2023-3-24美团一面
美团到店广告
1.平常参加过什么项目,收获最大(A*算法具体实现)
A*寻路算法其实也不复杂,首先有以下几个概念:
- 开启的节点表(OpenList)
- 存放着所有的待检测的节点(坐标),每次都会从其中寻找出符合某个条件的节点。
- 关闭的节点表(ClosedList)存放着所有不会被检测的节点(坐标),每次检测都会忽略它们。
算法的核心是启发式的权值比较,分为G值和H值。一般我们将按非斜向方向移动的距离定为10,斜向为14
- G值
标准术语:g(n)表示从初始节点到任意节点n的代价。当前节点的G值等于移动前节点的G值加上移动到当前节点的距离。如果新路径到相邻点的距离更短,G值更小,更新相邻节点的G值。因此,同一个节点的G值会因为选取的MinFNode不同而改变。 - H值
标准术语:h(n)表示从节点n到目标点的启发式评估代价。当前节点到终点的距离。固定不变的值。计算H值,忽略障碍(可以认为没有障碍),只计算最近的距离。 - F值
F值为G值和H值之和
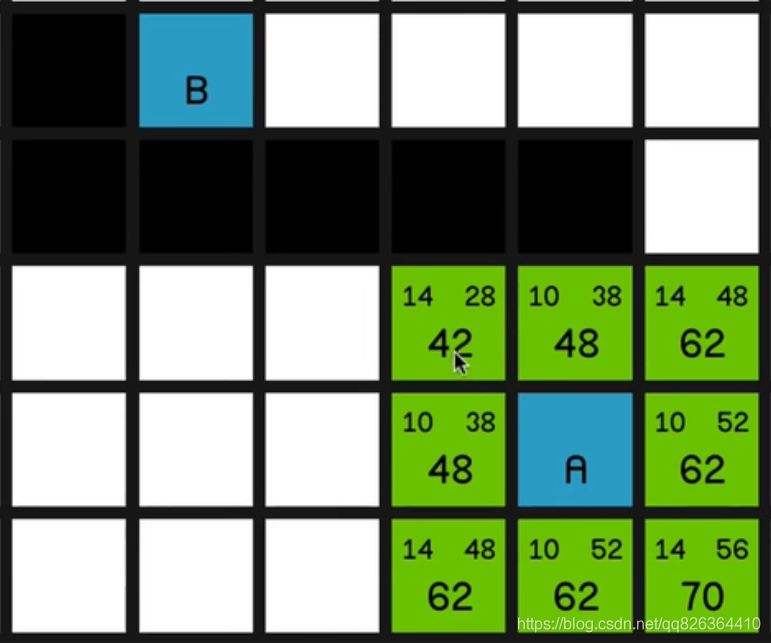
算法的实现思路:
1.将起点放入OpenList中
2.利用While(OpenList.Count)循环, 只要OpenList.Count大于0, 就一直循环执行3, 4, 5步骤。
3.寻找开启列表中的F最小的节点MinFNode,如果F相同,选取H最小的。同时把MinFNode从OpenList移除,放入ClosedList中
4.遍历MinFNode周围的节点,忽略障碍节点和已在ClosedList中的节点,这里会有3种情况
- 相邻点不在OpenList中的,计算H值和G值(MinFNode的G值加上移动所产生的G值),并且把该相邻点的父节点设置为MinFNode (后期找到终点后,需要用父节点进行路径回溯,画出路线。),加入到开启列表OpenList中。
- 相邻点已在OpenList中的,则判断从MinFNode节点的G值加上到相邻点移动所产生的G值之和,是否小于该相邻点的G值,假设小于了,则更新该相邻点的G值为较小的那个,然后重新设置该相邻点的父节点为MinFNode
- 假设遍历到的节点是终点,则按MinFNode的父节点进行回溯,获取到起点的路径,找到最终路径
5.如果没有找到终点,回到第3步,继续执行
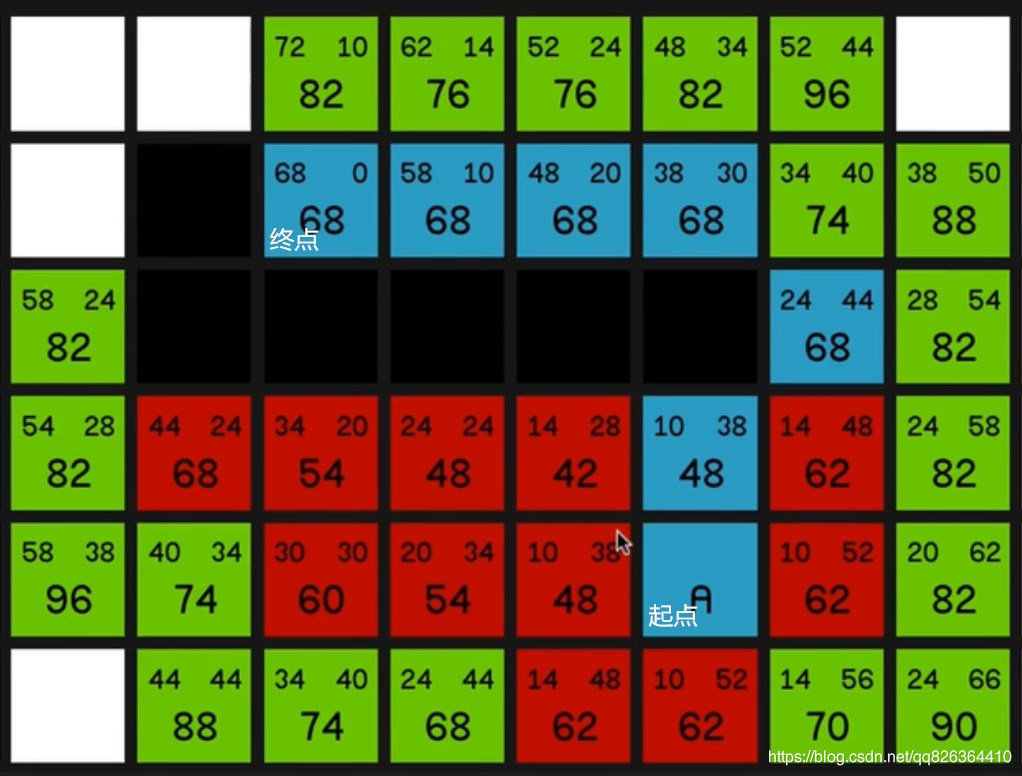
D*算法(Dynamic A Star)
符号及函数说明
Openlist是一个可以用来做广度优先搜索的队列
节点state的标识tag分为三类:没有加入过open表的(new)、在open表的(open)、曾经在open表但现在已经被移走的(closed)。
每个节点到终点G的代价为h,两个节点(state)之间的开销为C(X,Y),X到终点的代价h为上一个节点(父节点)Y到终点的代价+X和Y之间的开销
每个节点的最小h值为k,代表了该点在全图环境中到G点的最小代价,在计算和更新过程中,对于标识为new的点,k=h,对于标识为open的点,k=min{ k,newh},对于closed的点,k=min{ k,newh}。
算法最主要的是两个函数,Process-State 和 Modify-Cost,前者用于计算到目标G的最优路径,后者用于改变两个节点(state)之间的开销C(X,Y) 并将受影响的节点(state)置于Openlist中。
首次搜索
将终点置于Openlist中,采用Dijkstra进行搜索,直到搜索到了起点,结束。搜索结束后,每个搜索过的节点标识为closed,每个节点的k=h,其父节点为邻域中k值最小的那个。
当搜索结束后,可以通过从起点开始找父节点,一路搜索到终点。若搜索结束时Openlist不为空,则里头的节点h的值必然不必起点的h值小。
碰到障碍
若当前点的下一个点(父节点)为障碍,修改其h值并将其放入Openlist中(如果是墙的话就修改为墙的h值,比如无穷大),但其k值仍旧不变,即k=k=min{ k,newh},所以该点会被优先取出并且扩散展开。
扩散过程需要利用到论文中的伪代码 process-state,直到k_min>= state_h 。也就是如果扩散到某个节点的时候,计算后的h值不必其上次的k值小,该点就可以结束对外扩散了。
伪代码及注释
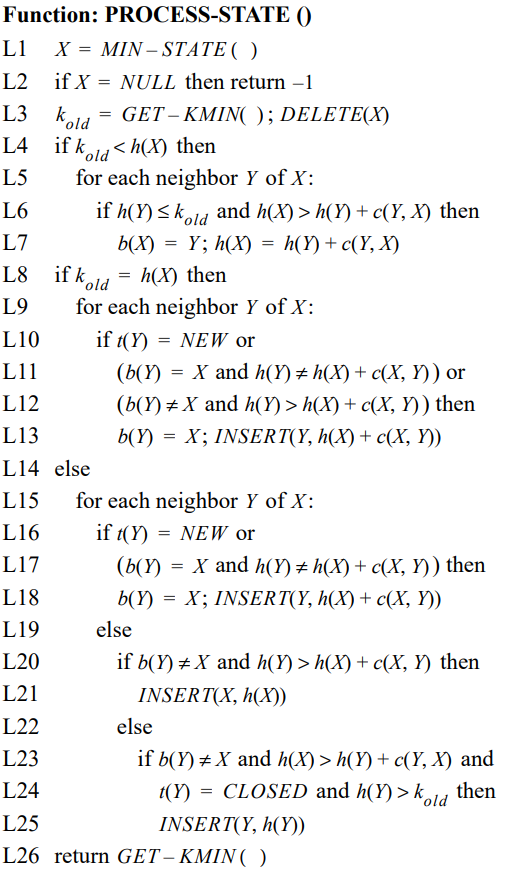
Process-State(): 用于计算到目标G的最优路径。
从open表中获取k值最小的节点,并移除该点。
对该点进行分类处理,遍历其邻域,看是否需要修改父节点、h值及添加到open表中,分类大体如下:
首先进行一次k_old<h(x)判断,看x的h值是否需要调整:
k_old<h(x): 说明该节点受到障碍的影响,x处于raise状态,可以设想x突变为墙时h值上升,或者其父节点受到突变为墙的节点影响,导致h值升高,最后影响到了他。
然后遍历其邻域,如果y点的h值没有上升,并且x的h值能通过该点变得更小。
上述情况,那就修改x的父节点为y,重置其h的值。
然后再重新判断,看y的h值是否需要调整:
k_old=h(x): 处于第一遍遍历的阶段,或者该节点x并没有受到障碍影响。
然后遍历其邻域,if后面的判断代表:y第一次被遍历到;或者y的父节点是X,但是h(y)和h(x)+c(x,y)值却不等, 由于k_old=h(x),这说明h(y)被更改了,但是h(x)还没有变;又或者y的父节点不是X,但是如果让X成为其父节点将拥有更小的h(y)值。
上述三种情况都应该根据x的h值调整y的h值,并将x作为y的父节点,并将y添加到open表中
k_old!=h(x): 说明该节点受到影响,遍历其邻域。
如果y为第一次遍历到的点;或者x是y的父节点,但是h(y)和h(x)+c(x,y)值却不等, 这说明h(x)被更改了,但是h(y)还没有变;
上述情况应该应该根据x的h值调整y的h值,并将x作为y的父节点,并将y添加到open表中。
如果y的父节点不是X,但是让X成为其父节点将拥有更小的h(y)值。
上述情况应该应该调整x的h值,并将x添加到open表中。
如果y的父节点不是X,但是让Y成为X父节点,X将拥有更小的h(x)值,并且y被已经被open表移除,且h(y)值在上升(即y受到影响)。
上述情况应该应该调整y的h值,并将y添加到open表中。
2.你能分析一下A*算法的时间复杂度吗
- BFS是盲目搜索,一直找邻居,直到找到目标;
- 迪杰斯特拉算法是基于代价的,算起点到当前点代价最小的;
- 贪婪优先算法是目标导向搜索,算当前点到目标代价最小的;
- A星是结合迪杰斯特拉算法和贪婪优先算法的寻路,维护2个列表,开放和封闭列表,每次寻路的时候,从开放列表找出一个总代价最小的节点,如果不是终点,就算出起点到当前位置的移动代价G和当前位置到终点的移动代价H,计算出总代价F,然后加入封闭列表,并把这个节点所有的邻居都遍历一遍,计算总代价,加入开放列表,然后循环遍历,直到找到终点。时间代价最大的是在每一层循环遍历处理所有节点环节上,如果以 N x M 地图来例,且每个节点邻接节点算上斜角的也才8个,记为 m。因此明确两点间的A*寻路时间复杂度 T(n) = n * (c1 + m) + c2,因此,时间复杂度为渐近O(n)
A*算法的时间复杂度是O(bd),其中b是分支因子,d是最短路径的深度。证明如下:A*算法是一种启发式搜索算法,它在搜索过程中,通过估价函数f(n)=g(n)+h(n)来评估每个节点n的优先级,其中g(n)表示从起点到节点n的实际代价,h(n)表示从节点n到目标节点的估计代价。在A*算法中,每次扩展优先级最高的节点,直到找到目标节点或者无法继续扩展为止。因此,A*算法的时间复杂度取决于估价函数h(n)的质量和搜索空间的大小。如果估价函数h(n)越准确,搜索空间就越小,时间复杂度就越低。如果估价函数h(n)不准确,搜索空间就越大,时间复杂度就越高。因此,A*算法的时间复杂度是O(bd),其中b是分支因子,d是最短路径的深度。
源: 与必应的对话, 2023年3月26日(1) 【寻路】A星算法浅析 - 知乎. https://zhuanlan.zhihu.com/p/103524779 访问时间 2023年3月26日.
(2) 最短路径算法之AStar算法(一) AStar算法的证明_astarinfo2 test; test.node=nullptr; test .... https://blog.csdn.net/jiaoyong2011/article/details/6270193 访问时间 2023年3月26日.
(3) 经典寻路算法:A* 算法 – CodeTalks. https://howardlau.me/programming/a-star-algorithm.html 访问时间 2023年3月26日.
3.挂号项目中的redis是怎么用的
4.redis里面的数据丢了,怎么办
AOF
AOF(*Append Only File*) 持久化功能,注意只会记录写操作命令,读操作命令是不会被记录。Redis 是先执行写操作命令后,才将该命令记录到 AOF 日志里
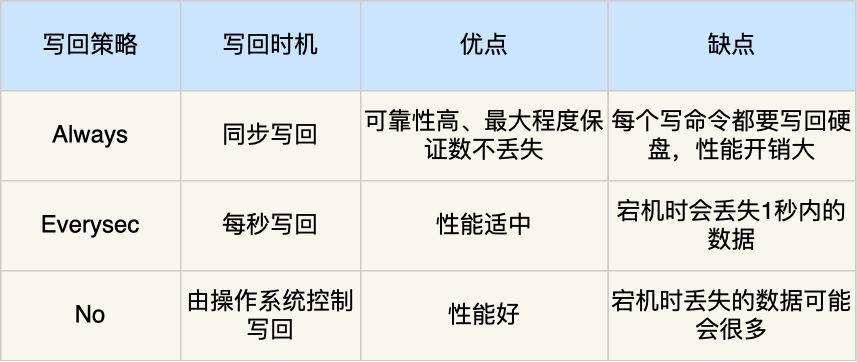
Redis 为了避免 AOF 文件越写越大,提供了 AOF 重写机制,当 AOF 文件的大小超过所设定的阈值后,Redis 就会启用 AOF 重写机制,来压缩 AOF 文件。重写机制的妙处在于,尽管某个键值对被多条写命令反复修改,最终也只需要根据这个「键值对」当前的最新状态,然后用一条命令去记录键值对,代替之前记录这个键值对的多条命令,这样就减少了 AOF 文件中的命令数量。最后在重写工作完成后,将新的 AOF 文件覆盖现有的 AOF 文件。
RDB
- RDB 文件的内容是二进制数据。
Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave,他们的区别就在于是否在「主线程」里执行:
- 执行了 save 命令,就会在主线程生成 RDB 文件,由于和执行操作命令在同一个线程,所以如果写入 RDB 文件的时间太长,会阻塞主线程;
- 执行了 bgsave 命令,会创建一个子进程来生成 RDB 文件,这样可以避免主线程的阻塞;
RDB 文件的加载工作是在服务器启动时自动执行的,Redis 并没有提供专门用于加载 RDB 文件的命令。
Redis 还可以通过配置文件的选项来实现每隔一段时间自动执行一次 bgsave 命令,默认会提供以下配置:
save 900 1
save 300 10
save 60 10000
// 900 秒之内,对数据库进行了至少 1 次修改;
// 300 秒之内,对数据库进行了至少 10 次修改;
// 60 秒之内,对数据库进行了至少 10000 次修改。
如果主线程(父进程)要修改共享数据里的某一块数据(比如键值对 A)时,就会发生写时复制,于是这块数据的物理内存就会被复制一份(键值对 A'),然后主线程在这个数据副本(键值对 A')进行修改操作。与此同时,bgsave 子进程可以继续把原来的数据(键值对 A)写入到 RDB 文件。
RDB 和 AOF 合体
尽管 RDB 比 AOF 的数据恢复速度快,但是快照的频率不好把握:
- 如果频率太低,两次快照间一旦服务器发生宕机,就可能会比较多的数据丢失;
- 如果频率太高,频繁写入磁盘和创建子进程会带来额外的性能开销。
那有没有什么方法不仅有 RDB 恢复速度快的优点和,又有 AOF 丢失数据少的优点呢?
当然有,那就是将 RDB 和 AOF 合体使用,这个方法是在 Redis 4.0 提出的,该方法叫混合使用 AOF 日志和内存快照,也叫混合持久化。
如果想要开启混合持久化功能,可以在 Redis 配置文件将下面这个配置项设置成 yes:
aof-use-rdb-preamble yes
混合持久化工作在 AOF 日志重写过程。
当开启了混合持久化时,在 AOF 重写日志时,fork 出来的重写子进程会先将与主线程共享的内存数据以 RDB 方式写入到 AOF 文件,然后主线程处理的操作命令会被记录在重写缓冲区里,重写缓冲区里的增量命令会以 AOF 方式写入到 AOF 文件,写入完成后通知主进程将新的含有 RDB 格式和 AOF 格式的 AOF 文件替换旧的的 AOF 文件。
也就是说,使用了混合持久化,AOF 文件的前半部分是 RDB 格式的全量数据,后半部分是 AOF 格式的增量数据。这样的好处在于,重启 Redis 加载数据的时候,由于前半部分是 RDB 内容,这样加载的时候速度会很快。
加载完 RDB 的内容后,才会加载后半部分的 AOF 内容,这里的内容是 Redis 后台子进程重写 AOF 期间,主线程处理的操作命令,可以使得数据更少的丢失。
5.能讲一下mongodb的持久化操作 吗
在1.8版本之后开始支持journal,就是我们常说的redo log,用于故障恢复和持久化
在2.0之后的版本,journal都是默认打开的,以确保数据安全
图解:
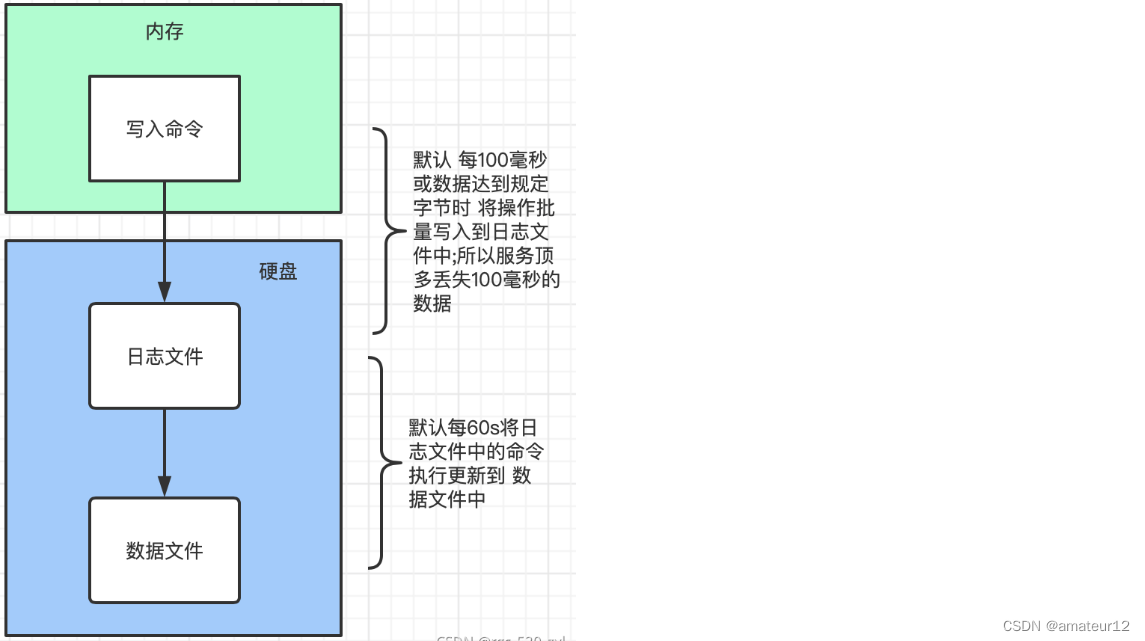
写入操作会记录journal日志,记录写入操作具体更改的磁盘地址和字节(如果服务器突然崩溃,启动时,journal会重放崩溃前并没有刷新到磁盘上的写操作)
数据文件每隔60s刷新到磁盘上,journal只需要持有60s内的写入数据。journal预分配了几个空文件用于此目的,位于/data/db/journal,命名为_j.0,_j.1等。
6.能讲一下bean的生命周期吗
7.两个bean本身没有依赖关系,强制让第二个bean先于第一个构造出来,如何实现
Spring 框架中很多地方都为我们提供了扩展点,很好的体现了开闭原则(OCP)。其中 BeanFactoryPostProcessor 可以允许我们在容器加载任何bean之前修改应用上下文中的BeanDefinition(从XML配置文件或者配置类中解析得到的bean信息,用于后续实例化bean)。
在本例中,就可以把A的初始化逻辑放在一个 BeanFactoryPostProcessor 中。
@Component
public class ABeanFactoryPostProcessor implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory configurableListableBeanFactory) throws BeansException {
A.initA();
}
}
执行效果:
A init
A construct
B construct
B init
这种方式把A中的初始化逻辑放到了加载bean之前,很适合加载系统全局配置,但是这种方式中初始化逻辑不能依赖bean的状态。
8.linux查看电脑的网络状态
9.电脑中有很多的time_wait状态,这是原因造成
2、问题分析
大量的 TIME_WAIT 状态 TCP 连接存在,其本质原因是什么?
1.大量的短连接存在
2.特别是 HTTP 请求中,如果 connection 头部取值被设置为 close 时,基本都由「服务端」发起主动关闭连接
3.而,TCP 四次挥手关闭连接机制中,为了保证 ACK 重发和丢弃延迟数据,设置 time_wait 为 2 倍的 MSL(报文最大存活时间)
TIME_WAIT 状态:
- 1.TCP 连接中,主动关闭连接的一方出现的状态;(收到 FIN 命令,进入 TIME_WAIT 状态,并返回 ACK 命令)
- 2.保持 2 个 MSL 时间,即,4 分钟;(MSL 为 2 分钟)
3、解决办法
解决上述 time_wait 状态大量存在,导致新连接创建失败的问题,一般解决办法:
1.客户端,HTTP 请求的头部,connection 设置为 keep-alive,保持存活一段时间:现在的浏览器,一般都这么进行了
2.服务器端 允许 time_wait 状态的 socket 被重用 缩减 time_wait 时间,设置为 1 MSL(即,2 mins)
结论:几个核心要点
1.time_wait 状态的影响:
- TCP 连接中,「主动发起关闭连接」的一端,会进入 time_wait 状态
- time_wait 状态,默认会持续 2 MSL(报文的最大生存时间),一般是 2x2 mins
- time_wait 状态下,TCP 连接占用的端口,无法被再次使用
- TCP 端口数量,上限是 6.5w(65535,16 bit)
- 大量 time_wait 状态存在,会导致新建 TCP 连接会出错,address already in use : connect 异常
2.现实场景:
- 服务器端,一般设置:不允许「主动关闭连接」
- 但 HTTP 请求中,http 头部 connection 参数,可能设置为 close,则,服务端处理完请求会主动关闭 TCP 连接
- 现在浏览器中, HTTP 请求 connection 参数,一般都设置为 keep-alive
- Nginx 反向代理场景中,可能出现大量短链接,服务器端,可能存在
3.解决办法:
- 服务器端允许 time_wait 状态的 socket 被重用
- 缩减 time_wait 时间,设置为 1 MSL(即,2 mins)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号