
余玄相似度,TF-IDF
能干什么?
文章去重,语句去重,提取关键词(文章摘要,页面指纹),图片识别,语音识别
想要做一个相似度,最重要的是什么?
必须得到一个度量:计算个体之间的相似程度(分数,0-1之间,0代表完全不同,一代表完全一样)
相似度值越小,距离越大,相似度值越大,距离越小
两方面考虑:
文本角度
语义角度
例如:这个菜真好吃
这个菜真难吃 ---------- > 文本角度来看,相似度非常高,语义角度就非常低
最常用:
余玄相似度 ------> 计算两个向量夹角的余玄来计算相似度
一个向量空间中两个向量夹角的余弦值作为衡量两个个体之间差异的大小
余弦值接近1,夹角趋于0,表明两个向量越相似
0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。从而两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两个向量指向完全相反的方向时,余弦相似度的值为-1。这结果是与向量的长度无关的,仅仅与向量的指向方向相关。余弦相似度通常用于正空间,因此给出的值为0到1之间。
cos(𝜃) =b/a
cos0°=1
cos90°=0
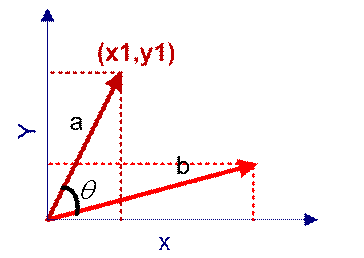
如果向量a和b不是二维而是n维
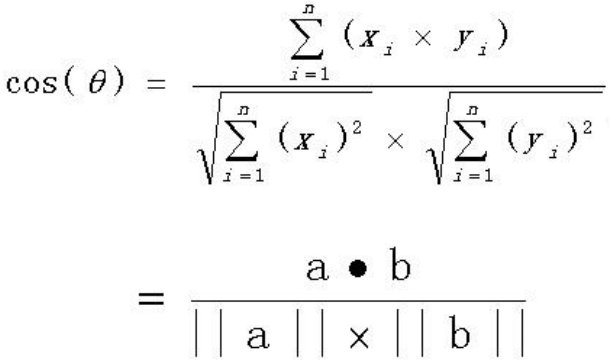
举个例子计算:
x:(2,5)
y:(4,9)
cos(𝜃)=2*4+5*9/sqrt(2*2+4*4)*sqrt(5*5+9*9)
一旦有了向量就能计算相似度了,但是向量是怎么来的呢?
继续举例子:
句子1:这支笔好看,但颜色不适合。
句子2:这支笔不好看,但颜色适合。
对以上的两个句子做分词:
句子1:这支/笔/好看,但/颜色/不合适
句子2:这支/笔/不好看,但/颜色/合适
word bag(词包):这支,笔,好看,不好看,但,颜色,不合适,合适(集合:上面两个句子去重,列出所有的词)
计算词频:当上面句子的分词在词包中出现几次就打几(上述例子没有多次的,所以都是1),不在就打0(一定严格按照词包的顺序)
句子1:这支1,笔1,好看1,不好看0,但1,颜色1,不合适1,合适0
句子2:这支1,笔1,好看0,不好看1,但1,颜色1,不合适0,合适1
词频向量化:
句子1:(1,1,1,0,1,1,1,0)
句子2:(1,1,0,1,1,1,0,1)
套公式计算: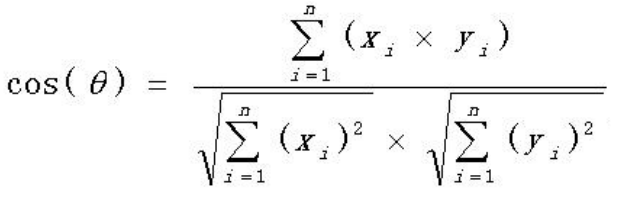
cos(𝜃)=1*1+1*1+1*0+0*1+1*1+1*1+1*0+0*1/sqrt(1*1+1*1+1*1+0*0+1*1+1*1+1*1+0*0)*sqrt(1*1+1*1+0*0+1*1+1*1+1*1+0*0+1*1)
处理流程:
1.找到两篇文章的关键词
2.每篇文章各取出若干个关键词,合并成一个集合,计算每篇文章对于这个集合中的词的词频(词频:一个词语在这个句子中出现的频率,一般来说一个词语在这个句子中出现的次数越多就越重要)
3.生成两篇文章各自的词频向量
4.计算两个向量的余玄相似度,值越大就是越相似
词频:TF(Term Frequency)
假设:一个词很重要,应该会在文章中出现多次
词频:一个词在文章中出现的次数
但是,出现次数最多的是“的”“是”“在”,叹词,状语次,乱码,标点等,这类最常出现的词,叫做停用词(stop words),一般使用黑名单(停用词名单)把这些词过滤掉。
停用词对结果毫无帮助,必须过滤掉的词
反文档频率:IDF
相当于一个词被那些文章包含了,如果包含的文章越多,那么这歌词就越没有刻画能力(100篇文章,99篇都包含,那这么次肯定不重要)
这样词就用另外一个标量来表示:IDF
最常见的词(“的”、“是”、“在”)给予最小的权重
较常见的词(“国内”、“中国”、“报道”)给予较小的权重
较少见的词(“养殖”、“维基”)给予较小的权重
将TF和IDF进行相乘,就得到了一个词的TF-IDF值,某个词对文章重要性越高,该值越大,于是排在前面的几个词,就是这篇文章的关键词。(关于写错次的情况,隐马尔可夫模型可以解决)
IDF得统计多篇文章才能得到
计算步骤:
拿原来的TF来计算,TF忽大忽小,非常不均匀,没有很好的归一,所以做了以下处理。
词频(TF)= 某个词在文章中出现的次数
词频标准化:
1.词频(TF)= 某个词在文章中出现的次数/文章的总词数
2.词频(TF)= 某个词在文章中出现的次数/该文出现次数最多的词的出现次数
反文档频率(IDF)= log(语料库的文档总数/包含该词的文档数+1)
log是把这个值压缩到了一个范围,包含该词的文档数+1是因为防止分母为0。包含该词的文档数越大这个词就越不重要(可以参考log函数)。
TF-IDF = 词频(TF)*反文档频率(IDF)
TF-IDF与一个词在文档中的出现次数成正比,与包含该词的文档数成反比。
总结:
优点:简单快速,结果比较符合实际情况
缺点:单纯以“词频”做衡量标准,不够全面,有时重要的次可能出现的次数并不多

 浙公网安备 33010602011771号
浙公网安备 33010602011771号