软件各种架构图收集
发布一企业技术架构图,供大家参考。

该技术架构图是本人根据多年企业技术架构经验而制定,是企业技术的总架构图,希望对CTO们有所借鉴。
简单说明:
1.中间件基础运行环境是经过统一规划的以WebLogic、JBOSS为主的集群环境
2.企业集成平台是以基础业务应用为基础服务于上层平台和基础业务应用的高度集成平台
3.数据中心是企业公共数据的集中管理比如用户数据、企业编码,可以通过数据集成平台或服务集成平台分发给其他应用
项目做了不少,都没画过架构图,这次被要求画图,画的很丑,请大家看图本身包含的系统架构信息
一、架构整体图

1、核心是两库一线
1.1 接口总线
所有算法功能抽象成接口,其中大部分接口的方法都是泛型方法,是为了解决某一大类问题的
1.2 代码库
代码库包含现接口总线中接口的各种实现
1.3 应用库
提供用户的界面或者提供给外部的服务
是通过容器配置调用算法库中的代码来实现的各种应用
二、应用关系图

1、应用通过配置从应用库中组装出自己的应用系统
2、应用本身之外的东西尽量使用拦截器处理(授权访问、权限数据推送、异常处理、缓存、日志等)
3、使用消息队列做高并发应用支撑(秒杀类似应用)
4、使用分布式任务系统做周期作业、数据维护、数据计算等
ENode架构图

什么是ENode
ENode是一个.NET平台下,纯C#开发的,基于DDD,CQRS,ES,EDA,In-Memory架构风格的,可以帮助开发者开发高并发、高吞吐、可伸缩、可扩展的应用程序的一个应用开发框架。
- 开源项目地址:https://github.com/tangxuehua/enode
- 作者博客地址:http://www.cnblogs.com/netfocus/category/496012.html
- QQ交流群号:185916873
- 微信公众号:ENode
ENode框架特色
- 一个DDD开发框架,完美支持基于六边形架构思想的开发
- 实现CQRS架构思想,并且框架提供C端命令的处理结果的返回,支持同步返回和异步返回
- 内置Event Sourcing(ES)架构模式,让C端的数据持久化变得通用化
- 聚合根常驻内存,in-memory domain model
- 聚合根的处理基于Command Mailbox, Event Mailbox的思想,类似Actor Model, Actor Mailbox
- 严格遵守聚合内强一致性、聚合之间最终一致性的原则
- Group Commit Domain event
- 基于聚合根ID+事件版本号的唯一索引,实现聚合根的乐观并发控制
- 框架保证Command的幂等处理
- 通过聚合根ID对命令或事件进行路由,做到最小的并发冲突、最大的并行处理
- 消息发送和接收基于分布式消息队列EQueue,支持分布式部署
- 基于事件驱动架构范式(EDA,Event-Driven Architecture)
- 基于队列的动态扩容/缩容
- EventDB中因为存放的都是不可变的事件,所以水平扩展非常容易,框架可内置支持
- 支持Process Manager(Saga),以支持一个用户操作跨多个聚合根的业务场景,如订单处理,从而避免分布式事务的使用
- ENode实现了CQRS架构面临的大部分技术问题,让开发者可以专注于业务逻辑和业务流程的开发,而无需关心纯技术问题
晚上把公司应用的架构结合之前研究的东西梳理了下,整理了一张架构规划图,贴在这里备份

下面是个人理解的做架构的几个要点:
1、系统安全
这是首要考虑的,以这张图为例,网络划分为3个区:
a) DMZ区可以直接公网访问,也可以 与App Core区互通,但不能直接与DB Core区互通 (通常这里放置 反向代理Web服务器)
b) App Core区能与DMZ区、DB Core区互通,但是无法直接从公网访问 (通常这里放置 应用服务器、中间件服务器之类)
c) DB Core区仅与App Core区互通 (通常这里放置 核心数据库)
2、尽量消除单点故障
上图中,除了“硬件负载均衡”节点外,其它节点都可以部署成集群(DB有点特殊,传统RDBMS要实现分布式/集群还是比较困难的,要看具体采用的数据库产品,并非所有数据库都能方便的做Sharding),Jboss本身可以通过Domain模式+mod_cluster实现集群、Redis通过Master/Slave以Sentinel方式可以实现HA、IBM MQ本身就支持集群、FTP Server配合底层储存阵列也可以做到HA、Nginx静态资源服务器自不必说
3、成本
尽量采用开源成熟产品,jboss、redis、nginx、apache、mysql、rabbit MQ都是很好的选择。硬件负载均衡通常成本不低,但是效果明显,如果实在没钱,域名解析采用DNS轮询策略,也能达到类似效果,只不过可靠性略差。
4、Database问题
常规企业应用中,传统关系型数据仍然是主流,但是no-sql经过这几年发展,技术也日渐成熟了,一些非关键数据可以适当采用no-sql数据库,比如:系统日志、报文历史记录这类相对比较独立,而且增长迅速的数据,可以考虑存储到no-sql db甚至HDFS、TFS等分布式开源文件系统中。
如果系统数据量级达到单机RDBMS的上限,尽早考虑Sharding方案,目前mysql在这方面比较成熟,其它数据库就不好说了。
5、性能
web server、app server这些一般都可以通过集群实现横向扩张,满足性能日常增长的需求。最大的障碍还是DB,如果规模真达到了DB的上限,还是考虑换分布式DB或者迁移到“云”上吧。
HBase 系统架构图

组成部件说明 Client: 使用HBase RPC机制与HMaster和HRegionServer进行通信 Client与HMaster进行通信进行管理类操作 Client与HRegionServer进行数据读写类操作 Zookeeper: Zookeeper Quorum存储-ROOT-表地址、HMaster地址 HRegionServer把自己以Ephedral方式注册到Zookeeper中,HMaster随时感知各个HRegionServer的健康状况 Zookeeper避免HMaster单点问题 HMaster: HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master在运行 主要负责Table和Region的管理工作: 1 管理用户对表的增删改查操作 2 管理HRegionServer的负载均衡,调整Region分布 3 Region Split后,负责新Region的分布 4 在HRegionServer停机后,负责失效HRegionServer上Region迁移 HRegionServer: HBase中最核心的模块,主要负责响应用户I/O请求,向HDFS文件系统中读写数据

HRegionServer管理一些列HRegion对象; 每个HRegion对应Table中一个Region,HRegion由多个HStore组成; 每个HStore对应Table中一个Column Family的存储; Column Family就是一个集中的存储单元,故将具有相同IO特性的Column放在一个Column Family会更高效
HStore: HBase存储的核心。由MemStore和StoreFile组成。 MemStore是Sorted Memory Buffer。用户写入数据的流程:

Client写入 -> 存入MemStore,一直到MemStore满 -> Flush成一个StoreFile,直至增长到一定阈值 -> 触发Compact合并操作 -> 多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除 -> 当StoreFiles Compact后,逐步形成越来越大的StoreFile -> 单个StoreFile大小超过一定阈值后,触发Split操作,把当前Region Split成2个Region,Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer上,使得原先1个Region的压力得以分流到2个Region上。 由此过程可知,HBase只是增加数据,有所得更新和删除操作,都是在Compact阶段做的,所以,用户写操作只需要进入到内存即可立即返回,从而保证I/O高性能。
HLog 引入HLog原因: 在分布式系统环境中,无法避免系统出错或者宕机,一旦HRegionServer意外退出,MemStore中的内存数据就会丢失,引入HLog就是防止这种情况 工作机制: 每个HRegionServer中都会有一个HLog对象,HLog是一个实现Write Ahead Log的类,每次用户操作写入Memstore的同时,也会写一份数据到HLog文件,HLog文件定期会滚动出新,并删除旧的文件(已持久化到StoreFile中的数据)。当HRegionServer意外终止后,HMaster会通过Zookeeper感知,HMaster首先处理遗留的HLog文件,将不同region的log数据拆分,分别放到相应region目录下,然后再将失效的region重新分配,领取到这些region的HRegionServer在Load Region的过程中,会发现有历史HLog需要处理,因此会Replay HLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复。
HBase存储格式 HBase中的所有数据文件都存储在Hadoop HDFS文件系统上,格式主要有两种: 1 HFile HBase中KeyValue数据的存储格式,HFile是Hadoop的二进制格式文件,实际上StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile 2 HLog File,HBase中WAL(Write Ahead Log) 的存储格式,物理上是Hadoop的Sequence File
HFile

图片解释: HFile文件不定长,长度固定的块只有两个:Trailer和FileInfo Trailer中指针指向其他数据块的起始点 File Info中记录了文件的一些Meta信息,例如:AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等 Data Index和Meta Index块记录了每个Data块和Meta块的起始点 Data Block是HBase I/O的基本单元,为了提高效率,HRegionServer中有基于LRU的Block Cache机制 每个Data块的大小可以在创建一个Table的时候通过参数指定,大号的Block有利于顺序Scan,小号Block利于随机查询 每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成, Magic内容就是一些随机数字,目的是防止数据损坏
HFile里面的每个KeyValue对就是一个简单的byte数组。这个byte数组里面包含了很多项,并且有固定的结构。

KeyLength和ValueLength:两个固定的长度,分别代表Key和Value的长度 Key部分:Row Length是固定长度的数值,表示RowKey的长度,Row 就是RowKey Column Family Length是固定长度的数值,表示Family的长度 接着就是Column Family,再接着是Qualifier,然后是两个固定长度的数值,表示Time Stamp和Key Type(Put/Delete) Value部分没有这么复杂的结构,就是纯粹的二进制数据
HLog File

HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是“写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。 HLog Sequece File的Value是HBase的KeyValue对象,即对应HFile中的KeyValue
结束语:这篇文章是我专门在网上弄下来的,算是hbase部分的终极篇吧,我的服务端的源码系列也要基于这个顺序来开展。
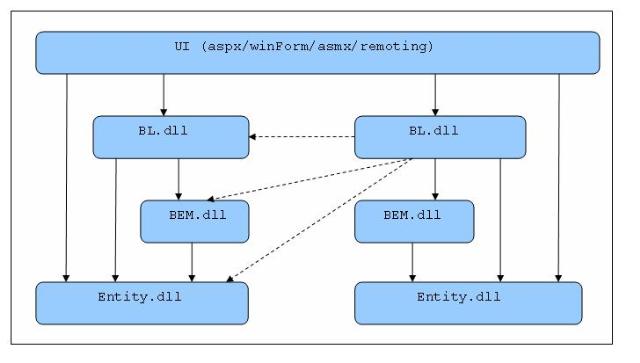
一.三层架构图
二.系统各层次职责
1.UI(User Interface)层的职责是数据的展现和采集,数据采集的结果通常以Entity object提交给BL层处理。Service Interface侧层用于将业务或数据资源发布为服务(如WebServices)。
2.BL(Business Logic)层的职责是按预定的业务逻辑处理UI层提交的请求。
(1)Business Function 子层负责基本业务功能的实现。
(2)Business Flow 子层负责将Business Function子层提供的多个基本业务功能组织成一个完整的业务流。(Transaction只能在Business Flow 子层开启。)
3.ResourceAccess层的职责是提供全面的资源访问功能支持,并向上层屏蔽资源的来源。
(1)BEM(Business Entity Manager)子层采用DataAccess子层和ServiceAccess子层来提供业务需要的基础数据/资源访问能力。
(2)DataAccess子层负责从数据库中存取资源,并向BEM子层屏蔽所有的SQL语句以及数据库类型差异。
DB Adapter子层负责屏蔽数据库类型的差异。
ORM子层负责提供对象-关系映射的功能。
Relation子层提供ORM无法完成的基于关系(Relation)的数据访问功能。
(3)ServiceAccess子层用于以SOA的方式从外部系统获取资源。
注: Service Entrance用于简化对Service的访问,它相当于Service的代理,客户直接使用Service Entrance就可以访问系统发布的服务。Service Entrance为特定的平台(如Java、.Net)提供强类型的接口,内部可能隐藏了复杂的参数类型转换。
(4)ConfigAccess子层用于从配置文件中获取配置object或将配置object保存倒配置文件。
4.Entity侧层跨越UI/BEM/ResourceManager层,在这些层之间传递数据。Entity侧层中包含三类Entity,如下图所示:
三.Aspect
Aspect贯穿于系统各层,是系统的横切关注点。通常采用AOP技术来对横切关注点进行建模和实现。
1.Securtiy Aspect:用于对整个系统的Security提供支持。
2.ErrorHandling Aspect:整个系统采用一致的错误/异常处理方式。
3.Log Aspect:用于系统异常、日志记录、业务操作记录等。
四.规则
1.系统各层次及层内部子层次之间都不得跨层调用。
2.Entity object 在各个层之间传递数据。
3.需要在UI层绑定到列表的数据采用基于关系的DataSet传递,除此之外,应该使用Entity object传递数据。
4.对于每一个数据库表(Table)都有一个DB Entity class与之对应,针对每一个Entity class都会有一个BEM Class与之对应。
5.有些跨数据库或跨表的操作(如复杂的联合查询)也需要由相应的BEM Class来提供支持。
6.对于相对简单的系统,可以考虑将Business Function子层和Business Flow 子层合并为一个。
7.UI层和BL层禁止出现任何SQL语句。
五.错误与异常
异常可以分为系统异常(如网络突然断开)和业务异常(如用户的输入值超出最大范围),业务异常必须被转化为业务执行的结果。
1.DataAccess层不得向上层隐藏任何异常(该层抛出的异常几乎都是系统异常)。
2.要明确区分业务执行的结果和系统异常。比如验证用户的合法性,如果对应的用户ID不存在,不应该抛出异常,而是返回(或通过out参数)一个表示验证结果的枚举值,这属于业务执行的结果。但是,如果在从数据库中提取用户信息时,数据库连接突然断开,则应该抛出系统异常。
3.在有些情况下,BL层应根据业务的需要捕获某些系统异常,并将其转化为业务执行的结果。比如,某个业务要求试探指定的数据库是否可连接,这时BL就需要将数据库连接失败的系统异常转换为业务执行的结果。
4.UI层(包括Service层)除了从调用BL层的API获取的返回值来查看业务的执行结果外,还需要截获所有的系统异常,并将其解释为友好的错误信息呈现给用户。
六.项目组织目结构
以BAS系统为例。
1.主目录结构:

2.命名空间命名:每个dll的根命名空间即是该dll的名字,如EAS.BL.dll的根命名空间就是EAS.BL。每个根命名空间下面可以根据需求的分类而增加子命名空间,比如,EAS.BL的子空间EAS.BL.Order与EAS.BL.Permission分别处理不同的业务逻辑。
3.包含众多子项目的庞大项目的物理组织:
核心子项目Core的位置:
Core子项目中包含一些公共的基础设施,如错误处理、权限控制方面等。
七.发布服务与服务回调
以EAS系统为例。

1.同UI层的Page一样,服务也不允许抛出任何异常,而是应该以返回错误码(int型,1表示成功,其它值表示失败)的形式来表明服务调用出现了错误,如果方法有返回值,则返回值以out参数提供。
2. 如果BAS系统提供了WebService(Remoting)服务,则BAS必须提供BAS.Entrance.dll。 BAS.Entrance.dll封装了与BAS服务交换信息的通信机制,客户系统只要通过BAS.Entrance.dll就可以非常简便地访问BAS 提供的服务。
3.如果BAS需要通过WebService(Remoting)回调客户系统,则必须提供仅仅定义了接口的BAS.CallBack.dll,客户系统将引用该dll,实现其中的接口,并将其发布为服务,供BAS回调。
4.当WebService的参数或返回值需要是复杂类型――即架构图中的Service Entity,则Service Entity应该在对应的BAS.EntranceParaDef.dll或BAS.CallBackParaDef.dll中定义。 WebService定义的方法中的复杂类型应该使用Xml字符串代替(注意,Entrance和CallBack接口对应服务的方法的参数是强类型的),而Xml字符串和复杂类型对象之间的转换应当在BAS.Entrance.dll或BAS.CallBack.dll中实现。
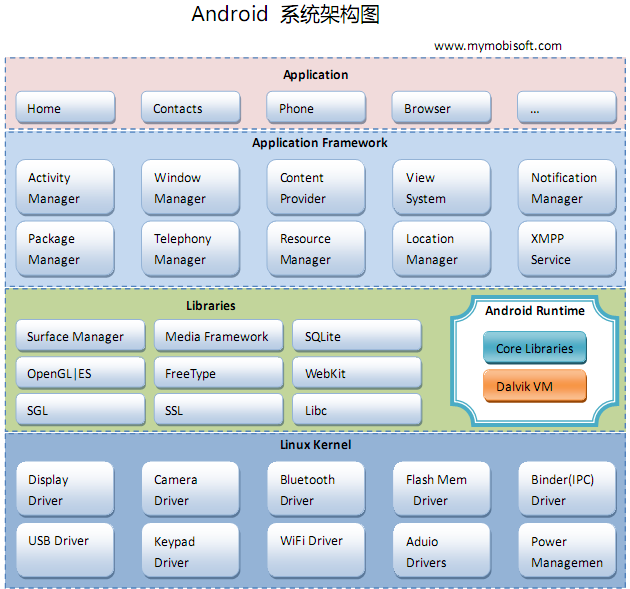
从上图中可以看出,Android系统架构为四层结构,从上层到下层分别是应用程序层、应用程序框架层、系统运行库层以及Linux内核层,分别介绍如下:
1)应用程序层
Android平台不仅仅是操作系统,也包含了许多应用程序,诸如SMS短信客户端程序、电话拨号程序、图片浏览器、Web浏览器等应用程序。这些应用程序都是 用Java语言编写的,并且这些应用程序都是可以被开发人员开发的其他应用程序所替换,这点不同于其他手机操作系统固化在系统内部的系统软件,更加灵活和个 性化。
2)应用程序框架层
应用程序框架层是我们从事Android开发的基础,很多核心应用程序也是通过这一层来实现其核心功能的,该层简化了组件的重用,开发人员可以直接使用其提 供的组件来进行快速的应用程序开发,也可以通过继承而实现个性化的拓展。
a) Activity Manager(活动管理器)
管理各个应用程序生命周期以及通常的导航回退功能
b) Window Manager(窗口管理器)
管理所有的窗口程序
c) Content Provider(内容提供器)
使得不同应用程序之间存取或者分享数据
d) View System(视图系统)
构建应用程序的基本组件
e) Notification Manager(通告管理器)
使得应用程序可以在状态栏中显示自定义的提示信息
f) Package Manager(包管理器)
Android系统内的程序管理
g)Telephony Manager(电话管理器)
管理所有的移动设备功能
h)Resource Manager(资源管理器)
提供应用程序使用的各种非代码资源,如本地化字符串、图片、布局文件、颜色文件等
i)Location Manager(位置管理器)
提供位置服务
j)XMPP Service(XMPP服务)
提供Google Talk服务
3)系统运行库层
从图中可以看出,系统运行库层可以分成两部分,分别是系统库和Android运行时,分别介绍如下:
a)系统库
系统库是应用程序框架的支撑,是连接应用程序框架层与Linux内核层的重要纽带。其主要分为如下几个:
Ø Surface Manager:
执行多个应用程序时候,负责管理显示与存取操作间的互动,另外也负责2D绘图与3D绘图进行显示合成。
Ø Media Framework:
多媒体库,基于PacketVideo OpenCore;支持多种常用的音频、视频格式录制和回放,编码格式包括MPEG4、MP3、H.264、AAC、ARM。
Ø SQLite:
小型的关系型数据库引擎
Ø OpenGL|ES:
根据OpenGL ES 1.0API标准实现的3D绘图函数库
Ø FreeType:
提供点阵字与向量字的描绘与显示
Ø WebKit:
一套网页浏览器的软件引擎
Ø SGL:
底层的2D图形渲染引擎
Ø SSL:
在Andorid上通信过程中实现握手
Ø Libc:
从BSD继承来的标准C系统函数库,专门为基于embedded linux的设备定制
b)Android运行时
Android应用程序时采用Java语言编写,程序在Android运行时中执行,其运行时分为核心库和Dalvik虚拟机两部分。
Ø 核心库
核心库提供了Java语言API中的大多数功能,同时也包含了Android的一些核心API,如android.os、android.net、android.media等等。
Ø Dalvik虚拟机
Android程序不同于J2me程序,每个Android应用程序都有一个专有的进程,并且不是多个程序运行在一个虚拟机中,而是每个Android程序都有一 个Dalivik虚拟机的实例,并在该实例中执行。Dalvik虚拟机是一种基于寄存器的Java虚拟机,而不是传统的基于栈的虚拟机,并进行了内存资源使用的优化 以及支持多个虚拟机的特点。需要注意的是,不同于J2me,Android程序在虚拟机中执行的并非编译后的字节码,而是通过转换工具dx将Java字节码转成dex格 式的中间码。
4)Linux内核层
Android是基于Linux2.6内核,其核心系统服务如安全性、内存管理、进程管理、网路协议以及驱动模型都依赖于Linux内核。
Entity Framework的全称是ADO.NET Entity Framework,是微软开发的基于ADO.NET的ORM(Object/Relational Mapping)框架。
Entity Framework的主要特点:
1. 支持多种数据库(Microsoft SQL Server, Oracle, and DB2);
2. 强劲的映射引擎,能很好地支持存储过程;
3. 提供Visual Studio集成工具,进行可视化操作;
4. 能够与ASP.NET, WPF, WCF, WCF Data Services进行很好的集成。

架构图一

架构图2
刚刚来到一家新公司,首先会对项目进行一个大致了解,研究了两天了,有了个总体的把握了,下面就是我这个小菜鸟画的简单系统架构图!

有的时候架构庞大的吓人,有的时候架构一眼看穿,但里面却暗藏杀机,真的需要我们去认真学习,揣摩!
不久前在园子里面看过一篇文章其中说道,设计架构无非就是一个字 → “拆”,当时看到这个字,想起来还真的是这么一回事,不过这里面去包含了很多的东西,我们现在就是不知道怎么拆,这个也不是一时半会能够了解的,需要我们认认真真的做,慢慢的积累,到时候就知道怎么拆了,而且还拆的很到位,所以加油!
对于这个拆字园友们也给出了很多的理解,这是只是个人看法!
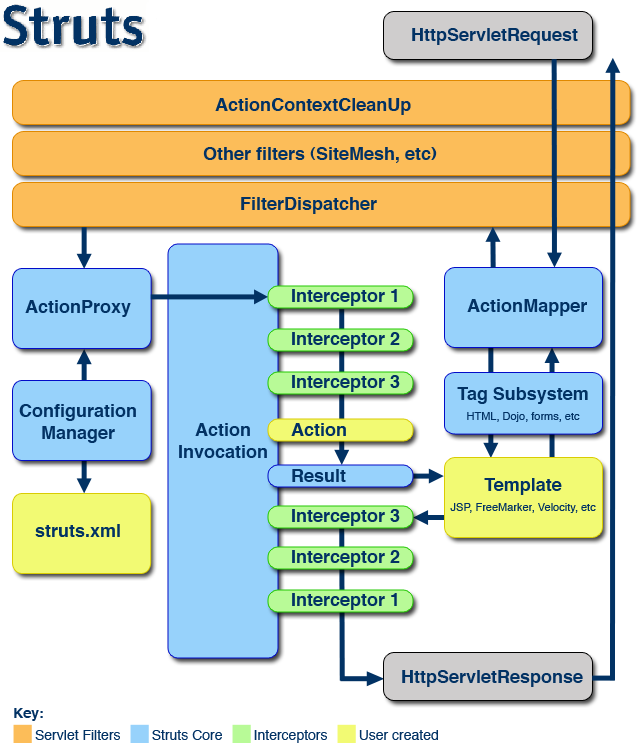
Struts2架构图
请求首先通过Filter chain,Filter主要包括ActionContextCleanUp,它主要清理当前线程的ActionContext和Dispatcher;FilterDispatcher主要通过AcionMapper来决定需要调用哪个Action。
ActionMapper取得了ActionMapping后,在Dispatcher的serviceAction方法里创建ActionProxy,ActionProxy创建ActionInvocation,然后ActionInvocation调用Interceptors,执行Action本身,创建Result并返回,当然,如果要在返回之前做些什么,可以实现PreResultListener。
Struts2部分类介绍
这部分从Struts2参考文档中翻译就可以了。
ActionMapper
ActionMapper其实是HttpServletRequest和Action调用请求的一个映射,它屏蔽了Action对于Request等java Servlet类的依赖。Struts2中它的默认实现类是DefaultActionMapper,ActionMapper很大的用处可以根据自己的需要来设计url格式,它自己也有Restful的实现,具体可以参考文档的docs\actionmapper.html。
ActionProxy&ActionInvocation
Action的一个代理,由ActionProxyFactory创建,它本身不包括Action实例,默认实现DefaultActionProxy是由ActionInvocation持有Action实例。ActionProxy作用是如何取得Action,无论是本地还是远程。而ActionInvocation的作用是如何执行Action,拦截器的功能就是在ActionInvocation中实现的。
ConfigurationProvider&Configuration
ConfigurationProvider就是Struts2中配置文件的解析器,Struts2中的配置文件主要是尤其实现类XmlConfigurationProvider及其子类StrutsXmlConfigurationProvider来解析,
Struts2请求流程
1、客户端发送请求
2、请求先通过ActionContextCleanUp-->FilterDispatcher
3、FilterDispatcher通过ActionMapper来决定这个Request需要调用哪个Action
4、如果ActionMapper决定调用某个Action,FilterDispatcher把请求的处理交给ActionProxy,这儿已经转到它的Delegate--Dispatcher来执行
5、ActionProxy根据ActionMapping和ConfigurationManager找到需要调用的Action类
6、ActionProxy创建一个ActionInvocation的实例
7、ActionInvocation调用真正的Action,当然这涉及到相关拦截器的调用
8、Action执行完毕,ActionInvocation创建Result并返回,当然,如果要在返回之前做些什么,可以实现PreResultListener。添加PreResultListener可以在Interceptor中实现,不知道其它还有什么方式?
短连接聊天服务 ,每半分钟刷新一次..
客户端可切换3种渲染模式,全位图blit传输:sprite区块和MC
架构图:

模块与模块之间的通信也通过sendNotifcation发送消息。
神仙道寻路方法:
1. 2点是否可以直接到达,可以,则不走寻路,直接行进 2. 2点不能直接到达,进行寻路,找不到结果,寻找替代点 3. 正常寻路
关于flash共享库:
如果a的库里的资源设置了共享资源并设置了一个url 把a发布的swf放到设置的url的位置 b引入a的库里共享的资源..再发布b..这时b会自动从那个设置的url加载a
浏览器缓存地址:C:\Documents and Settings\Administrator\Local Settings\Temporary Internet Files
网页游戏的swf都加载到这里了。
<深度排序>
那就不停的 遍历 更具显示对象的Y 设置它们再容器里面的深度 不知道把同屏显示对象的Y再数组里面排序好 再设置深度 速度快 还是变排序边设置深度快 并且在数组里面排序好 这种方法要速度很好
把图层封装成一个类。 和NPC和玩家都共同继承一个接口 iworldObject 加一个属性 depth. 创建的时候设置 这个属性。然后sortOn("depth");
Array.Numberic 啊 默认都是 从小到大排序的 depth 是他的一个属性 npc 也统一有这个属性 然后就不用y轴排序了,看你的 y+height 挺纠结的 统一用 depth 这个属性排序
这里判断这个 玩家的深度如果已经符合,就不要排序。 setChildIndex 消耗挺大的
PS: 在看三层架构的时候,找的了一个我感觉不错的材料,里面有如下一张图,打算详细的解释一下这张图,也总结一下三层的知识
一、系统各层次职责
1.UI(User Interface)层的职责是数据的展现和采集,数据采集的结果通常以Entity object提交给BL层处理Service Interface侧层用于将业务或数据资源发布为服务(如WebServices)。
2.BL(Business Logic)层的职责是按预定的业务逻辑处理UI层提交的请求。
(1)Business Function 子层负责基本业务功能的实现。
(2)Business Flow 子层负责将Business Function子层提供的多个基本业务功能组织成一个完整的业务流(Transaction只能在Business Flow 子层开启。)
3.ResourceAccess层的职责是提供全面的资源访问功能支持,并向上层屏蔽资源的来源。
(1)BEM(Business Entity Manager)子层采用DataAccess子层和ServiceAccess子层来提供业务需要的基础数据/资源访问能力。
(2)DataAccess子层负责从数据库中存取资源,并向BEM子层屏蔽所有的SQL语句以及数据库类型差异。
DB Adapter子层负责屏蔽数据库类型的差异。
ORM子层负责提供对象-关系映射的功能。
Relation子层提供ORM无法完成的基于关系(Relation)的数据访问功能。
(3)ServiceAccess子层用于以SOA的方式从外部系统获取资源。
注:Service Entrance用于简化对Service的访问,它相当于Service的代理,客户直接使用Service Entrance就可以访问系统发布的服务。Service Entrance为特定的平台(如Java、.Net)提供强类型的接口,内部可能隐藏了复杂的参数类型转换。
(4)ConfigAccess子层用于从配置文件中获取配置object或将配置object保存倒配置文件。
4.Entity侧层跨越UI/BEM/ResourceManager层,在这些层之间传递数据。Entity侧层中包含三类Entity,如下图所示:
二、Aspect
Aspect贯穿于系统各层,是系统的横切关注点。通常采用AOP技术来对横切关注点进行建模和实现。
1.Securtiy Aspect:用于对整个系统的Security提供支持。
2.ErrorHandling Aspect:整个系统采用一致的错误/异常处理方式。
3.Log Aspect:用于系统异常、日志记录、业务操作记录等。
三、规则
1.系统各层次及层内部子层次之间都不得跨层调用。
2.Entity object 在各个层之间传递数据。
3.需要在UI层绑定到列表的数据采用基于关系的DataSet传递,除此之外,应该使用Entity object传递数据。
4.对于每一个数据库表(Table)都有一个DB Entity class与之对应,针对每一个Entity class都会有一个BEM Class与之对应。
5.有些跨数据库或跨表的操作(如复杂的联合查询)也需要由相应的BEM Class来提供支持。
6.对于相对简单的系统,可以考虑将Business Function子层和Business Flow 子层合并为一个。
7.UI层和BL层禁止出现任何SQL语句。
四、错误与异常
异常可以分为系统异常(如网络突然断开)和业务异常(如用户的输入值超出最大范围),业务异常必须被转化为业务执行的结果。
1.DataAccess层不得向上层隐藏任何异常(该层抛出的异常几乎都是系统异常)。
2.要明确区分业务执行的结果和系统异常。比如验证用户的合法性,如果对应的用户ID不存在,不应该抛出异常,而是返回(或通过out参数)一个表示验证 结果的枚举值,这属于业务执行的结果。但是,如果在从数据库中提取用户信息时,数据库连接突然断开,则应该抛出系统异常。
3.在有些情况下,BL层应根据业务的需要捕获某些系统异常,并将其转化为业务执行的结果。比如,某个业务要求试探指定的数据库是否可连接,这时BL就需要将数据库连接失败的系统异常转换为业务执行的结果。
4.UI层(包括Service层)除了从调用BL层的API获取的返回值来查看业务的执行结果外,还需要截获所有的系统异常,并将其解释为友好的错误信息呈现给用户。
五、项目组织目结构
以BAS系统为例。
1.主目录结构:
2.命名空间命名:每个dll的根命名空间即是该dll的名字,如EAS.BL.dll的根命名空间就是EAS.BL。每个根命名空间下面可以根据需求的 分类而增加子命名空间,比如,EAS.BL的子空间EAS.BL.Order与EAS.BL.Permission分别处理不同的业务逻辑。
3.包含众多子项目的庞大项目的物理组织:
核心子项目Core的位置:
Core子项目中包含一些公共的基础设施,如错误处理、权限控制方面等。
六、发布服务与服务回调
以EAS系统为例。
1.同UI层的Page一样,服务也不允许抛出任何异常,而是应该以返回错误码(int型,1表示成功,其它值表示失败)的形式来表明服务调用出现了错误,如果方法有返回值,则返回值以out参数提供。
2.如果BAS系统提供了WebService(Remoting)服务,则BAS必须提供BAS.Entrance.dll。 BAS.Entrance.dll封装了与BAS服务交换信息的通信机制,客户系统只要通过BAS.Entrance.dll就可以非常简便地访问BAS 提供的服务。
3.如果BAS需要通过WebService(Remoting)回调客户系统,则必须提供仅仅定义了接口的BAS.CallBack.dll,客户系统将引用该dll,实现其中的接口,并将其发布为服务,供BAS回调。
4.当WebService的参数或返回值需要是复杂类型――即架构图中的Service Entity,则Service Entity应该在对应的BAS.EntranceParaDef.dll或BAS.CallBackParaDef.dll中定义。 WebService定义的方法中的复杂类型应该使用Xml字符串代替(注意,Entrance和CallBack接口对应服务的方法的参数是强类型 的),而Xml字符串和复杂类型对象之间的转换应当在BAS.Entrance.dll或BAS.CallBack.dll中实现。
之前用一张图分析了Google给出的MVP架构,但是在Google给出的所有案例里面除了基本的MVP架构还有其它几种架构,今天就来分析其中的Clean架构。同样的,网上介绍Clean架构的文章很多,我也就不用文字过多叙述了,还是用一张类图来分析一下Clean架构的这个案例吧。好了,先直接上图!

上完图,再说一说我对Clean架构的一个理解吧。对比前一篇文章的MVP架构图可以看出,clean在一定程度上继承了mvp的设计思想,但是其抽象程度比mvp更高。初次看这个demo的时候,确实被震撼了一下——原来用Java可以这样写代码!!!跟之前用的一些项目框架和我自己平时写的一些代码对比一下,只能感叹clean的这种设计思想真不是一般的程序员可以想出来的。它对接口、抽象类和实现类之间的实现、继承、调用关系发挥到了一个比较高的层次,它并不是像我们平时写代码那样很直白地写下来,而是充分利用了面向对象的封装性、继承性和多态性,是对面向对象思想的一个高度理解。其实,要说clean复杂,它确实有些难理解,可是如果你真的理解了面向对象思想,那么又会觉得这样的设计完全在情理之中。
最近几个月都没有整理Blog,都忙着整理总结之前一段时间做的项目和学习的内容,然后想到把这些东西融合在一起,设计一个开发框架。
这个框架用到了一些.NET社区比较前沿的技术,比如ORM, IOC容器, AOP拦截等,在.NET 2.0的基础上构建了一个.NET Remoting的分布式开发框架。
项目开发最关注的就是开发效率,其次是项目的可管理可控性,最后是架构的可扩展性。我希望在我的框架设计中能够将这三者很好的整合在一起。
大致的思路是:
1、可扩展性:通过IOC容器的使用降低项目中各个模块之间的依赖性;用领域模式来设计业务核心层,降低业务层对数据层和界面层的耦合度;分布式选择Remoting为主,可以再包装为WebService或者直接发布为WebService。
2、将敏捷的项目管理思路引入到框架中,框架充分支持TDD测试驱动和运行日志驱动,为敏捷管理提供技术支持。
3、初步通过AOP技术减少和核心业务无关的系统级代码:如事务处理、异常处理、日志记录等;并在将来为架构提供可视化的代码配置生成工具,以最快的速度构建项目的主体结构,并尽可能大的增大灵活性。
目前框架的主体已经完成,也重新整理VSS上的项目结构,并重新命名为LightningFramework。正在做细节调整,接下来的时间会逐步完成相关文档和演示程序。下面是主架构图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号