-02的情况),这样后半段的最大回撤可能超过前半段而成为全局的最大回撤。
我们可以先记录前半段的最大回撤,而将上面的算法同样应用于后半段,将后半段再分拆为两段,将新的前半段的最大回撤与原前半段的最大回撤进行比较,记录其中的优胜者(最大回撤绝对值大,相同时优选时间晚的)。再对新的后半段进行同样的拆分操作。
通过这样不断迭代,最终通过比较与优选,获得全局的最大回撤。
当列表与数组中有4000个元素时,用随机数实测,简洁算法的速度约为遍历算法的200~800倍。元素越多,差异越大。
3.2.2 按最高点分解
从整个列表或数组的最高点(如有多个相等的最高点,取最晚的一个)来分析,将整个列表或数组划分为最高点以后与最高点之前两段。
后续的分析与前面的按最低点分解算法一样,只是将前与后交换,高与低交换,早与晚交换,就能形成对称的简洁算法。这里就不再重复描述。
它的效率与复杂性,与上述的算法相同。
3.3 快速算法
结合简洁算法的按最低点分解与按最高点分解,综合从整个列表或数组的最低点(如有多个相等的最低点,取最早的一个)、整个列表或数组的最高点(如有多个相等的最高点,取最晚的一个)来分析,有两种情况:
- 最高点在最低点以前;
- 最高点在最低点之后。
下面分别分析这两种情况:
【1】最高点在最低点以前;
没有任何其它区间的起点能高过(或相同但晚于)最高点,也没有任何其它区间的终点能低过(或相同但早于)最低点,因此其它区间在最大回撤的竞争中失败,从这个最高点到这个最低点就是最大回撤区间。
【2】最高点在最低点之后。
将整个列表或数组划分为最低点以前(A)、最低点之后到最高点之前(B)、最高点以后(C)三段。
对最低点以前这一段(A):整个列表或数组中与它等值的点,按上述取最早一个的规则不能进入这一段,因此最低点之前的点必然高于此点。因此这一段的最大回撤的终点必然是这个最低点。锁定终点之后,起点就必然是这一段的最高点。这样这一段的最大回撤及其区间可以立即计算出来。
对最高点以后这一段(C):整个列表或数组中与它等值的点,按上述取最晚一个的规则不能进入这一段,因此最高点之后的点必然低于此点。因此这一段的最大回撤的起点必然是这个最高点。锁定起点之后,终点就必然是这一段的最低点。这样这一段的最大回撤及其区间可以立即计算出来。
上述前后两段的最大回撤,按最大回撤选取规则比较出大的一个记录下来。
对于最低点之后到最高点之前这一段(B),即中间这段,可按上述算法再分割出新的三段来,并继续挑选出新前段与新后段的最大回撤及其区间,并与原挑选出的最大回撤进行比较,按规则留下其中最大的。
反复迭代上述过程,直到中间那段遇到【1】的情况时停止,将中间那段的最大回撤与前面留下的最大回撤进行比较,选出整体最大的即可。
算法技巧:将中间那段与两侧的最大回撤初始值设置为1.0(即不可能的值),后续比较时会将它们替换掉。当它们初始就不存在时,也不会影响其它段的比较与挑选。在迭代中各段会逐渐缩小,这样就必然会得到最终结果。
当列表与数组中有4000个元素时,用随机数实测,快速算法的速度约为简洁算法的1~3倍。元素越多,差异越大。
当元素达到百万级别时,快速算法的速度达到简洁算法的2~3倍。
3.4 飞速算法
快速算法还可以再优化,在上述快速算法基础上进一步削减参与运算的点,形成飞速算法。
3.4.1 掐头去尾
3.4.1.1 掐头
每次迭代中遇到新的一段时,对于从此段开始就单调上升或持平的一系列点,单调上升持平段的最后一个点,简称头部高点。如果以头部高点之前的点作为起点,无论以哪个点为终点,其最大回撤都无法超过头部高点。
- 如果以头部高点以前的点为终点,因此段单调上升,因此回撤均为0.0,这样肯定竞争不过头部高点,以头部高点为起点,回撤最小也是0.0,并且时间还更晚(即区间更狭窄)。
- 如果以头部高点之后的点为终点,因起点低于或相等但早于头部高点,因此也竞争不过。
这样,头部高点之前的点可以不必处理,直接跳过。
3.4.1.2 去尾
每次迭代中遇到新的一段时,对于从此段结束处倒序向前单调下降(正序单调上升)或持平的一系列点,单调下降持平段的最前一个点,简称尾部低点。如果以尾部低点之后的点作为终点,无论以哪个点为起点,其最大回撤都无法超过尾部低点。
- 如果以尾部低点以后的点为起点,因此段单调上升(倒序下降)或持平,因此回撤均为0.0,如果尾部低点以前有任何区间回撤不为0.0的,则最大回撤肯定由该段取得。如果没有,说明整个列表或数组单调上升或持平,则最大回撤为0.0并由上面的掐头算法直接算出。
- 如果以尾部低点之前的点为起点,则这些终点肯定高于或等于但晚于尾部低点,因此也竞争不过。
这样,尾部低点之后的点可以不必处理,直接跳过。
3.4.2 摸高爬低
经过掐头去尾之后,参与运算的点得到了减少,但还有进一步减少的空间。
摸高爬低:忽略掉肯定小于已知最大回撤的起点和终点。
如果最高点在最低点以前,则直接算出最大回撤。
如果最高点在最低点之后,将整个列表或数组仍划分为最低点以前、最低点之后到最高点之前、最高点以后三段。
在两侧的最大回撤计算出来并留下其中最大的一个时:
3.4.2.1 摸高(前部略过)
以中间段的前部为起点,因其以后的终点均高于最低点,因此必须在它大于等于最低点+最大回撤时,才有可能超越两侧的最大回撤,否则都可以略过。
3.4.2.2 爬低(后部略过)
以中间段的后部为终点,因其以前的起点均低于最高点,因此必须在它小于等于最高点-最大回撤时,才有可能超越两侧的最大回撤,否则都可以略过。
3.4.3 飞速算法总结
经过上述优化,飞速算法速度进一步提升。
当列表与数组中有4000个元素时,用随机数实测,飞速算法的速度约为快速算法的2~3倍。元素越多,差异越大。
当元素达到百万级别时,飞速算法的速度达到快速算法的100倍左右。
在 Intel i5 CPU、Windows 10 操作系统上,完成百万元素的最大回撤计算,C++ 约需 2.3 毫秒,Java 约需 10 毫秒,Python 约需 820 毫秒,Ruby 约需 630 毫秒。
4 各语言实现
选取C++(C17)、Java(V18.0.1)、Python(V3.8.8)、Ruby(V3.0.3p157)等常用编程语言来实现最大回撤的遍历、简洁、快速、飞速等算法。各算法中都有一个参数:log,当它为真时,表示输入的列表或数组中的数值均为对数形式,此时返回的最大回撤是缩水率的对数形式,需要用公式 Math.exp(缩水率的对数) - 1.0 转换为最大回撤。
4.1 C++ Mdd
通过 mdd.hpp 文件中的 Mdd 类来实现,利用C++的结构中的数值域的指针,实现对列表或数组的结构元素中的数值域的获取。
此类没有内部状态,所有函数均为类函数(static),因此可以直接转换为不在类中的普通函数。
C++ 虽然在类函数中也支持函数参数,但使用过于复杂不便,远不如非类函数中的函数参数方便,因此本实现采用了指针。
C++ 数学函数在从库中引入后,可以直接调用,容易产生命名空间冲突。
C++ 的指针很强大,但使用时需要很小心,要严防指针越界。
C++ 的参数引用传递效率较高。
mddtest.cpp 为测试程序,输出结果通过批处理重定向到 mddc.txt 文件中。
4.2 Java Mdd
通过 Mdd.java 文件中的 Mdd 接口来实现,其中 value4mdd 函数实现对列表或数组的结构元素中的数值域的获取。
Java 对函数参数支持不佳(仅支持 Lambda),因此通过接口中的指定函数来变通实现,注意接口函数名称需要很独特,以防与实现接口的类中的原有函数名称冲突。
通过接口实现计算最大回撤,使调用这个接口的类实现时略为繁琐。
Java 不支持返回多个值,也不支持参数的引用传递,如果想实现多个值的返回,只能建立新的类将它们包装进去,这样会导致对外接口过于复杂。
本实现采用数组参数来变通实现参数的引用传递,程序内部较复杂,但外部使用稍简单一些。
Java 不支持默认参数值,通过定义不同参数数量的另一个函数变通实现。
Mddtest.java 为测试程序,输出结果通过批处理重定向到 mddj.txt 文件中。
4.3 Python Mdd
利用 mdd.py 文件中的 Mdd 类来实现,利用函数参数,实现对列表或数组的结构元素中的数值域的获取。
Python 的类编写相对繁琐,需要使用 self 引用本对象的属性和方法,并使用类名称引用本类的常量。
Python 不支持对基础类直接添加方法,只能通过继承来实现,但这样对基类的字面量(Literal)就无法使用新定义的函数。
因此本实现采用独立的类来实现相应的功能。
Python 虽然不支持引用传递,但支持返回多个值。
Python 各种函数库可以为小写(如 math),调用时容易与本地对象混淆。
Python 的 round 函数在遇到小数部分为 0.5 时,是向偶整数靠近。
mddtest.py 为测试程序,输出结果通过批处理重定向到 mddp.txt 文件中。
4.4 Ruby Mdd
利用 mdd.rb 文件中的 Array 类扩充实现,并利用函数参数,实现对列表或数组的结构元素中的数值域的获取。
Ruby 的类编写简捷,并支持对基础类直接添加方法,这样在使用时很方便。
Ruby 不直接支持函数参数,但支持通过符号(Symbol)指定函数名称来传递函数名称以进行调用。
Ruby 虽然不支持引用传递,但支持返回多个值。
mddtest.rb 为测试程序,输出结果通过批处理重定向到 mddr.txt 文件中。
5 各语言一致的伪随机数生成
C++、Java、Python、Ruby的标准库,提供的默认伪随机函数,具体实现均有一定差异,不能生成一致的伪随机数来进行测试并直接比较测试结果。
因此采用MT19337算法生成随机数,并采用Marsaglia法生成正态分布的随机数,在C++、Java、Python、Ruby上实现了一致的伪随机数生成器。
实现了整数均匀分布、浮点数均匀分布、浮点数正态分布三种业务场景。
在生成正态分布的伪随机浮点数时,需要用到超越函数,在IEEE 754标准中,并未对超越函数的实现进行明确的指导,因此各语言的各个实现均不相同,导致诸如 log 等函数的结果存在微小的差异(Python与C++相同,但Java和Ruby均与C++不同,Java和Ruby也互不相同),在计算最大回撤的业务场景中,这个输入随机数的微小差异尚未发现对最终结果(最大回撤及其起止位置)造成影响。
5.1 C++ Mt19337
实现在 mt19337.hpp 中;mt19337test.cpp 为测试程序,生成 mt19337c.txt 测试结果。
5.2 Java Mt19337
实现在 Mt19337.java 中;Mt19337test.java 为测试程序,生成 mt19337j.txt 测试结果。
5.3 Python Mt19337
实现在 mt19337.py 文件中;mt19337test.py 为测试程序,生成 mt19337p.txt 测试结果。
5.4 Ruby Mt19337
实现在 mt19337.rb 文件中;mt19337test.rb 为测试程序,生成 mt19337r.txt 测试结果。
6 各语言各算法的性能
以下数据来自测试结果 ben4.txt 文件。
num 为数组元素个数,当元素个数超过 4000 后不再测试过于缓慢的遍历算法。
Fly为飞速算法平均秒数,后面的括号内为相对快速算法速度的倍数(四舍五入)。
Qui为快速算法平均秒数,后面的括号内为相对简洁算法速度的倍数(四舍五入)。
Sim为简洁算法平均秒数,后面的括号内为相对遍历算法速度的倍数(四舍五入)。
Tra为遍历算法平均秒数。
C++ num= 1000 Fly=1.800000e-06( 3) Qui=5.740000e-06( 1) Sim=6.650000e-06(235) Tra=1.560210e-03
C++ num= 2000 Fly=4.130000e-06( 5) Qui=2.215000e-05( 1) Sim=2.497000e-05(198) Tra=4.937100e-03
C++ num= 4000 Fly=5.690000e-06( 3) Qui=1.951000e-05( 1) Sim=2.615000e-05(944) Tra=2.468492e-02
C++ num= 10000 Fly=2.149000e-05( 17) Qui=3.703900e-04( 1) Sim=3.954000e-04
C++ num= 100000 Fly=2.140800e-04( 20) Qui=4.326060e-03( 1) Sim=4.807080e-03
C++ num=1000000 Fly=2.281330e-03( 99) Qui=2.264540e-01( 2) Sim=5.030366e-01
Java num= 1000 Fly=1.116000e-05( 2) Qui=2.520000e-05( 1) Sim=2.621000e-05( 80) Tra=2.087360e-03
Java num= 2000 Fly=4.206000e-05( 1) Qui=5.377000e-05( 2) Sim=8.337000e-05( 72) Tra=6.036400e-03
Java num= 4000 Fly=5.370000e-05( 1) Qui=4.854000e-05( 2) Sim=8.284000e-05(323) Tra=2.676476e-02
Java num= 10000 Fly=2.624300e-04( 4) Qui=9.195200e-04( 2) Sim=1.586860e-03
Java num= 100000 Fly=1.538930e-03( 12) Qui=1.816058e-02( 2) Sim=2.918979e-02
Java num=1000000 Fly=1.047385e-02( 91) Qui=9.576574e-01( 2) Sim=2.310681e+00
Python num= 1000 Fly=5.436100e-04( 3) Qui=1.663830e-03( 2) Sim=3.506970e-03( 69) Tra=2.404650e-01
Python num= 2000 Fly=1.747380e-03( 4) Qui=7.247620e-03( 2) Sim=1.707024e-02( 52) Tra=8.956322e-01
Python num= 4000 Fly=2.299680e-03( 3) Qui=6.735370e-03( 2) Sim=1.622733e-02(242) Tra=3.926808e+00
Python num= 10000 Fly=1.070692e-02( 15) Qui=1.583096e-01( 2) Sim=3.201423e-01
Python num= 100000 Fly=7.679926e-02( 28) Qui=2.181094e+00( 2) Sim=3.472864e+00
Python num=1000000 Fly=8.155867e-01(105) Qui=8.587884e+01( 2) Sim=1.722409e+02
Ruby num= 1000 Fly=2.996300e-04( 3) Qui=9.669600e-04( 2) Sim=2.150980e-03(100) Tra=2.157509e-01
Ruby num= 2000 Fly=9.040600e-04( 4) Qui=3.932770e-03( 3) Sim=1.043737e-02( 73) Tra=7.626157e-01
Ruby num= 4000 Fly=1.354940e-03( 3) Qui=3.663050e-03( 3) Sim=9.773100e-03(356) Tra=3.478013e+00
Ruby num= 10000 Fly=6.683580e-03( 13) Qui=8.855230e-02( 2) Sim=1.992152e-01
Ruby num= 100000 Fly=5.560973e-02( 28) Qui=1.559015e+00( 2) Sim=2.728916e+00
Ruby num=1000000 Fly=6.250881e-01(107) Qui=6.662553e+01( 2) Sim=1.503087e+02
当最大回撤运算规模达到百万级别时,C++ 的速度约为 Java 的 4.6 倍,Java 的速度约为 Python 的 78 倍,Python 的速度约为 Ruby 的 0.77 倍。
7 下载地址
包含源程序与测试数据包(mdd_v3.7z)、本文档(mdd.pdf)。
https://pan.baidu.com/s/1Tq3NDj7zffiTugpQXffSrg?pwd=lyyi

 浙公网安备 33010602011771号
浙公网安备 33010602011771号