形式语言与自动机|文法产生语言
实验一 文法产生语言
一、实验目的
掌握文法的表示方式,理解文法产生语言的过程,并理解有穷文法产生无穷语言。
二、实验内容
1.文法的存储
可以使用两种存储方式:程序方式和文件方式;
程序方式是指将文法的四元组固定保存在程序中, 即一个程序处理一个文法。
文件方式是指将文法的四元组用文本方式存储,并定义格式,相应程序可以处理任意文法。
2.文法的表示
例如四元式表示:采用字符数组表示字母表和变量表,字符表示开始符号,字符串表示产生式组。(产生式符号向右箭头没有可以用“->”表示)
3.句子的产生
根据给定句子长度L生成所有长度不超过L的句子。
核心不详细步骤
首先理解:文法👇:一个四元组(变量,终结字符,产生式,开始字符)

主要就是理解“递归”
文法产生句子的递归程序的框架:
写了伪代码,尽量通过阅读 “每一行的代码注释,来理解每一行代码内容。”
开始时,句子是 文法的开始符号
然后递归程序,主要就是下面三部分:
1.递归出口1(句子不合法时,即句子长度大于给定长度L时,结束递归);
2.递归出口2(句子长度等于L时,检查句子合法性,如果合法输出句子,如果不合法就继续尝试dfs当前句子,再结束递归) ;
3.递归核心(替换句子中的非终结符变量):使用每个非终结符变量对应的产生式,替换当前句子中的非终结符变量
看程序前,画了个图,可以结合代码看👇

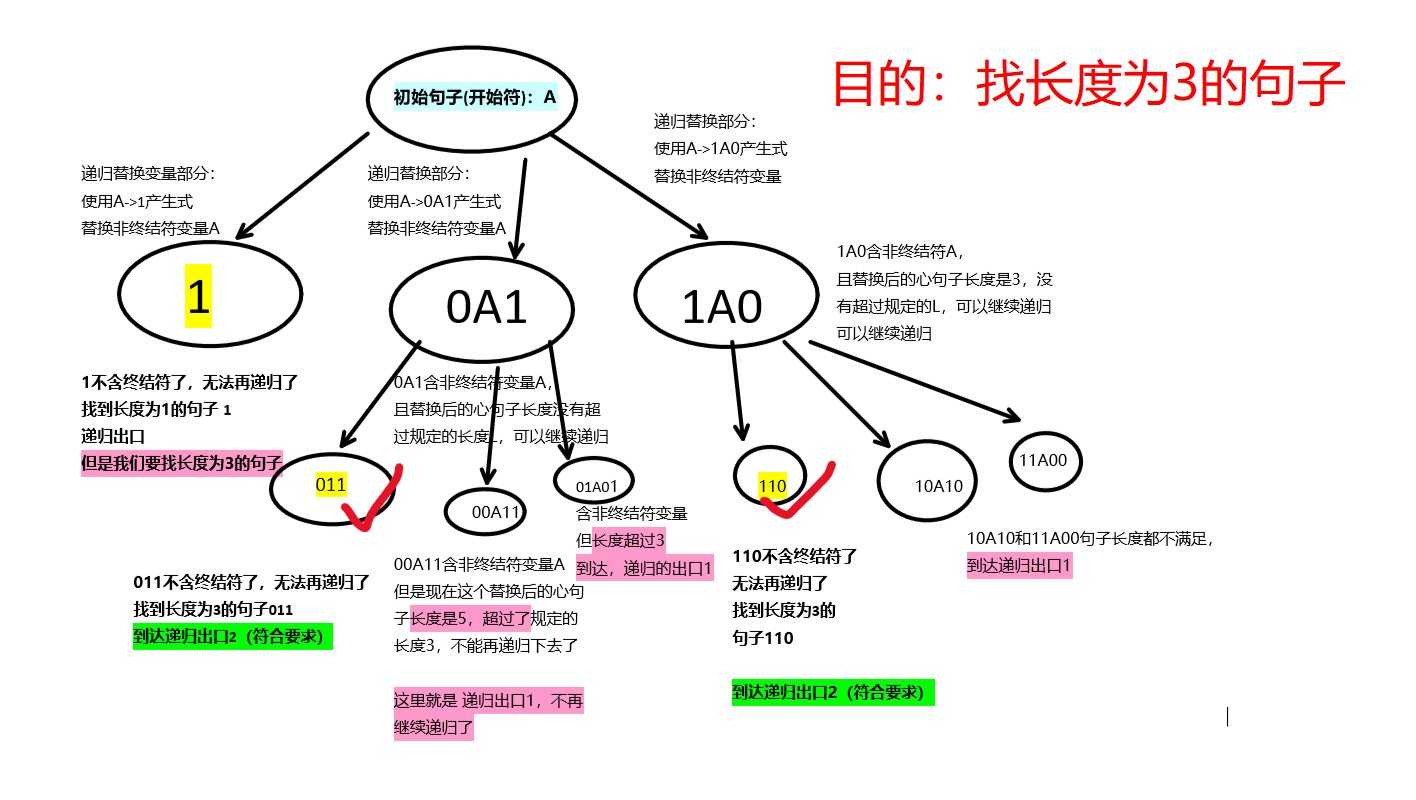
//调用递归程序
dfs(文法的开始符);
replace()//自己编写的函数,用于把当前sentence句子中的 "非终结符变量",每次使用对应的一个产生式来替换
check()//自己编写的函数,用于检查这个句子是否合法(合法的判断条件是: 当前句子不存在非终结符变量了);
//文法产生句子 "伪伪"代码
void dfs(string sentence){
//1.递归出口1
if(sentence.length() > L) { //递归出口: 当句子的长度>L时 直接return 结束这一层递归,就是不往下替换非终结符了
return; //return 就是结束递归,返回上一层
}
//2.递归出口2 可能满足我们要找的句子条件
if(sentence.length() == L){
if( check() == true ){ //check()是自己编写的函数,用于检查这个句子是否合法(合法的判断条件是: 当前句子不存在非终结符变量了);
//如果满足句子合法 执行下面语句
print(sentence)// 输出当前的合法句子
return; //当前句子全是终结符了,无需再用非终结符替换了; 直接return 结束这一层递归,就是不往下替换非终结符了
}
}
//3.核心: 替换句子中的非终结符变量部分
for(int i=0;i<sentence.length();i++){ //遍历当前的句子
if( sentence[i] 是 非终结符){
for( 遍历sentence[i]这个变量的每一个产生式){
string newSentence = replace(sentence[i]非终结符变量,产生式右端) //把当前sentence句子中的 "非终结符变量",每次使用一个产生式来替换
dfs(newSentence) //递归新的句子
}
}
}
}
下面正式写代码了
##1-1.文法存储,面向对象编程,Grammer类 ###其实不需要按照我这样,只使用数组存储,也可以的;使用集合、map映射是为了在查找的时候更加简便;如果只用数组存就只能暴力的遍历查找不优雅。 Java中遍历集合的方法(List集合、Set集合和Map集合) 使用set集合(HashSet)存储“变量集合” 使用set集合(HashSet)存储“终结符集合” 使用map双列映射(HashMap)存储(产生式左端,产生式右端的集合)映射。“ (key:value)键值对,其中‘产生式左端’是key,产生式右端的集合是‘value’ ” 代码如下👇 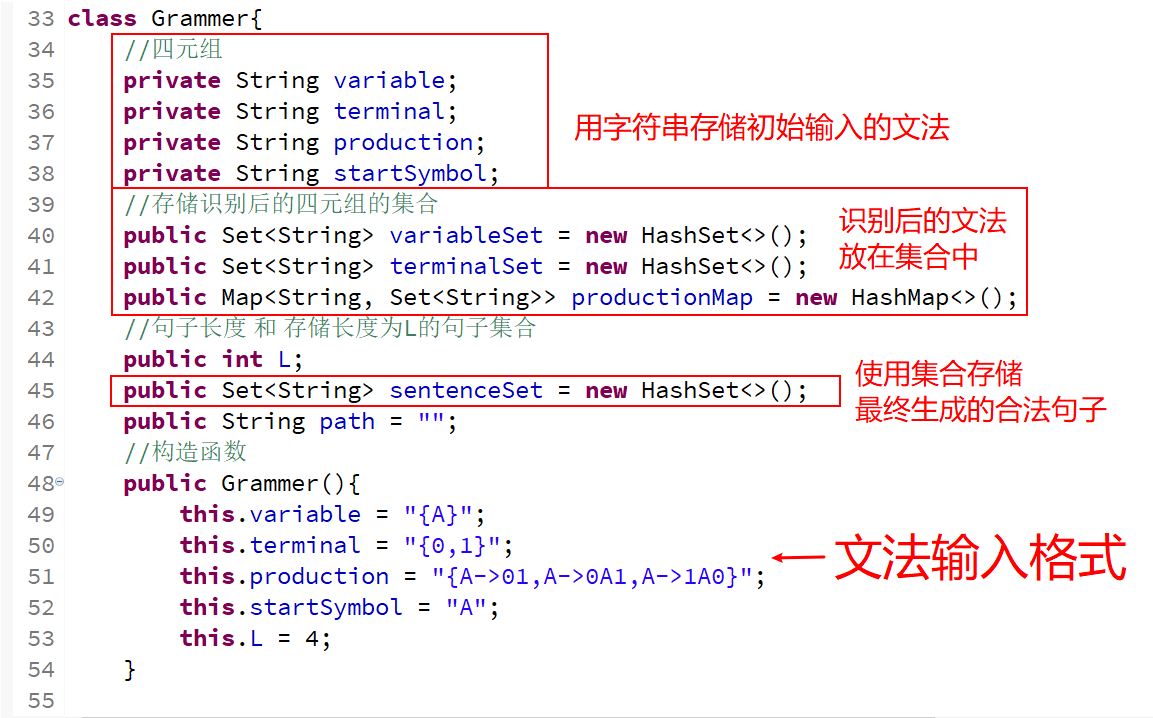
1-2.程序方式初始化文法(固定文法产生句子)
一个程序处理一个文法,用一个固定的文法产生长度为L的句子
随便选一个固定的文法四元组。
可以看下面代码,一个函数对应一个文法,就是在这个函数中构造好它的四元组
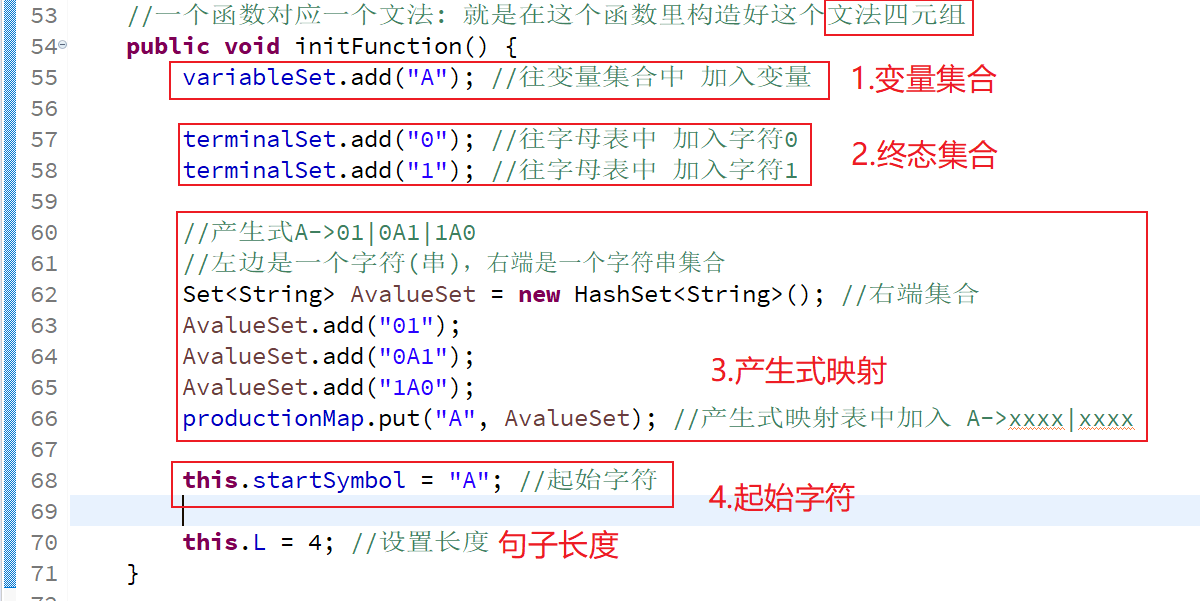
1-3.文法递归产生句子
同上述,文法递归程序的框架。
👇
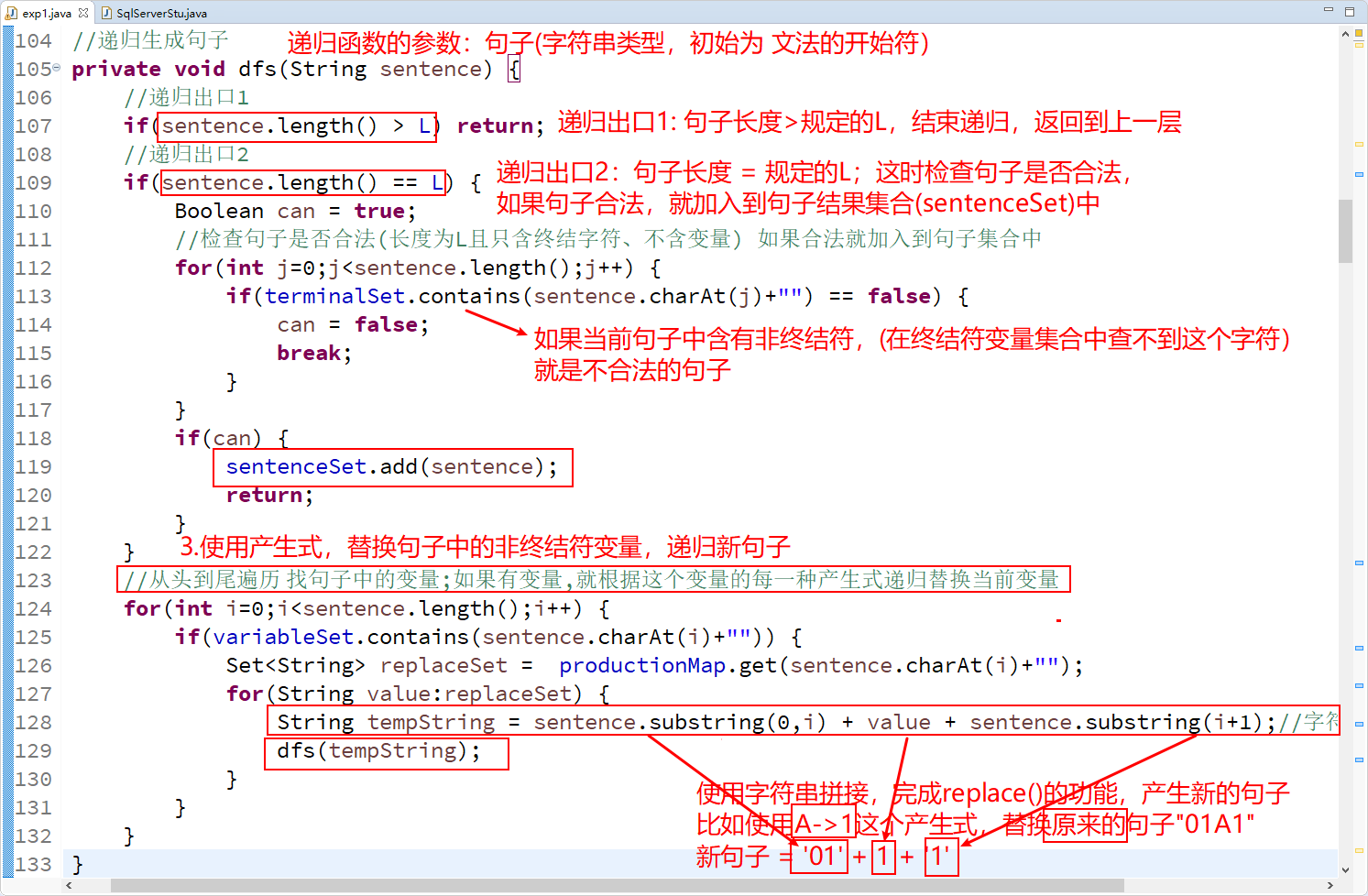
run函数,初始化句子参数是 “文法的开始符号”

##1-4.输出所有合法的句子

主函数运行:👇

2-1.从文件中读入文法
路径👇

文件格式👇

从文件加载文法代码👇

2-2.文法识别,从文件中加载文法
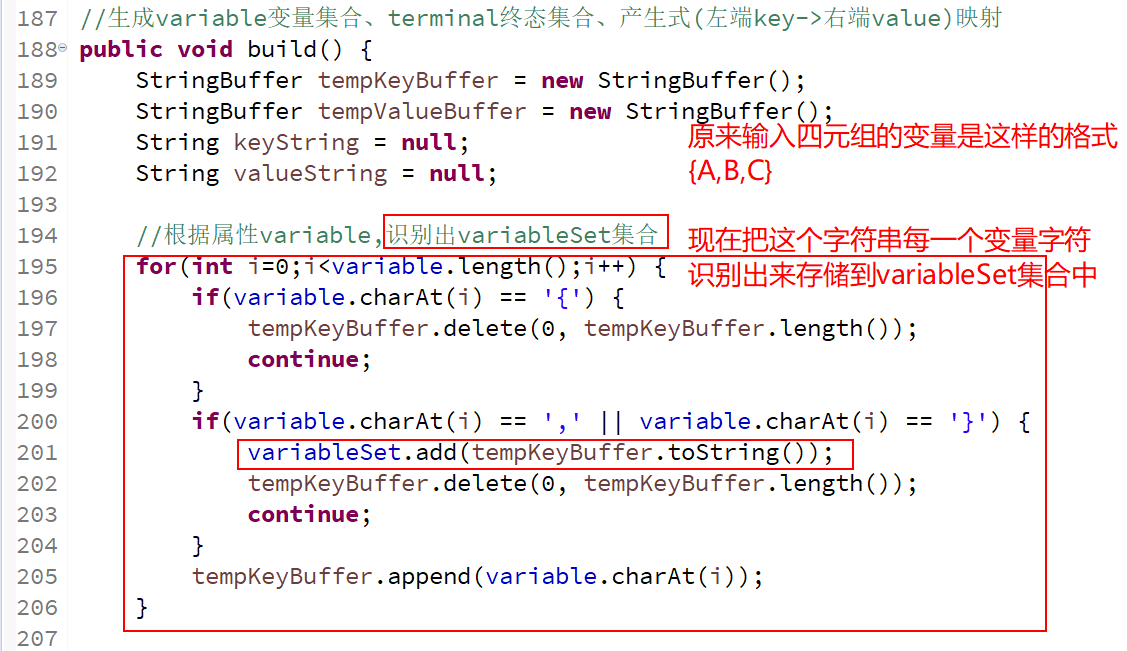
给出的是4元组,需要把变量、终结符、产生式、开始符这些字符串给区分出来
以,{ -> 这些字符来把变量、终结符、产生式分隔
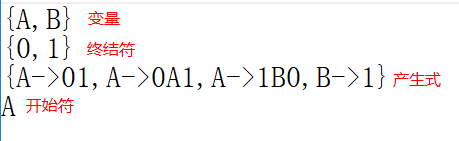
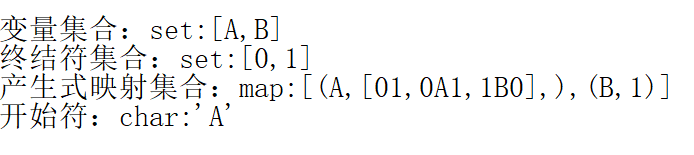
变量识别👇
终结符识别👇

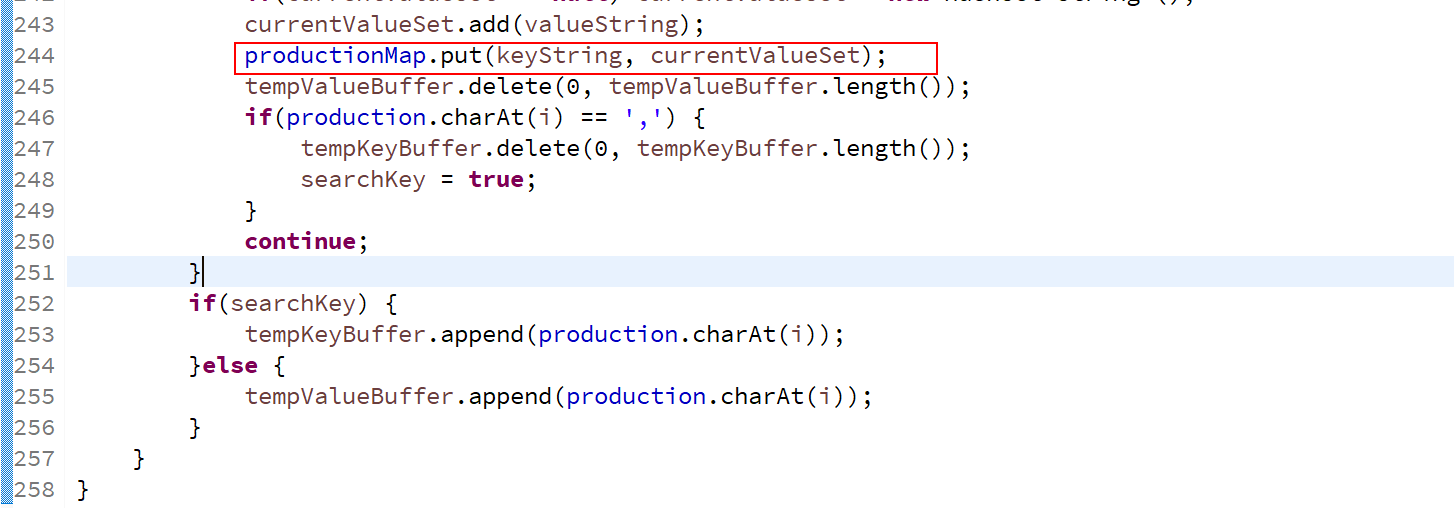
产生式识别👇,集合映射表hashMap,使得每一个产生式左端变量,对应一个产生式右端集合
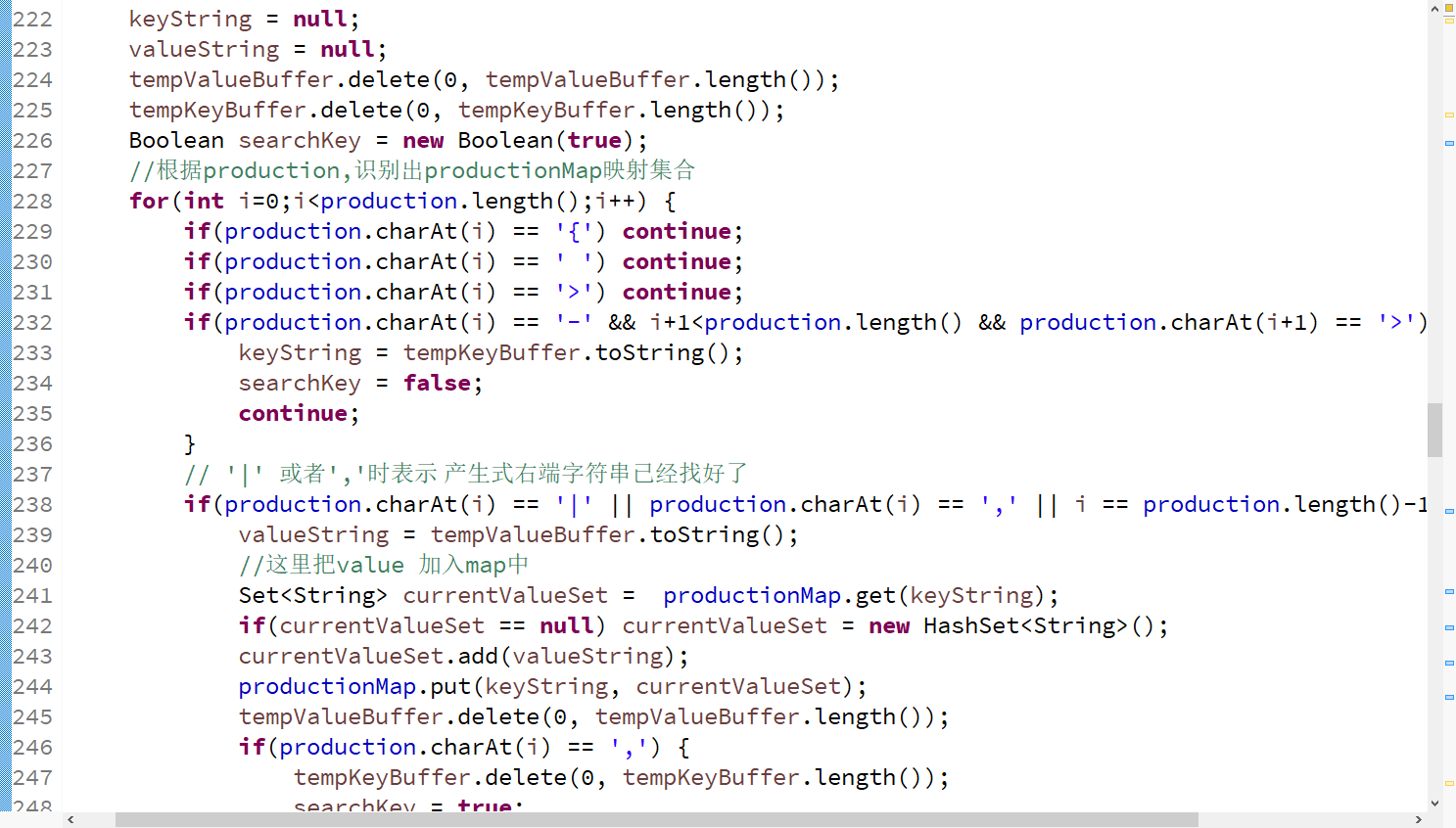
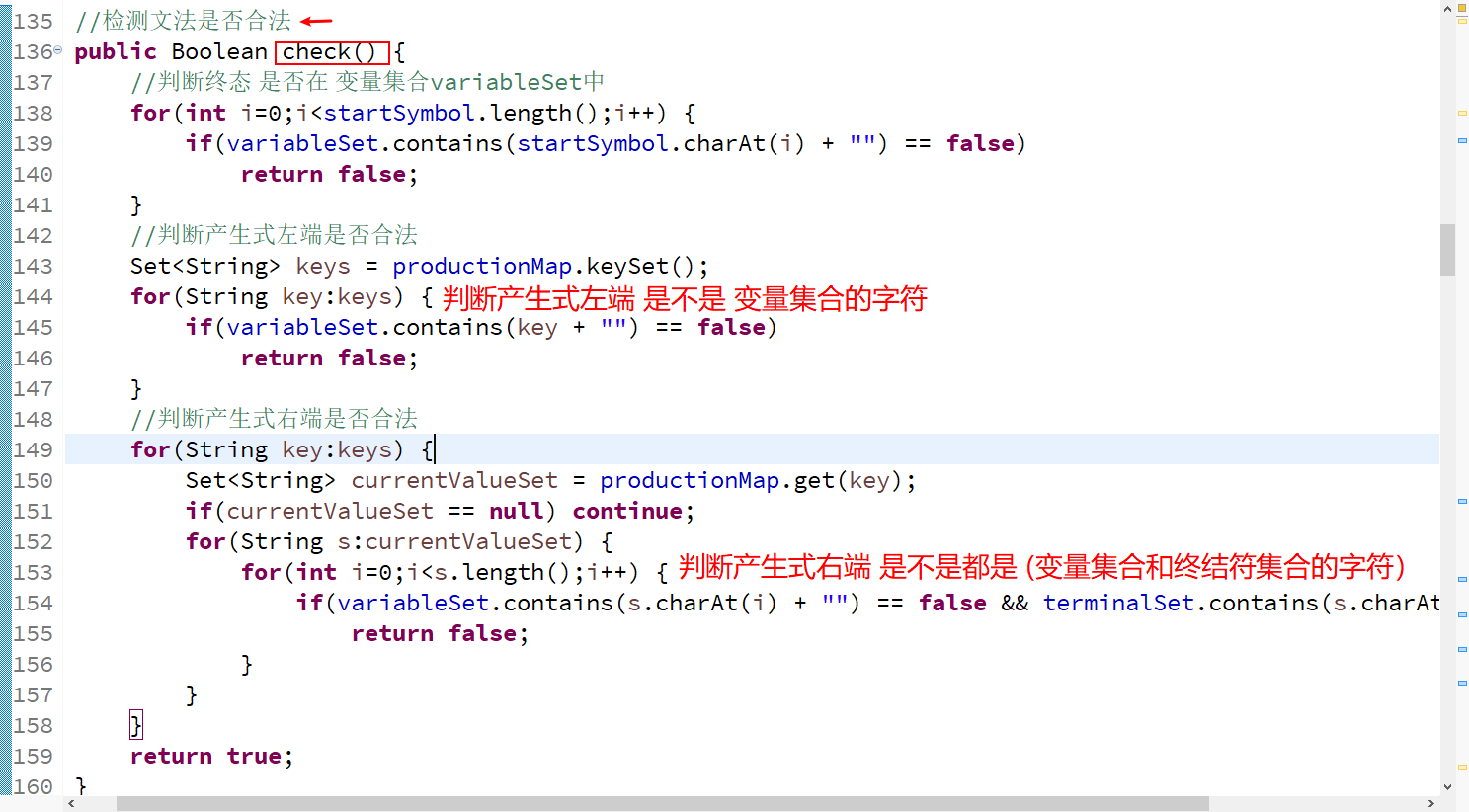
##2-3.文法合法性检测(可省略) 1.检查产生式左端每一个字符是否都是 “当前文法的,非终结符变量集合的字符”; 2.检查产生式右端每一个字符是否都是 “当前文法的,非终结符变量集合 U 终结符变量集合” 代码如下👇
##2-4.文法递归产生句子 同上述,文法递归程序的框架。 👇
2-5.输出所有合法的句子
首先面向对象编程,编写Grammer文法类
然后从程序中固定的手动构造四元组,或者从文件读入文法字符串,
然后识别文法,
最后核心就是上面的“文法递归程序的框架”。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号