Kafka
消息
– 消息”是在两台计算机间传送的数据单位。消息可以非常简单,例如只包含文本字符串;也可以更复杂,可能包含嵌入对象。
• 消息队列
消息队列是在消息的传输过程中保存消息的容器,消息传递中间人。
提供路由并保证消息的传递。
如果发送消息时接收者丌可用,消息队列会保留消息,直到可以成功地传递它。
分布式应用中,消息队列是互相交换信息的一种技术。可驻留在内存或磁盘上,队列存储消息直到它们被应用程序读走。
通过消息队列,应用程序可独立地执行--松耦合。
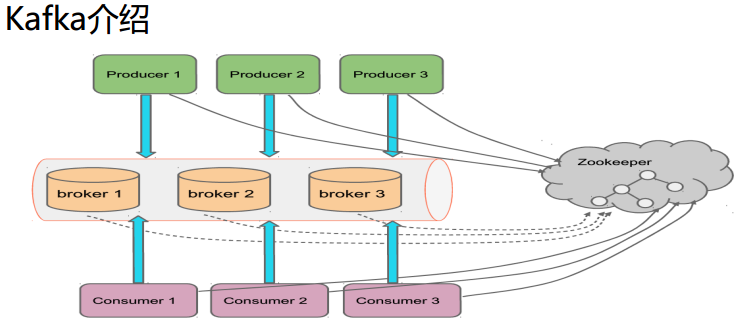
在kafka中,发送消息者称为Producer,而消息接收者称为Consumer
Producer和consumer都依赖于Zookeeper来保证系统可用性,为集群保存一些meta信息
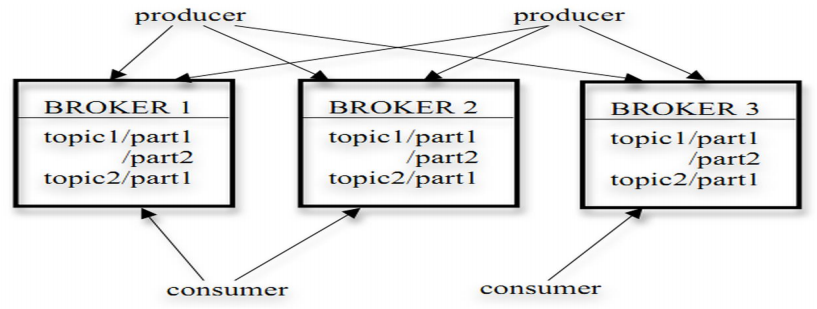
上图是每个topic都有三个备份,如果没有三个备份,一个topic的不同的partition可以分到不同的broker上。
Kafka集群有多个实例组成,每个节点称为broker。对消息保存时,根据Topic进行归类(是一个逻辑概念,相当于一个分布式队列),为了加快读取速度,多个consumer可以划分为一个组,并进行消费一个topic。
Producer :消息生产者,就是向Kafkabroker发消息的客户端。
Consumer :消息消费者,向Kafkabroker取消息的客户端。
Broker :Kafkacluster 是由多个broker组成,一台Kafka服务器就是一个broker。 一个broker可以容纳多个topic。
Topic :可以理解为一个队列。
Partition:
为了实现扩展性,一个非常大的topic可以分布到多个broker(服务器)上,一个topic由多个partition组成,每个partition是一个有序的队列。 partition中的每条消息都会被分配一个有序的id(offset)。
Producer通过Partitioner决定消息发送到哪个Partition,跟mr 的partitioner类似
kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。


根据offset查找消息的方法
1,按照二分法找到小于1008的segment,也就是00000000000000001000.log和00000000000000001000.index
2,用目标offset减去文件名中的offset得到消息在这个segment中的偏移量。也就是1008-1000=8,偏移量是8。
3,再次用二分法在index文件中找到对应的索引,也就是第三行6,45。
4,到log文件中,从偏移量45的位置开始(实际上这里的消息offset是1006),顺序查找,直到找到offset为1008的消息。查找期间kafka是按照log的存储格式来判断一条消息是否结束的。

kafka也自带了zookeeper
topic分为多个partition,每个partition有两个备份,0,1表示在每个备份所在broker的id


 浙公网安备 33010602011771号
浙公网安备 33010602011771号