面试项目高频问题
1、找个印象最深的项目说说?(简历中不止一个项目)#
(A*算法具体实现)#
A*寻路算法其实也不复杂,首先有以下几个概念:
- 开启的节点表(OpenList) 存放着所有的待检测的节点(坐标),每次都会从其中寻找出符合某个条件的节点。
- 关闭的节点表(ClosedList) 存放着所有不会被检测的节点(坐标),每次检测都会忽略它们。
算法的核心是启发式的权值比较,分为G值和H值。一般我们将按非斜向方向移动的距离定为10,斜向为14
- G值
标准术语:g(n)表示从初始节点到任意节点n的代价。当前节点的G值等于移动前节点的G值加上移动到当前节点的距离。如果新路径到相邻点的距离更短,G值更小,更新相邻节点的G值。因此,同一个节点的G值会因为选取的MinFNode不同而改变。 - H值
标准术语:h(n)表示从节点n到目标点的启发式评估代价。当前节点到终点的距离。固定不变的值。计算H值,忽略障碍(可以认为没有障碍),只计算最近的距离。 - F值
F值为G值和H值之和
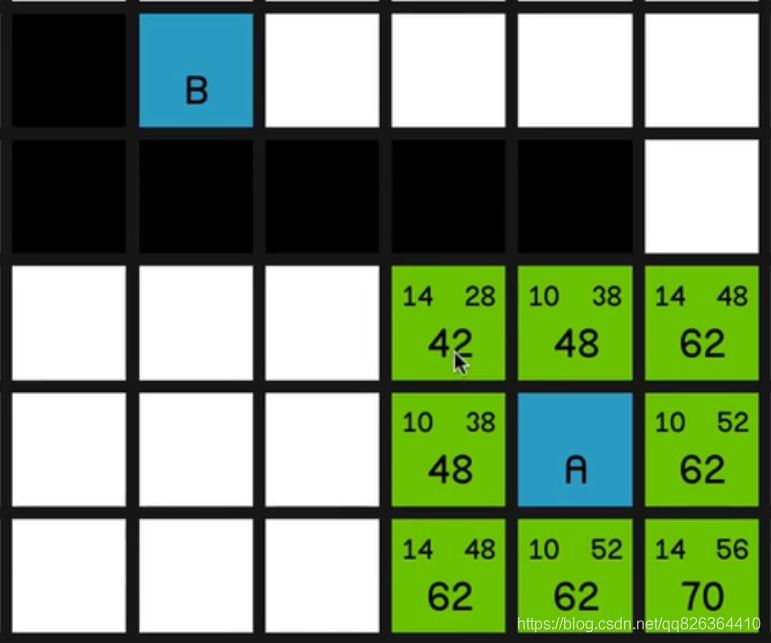
算法的实现思路:
1.将起点放入OpenList中
2.利用While(OpenList.Count)循环, 只要OpenList.Count大于0, 就一直循环执行3, 4, 5步骤。
3.寻找开启列表中的F最小的节点MinFNode,如果F相同,选取H最小的。同时把MinFNode从OpenList移除,放入ClosedList中
4.遍历MinFNode周围的节点,忽略障碍节点和已在ClosedList中的节点,这里会有3种情况
- 相邻点不在OpenList中的,计算H值和G值(MinFNode的G值加上移动所产生的G值),并且把该相邻点的父节点设置为MinFNode (后期找到终点后,需要用父节点进行路径回溯,画出路线。),加入到开启列表OpenList中。
- 相邻点已在OpenList中的,则判断从MinFNode节点的G值加上到相邻点移动所产生的G值之和,是否小于该相邻点的G值,假设小于了,则更新该相邻点的G值为较小的那个,然后重新设置该相邻点的父节点为MinFNode
- 假设遍历到的节点是终点,则按MinFNode的父节点进行回溯,获取到起点的路径,找到最终路径
5.如果没有找到终点,回到第3步,继续执行
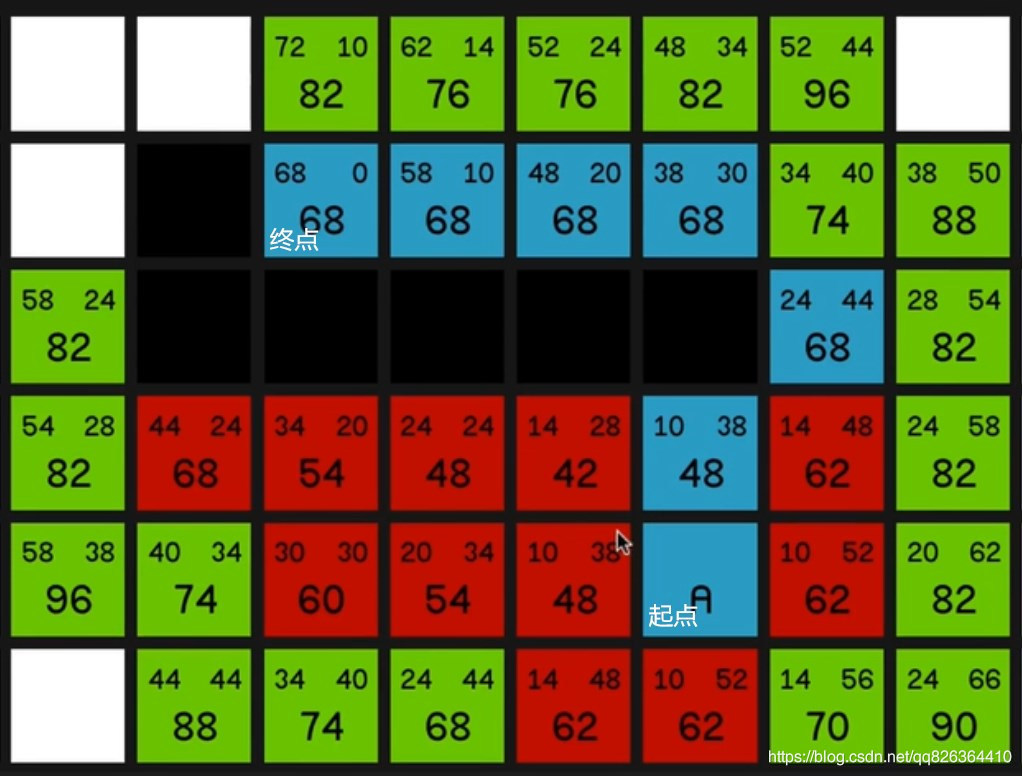
D*算法(Dynamic A Star)
符号及函数说明
Openlist是一个可以用来做广度优先搜索的队列
特点:后向搜索,或者说是反向计算。按照论文中的结果,比replan的效率高不少,在动态环境中表现优秀。这是因为它提前把地图信息都计算并存储的缘故。
节点state的标识tag分为三类:没有加入过open表的(new)、在open表的(open)、曾经在open表但现在已经被移走的(closed)。
每个节点到终点G的代价为h,两个节点(state)之间的开销为C(X,Y),X到终点的代价h为上一个节点(父节点)Y到终点的代价+X和Y之间的开销
每个节点的最小h值为k,代表了该点在全图环境中到G点的最小代价,在计算和更新过程中,对于标识为new的点,k=h,对于标识为open的点,k=min{ k,newh},对于closed的点,k=min{h,newh}。
算法最主要的是两个函数,Process-State 和 Modify-Cost,前者用于计算到目标G的最优路径,后者用于改变两个节点(state)之间的开销C(X,Y) 并将受影响的节点(state)置于Openlist中。
首次搜索
将终点置于Openlist中,采用Dijkstra进行搜索,直到搜索到了起点,结束。搜索结束后,每个搜索过的节点标识为closed,每个节点的k=h,其父节点为邻域中k值最小的那个。
当搜索结束后,可以通过从起点开始找父节点,一路搜索到终点。若搜索结束时Openlist不为空,则里头的节点h的值必然不必起点的h值小。
碰到障碍
若当前点的下一个点(父节点)为障碍,修改其h值并将其放入Openlist中(如果是墙的话就修改为墙的h值,比如无穷大),但其k值仍旧不变,即k=k=min{ k,newh},所以该点会被优先取出并且扩散展开。
扩散过程需要利用到论文中的伪代码 process-state,直到k_min>= state_h 。也就是如果扩散到某个节点的时候,计算后的h值不必其上次的k值小,该点就可以结束对外扩散了。
伪代码及注释
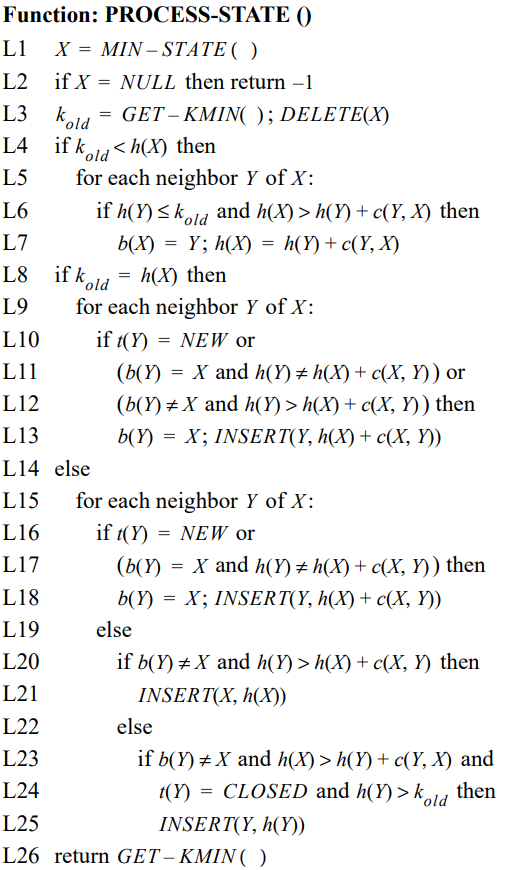
Process-State(): 用于计算到目标G的最优路径。
从open表中获取k值最小的节点,并移除该点。
对该点进行分类处理,遍历其邻域,看是否需要修改父节点、h值及添加到open表中,分类大体如下:
首先进行一次k_old<h(x)判断,看x的h值是否需要调整:
k_old<h(x): 说明该节点受到障碍的影响,x处于raise状态,可以设想x突变为墙时h值上升,或者其父节点受到突变为墙的节点影响,导致h值升高,最后影响到了他。
然后遍历其邻域,如果y点的h值没有上升,并且x的h值能通过该点变得更小。
上述情况,那就修改x的父节点为y,重置其h的值。
然后再重新判断,看y的h值是否需要调整:
k_old=h(x): 处于第一遍遍历的阶段,或者该节点x并没有受到障碍影响。
然后遍历其邻域,if后面的判断代表:y第一次被遍历到;或者y的父节点是X,但是h(y)和h(x)+c(x,y)值却不等, 由于k_old=h(x),这说明h(y)被更改了,但是h(x)还没有变;又或者y的父节点不是X,但是如果让X成为其父节点将拥有更小的h(y)值。
上述三种情况都应该根据x的h值调整y的h值,并将x作为y的父节点,并将y添加到open表中
k_old!=h(x): 说明该节点受到影响,遍历其邻域。
如果y为第一次遍历到的点;或者x是y的父节点,但是h(y)和h(x)+c(x,y)值却不等, 这说明h(x)被更改了,但是h(y)还没有变;
上述情况应该应该根据x的h值调整y的h值,并将x作为y的父节点,并将y添加到open表中。
如果y的父节点不是X,但是让X成为其父节点将拥有更小的h(y)值。
上述情况应该应该调整x的h值,并将x添加到open表中。
如果y的父节点不是X,但是让Y成为X父节点,X将拥有更小的h(x)值,并且y被已经被open表移除,且h(y)值在上升(即y受到影响)。
上述情况应该应该调整y的h值,并将y添加到open表中。
2、你项目中遇到的最大的问题是什么?你是怎么解决的?#
预约挂号也是一种方便患者提前安排就医计划,减小候诊时间,便于医院提升管理水平,提高工作效率和医疗质量,降低医疗安全风险的门诊挂号方式。但是预约患者不可能做到100%应诊,目前国内报道的爽约率10%以上,甚至达50%,国外报道的爽约率为3&~34%。患者会因为各种主客观原因而爽约,造成医疗资源的极大浪费。因此研究这些浪费医疗资源的人特征,对医疗资源的合理分配有重要的意义。
那么,关于后台需要建立对用户的数据清洗、数据分析、用户画像分层。
如:中老年患者如约就诊的人数最多,65岁以后的老年患者如约就诊的可能性最高,青少年患者如约就诊的可能性较低。我们可以通过数据的分析避免医疗资源的浪费。
还有一种情况,也需要我们注意的是通过此次疫情,预约挂号网的并发量突然猛增。
涉及抢号时,为了避免超卖,那么号源数量是有限的,但是如果同时下单人数超过了库存数量,就会导致号源超卖问题。那么我们怎么来解决这个问题呢,思路如下:
这里可使用消息队列,我们常用到Memcacheq、Radis。比如:一个好的医生一天接诊量有100号源可供用户购买,那么就可以把这100个号源放到缓存中,读写时不要加锁。当并发量大的时候,可能有300人在抢这100个号源,这样对于300后面的请求可以直接转到号源购买结束的静态页面。进去的300个人中有200个人是不可能获得号源的。所以可以根据进入队列的先后顺序只能前100个人购买成功。后面400个人就直接转到号源为空页面。
而号源为空页面一定要用静态页面,不要用数据库。这样就减轻了数据库的压力。
还有一种解决方案,就是mysql悲观锁,意思是比如总库存是2,购买事件提交时,立马将库存+1,那么此时库存是3,然后订单生成后,在更新库存前再查询一次库存(因为订单生成理所当然库存-1,但是先不急,再查一次库存返回结果是3),看看跟预期的库存数量(这里预期的库存是3)是否保持一致,不一致就回滚,提示用户库存不足。
悲观锁与乐观锁是两种常见的资源并发锁设计思路,也是并发编程中一个非常基础的概念。但可以非常巧妙的解决号源购买并发的问题。
在面试中如何展示虚拟机和内存调优技能https://zhuanlan.zhihu.com/p/443254268
排查了redis慢查询的问题
在对挂号系统的预约挂号功能进行jmeter测试时,页面卡在预约挂号这一部分,没有进行后续操作。(在不同的事务中,如果出现相反的顺序更新两条不同的表记录。那么当这两个事务同时发生时,可能出现死锁。因此在写代码时务必要注意,严格按照相同顺序更新不同的表记录。)
- 报警系统"Deadlock found when trying to get lock...”
- 查询mysql死锁日志,命令:SHOW ENGINE INNODB STATUS。
- 分析死锁日志,定位到具体代码,发现是两个事务对排班表进行update操作,
对于查询一,第一个更新依次扫描表中所有记录,对于每条记录,加 U 锁,判断是否符合更新条件,如果符合,转换为 X 锁;如果不符合条件,释放 U 锁。第一个更新完成的时候,查询一锁定了一条记录(由于事务未完成,所以锁一直保持),然后等待第二个更新
对于查询二,依次扫描表中的每条记录(与前面的更新一样),如果它更新的记录在查询一更新的记录前被扫描到,那么这条记录也会变成 X 锁;当继续并进行到查询一的X锁记录的零点,U 与 X 冲突,无法继续,这时候查询二等待查询一释放锁
查询一的第二个更新开始执行,依次扫描每条记录,同一个事务内不会有冲突,所以它不会与自己之前锁定的记录有冲突,但进行到查询二锁定的记录的时候,它也无法获得 U 锁,它需要等待查询二释放资源。这个时候就形成了相互等待,符合死锁条件
如果查询二需要更新的记录在查询一的第一个更新记录之后,则不会有死锁,因为查询二在扫描到查询一第一个更新的记录时就会因为锁冲突等待了,这个时候它没有对任何记录设置与查询一的操作有冲突的锁。我自己测试的时候没有死锁,就是这种情况。
注意这里面提到的顺序,是数据读取的顺序,不一定与存储顺序一样,磁盘上记录的顺序也不一定与INSERT的记录顺序一样,这也是我用同样条件没有测试出死锁的原因(我的环境中,恰好读出的顺序与INSERT的顺序不一样)
- 解决方法 在查询的筛选字段处使用非聚集索引,即在排班表的日期。
3、你项目中用到的技术栈是如何学习的?#
4、为什么做这个项目,技术选型为什么是这样的?#
5、登录怎么做的?单点登录说说你的理解?#
几种登录方式#
早期的cookie-session认证方式
- 用户输入用户名、密码或者用短信验证码方式登录系统;
- 服务端验证后,创建一个 Session 信息,并且将 SessionID 存到 cookie,发送回浏览器;
- 下次客户端再发起请求,自动带上 cookie 信息,服务端通过 cookie 获取 Session 信息进行校验;
存在的问题
1、首先,Cookie-Session 只能在 web 场景下使用,如果是 APP 呢,APP 可没有地方存 cookie。
现在的产品基本上都同时提供 web 端和 APP 两种使用方式,有点产品甚至只有 APP。2、退一万步说,你做的产品只支持 web,也要考虑跨域问题, 但Cookie 是不能跨域的。
拿天猫商城来说,当你进入天猫商城后,会看到顶部有天猫超市、天猫国际、天猫会员这些菜单。而点击这些菜单都会进入不同的域名,不同的域名下的 cookie 都是不一样的,你在 A 域名下是没办法拿到 B 域名的 cookie 的,即使是子域也不行。3、如果是分布式服务,需要考虑 Session 同步问题。
JWT: 生成并发给客户端之后,后台是不用存储,客户端访问时会验证其签名、过期时间等再取出里面的信息(如username),再使用该信息直接查询用户信息完成登录验证。jwt自带签名、过期等校验,后台不用存储,缺陷是一旦下发,服务后台无法拒绝携带该jwt的请求(如踢除用户);
JWT只能防篡改,不能防冒充
一旦颁发一个 JWT 令牌,服务端就没办法废弃掉它,除非等到它自身过期。有很多应用默认只允许最新登录的一个客户端正常使用,不允许多端登录,JWT 就没办法做到,因为颁发了新令牌,但是老的令牌在过期前仍然可用。这种情况下,就需要服务端增加相应的逻辑。
token+redis: 是自己生成个32位的key,value为用户信息,访问时判断redis里是否有该token,如果有,则加载该用户信息完成登录。服务需要存储下发的每个token及对应的value,维持其过期时间,好处是随时可以删除某个token,阻断该token继续使用

具体登录操作#
登录的几个需求
1,登录采取弹出层的形式
2,登录方式:
(1)手机号码+手机验证码
(2)微信扫描
3,无注册界面,第一次登录根据手机号判断系统是否存在,如果不存在则自动注册
4,微信扫描登录成功必须绑定手机号码,即:第一次扫描成功后绑定手机号,以后登录扫描直接登录成功
5,网关统一判断登录状态,如何需要登录,页面弹出登录层
基于Redis + token的登录过程
- 用户输入用户名、密码或者用短信验证码方式登录系统;
- 服务端经过验证,将认证信息构造好的数据结构存储到 Redis 中,并将 key 值返回给客户端;
- 客户端拿到返回的 key,存储到 local storage 或本地数据库;
- 下次客户端再次请求,把 key 值附加到 header 或者 请求体中;
- 服务端根据获取的 key,到 Redis 中获取认证信息;
基于JWT的登录过程

1、在用户登录网站的时候,需要输入用户名、密码或者短信验证的方式登录,登录请求到达服务端的时候,服务端对账号、密码进行验证,然后计算出 JWT 字符串,返回给客户端。
2、客户端拿到这个 JWT 字符串后,存储到 cookie 或者 浏览器的 LocalStorage 中。
3、再次发送请求,比如请求用户设置页面的时候,在 HTTP 请求头中加入 JWT 字符串,或者直接放到请求主体中。
4、服务端拿到这串 JWT 字符串后,使用 base64的头部和 base64 的载荷部分,通过HMACSHA256算法计算签名部分,比较计算结果和传来的签名部分是否一致,如果一致,说明此次请求没有问题,如果不一致,说明请求过期或者是非法请求。
权限管理
所有请求经过服务网关,服务网关对外暴露接口,网关进行统一用户认证。
Api接口异步请求的,我们采取url规则匹配,如:/api/**/auth/**,如凡是满足该规则的都必须用户认证
6、项目遇到的最大挑战是什么?(类似问题2)#
7、说说项目中的闪光点和亮点?#
8、项目怎么没有尝试部署上线呢?#
9、介绍项目具体做了什么?(项目背景)#
10、如果让你对这个项目优化,你会从哪几个点来优化呢?#
以上10个问题是针对所有项目可能会提问的问题,至于楼主所说的这个尚医通的项目,可以参考下面几个问题。
1、登录是如何做的?
1,登录采取弹出层的形式
2,登录方式:
(1)邮箱+邮箱验证码
(2)微信扫描
3,无注册界面,第一次登录根据手机号判断系统是否存在,如果不存在则自动注册
4,微信扫描登录成功必须绑定手机号码,即:第一次扫描成功后绑定手机号,以后登录扫描直接登录成功
5,网关统一判断登录状态,如何需要登录,页面弹出登录层(api接口异步请求的,采取url规则匹配)
11、Redis在这个项目中的作用有什么?#
1)使用Redis作为缓存
2)验证码有效时间、支付二维码有效时间
AOF#
AOF(*Append Only File*) 持久化功能,注意只会记录写操作命令,读操作命令是不会被记录。Redis 是先执行写操作命令后,才将该命令记录到 AOF 日志里
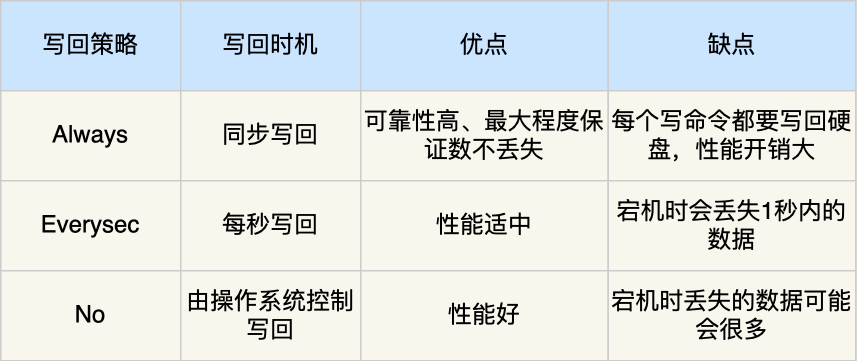
Redis 为了避免 AOF 文件越写越大,提供了 AOF 重写机制,当 AOF 文件的大小超过所设定的阈值后,Redis 就会启用 AOF 重写机制,来压缩 AOF 文件。重写机制的妙处在于,尽管某个键值对被多条写命令反复修改,最终也只需要根据这个「键值对」当前的最新状态,然后用一条命令去记录键值对,代替之前记录这个键值对的多条命令,这样就减少了 AOF 文件中的命令数量。最后在重写工作完成后,将新的 AOF 文件覆盖现有的 AOF 文件。
RDB#
- RDB 文件的内容是二进制数据。
Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave,他们的区别就在于是否在「主线程」里执行:
- 执行了 save 命令,就会在主线程生成 RDB 文件,由于和执行操作命令在同一个线程,所以如果写入 RDB 文件的时间太长,会阻塞主线程;
- 执行了 bgsave 命令,会创建一个子进程来生成 RDB 文件,这样可以避免主线程的阻塞;
RDB 文件的加载工作是在服务器启动时自动执行的,Redis 并没有提供专门用于加载 RDB 文件的命令。
Redis 还可以通过配置文件的选项来实现每隔一段时间自动执行一次 bgsave 命令,默认会提供以下配置:
save 900 1
save 300 10
save 60 10000
// 900 秒之内,对数据库进行了至少 1 次修改;
// 300 秒之内,对数据库进行了至少 10 次修改;
// 60 秒之内,对数据库进行了至少 10000 次修改。
如果主线程(父进程)要修改共享数据里的某一块数据(比如键值对 A)时,就会发生写时复制,于是这块数据的物理内存就会被复制一份(键值对 A'),然后主线程在这个数据副本(键值对 A')进行修改操作。与此同时,bgsave 子进程可以继续把原来的数据(键值对 A)写入到 RDB 文件。
RDB 和 AOF 合体#
尽管 RDB 比 AOF 的数据恢复速度快,但是快照的频率不好把握:
- 如果频率太低,两次快照间一旦服务器发生宕机,就可能会比较多的数据丢失;
- 如果频率太高,频繁写入磁盘和创建子进程会带来额外的性能开销。
那有没有什么方法不仅有 RDB 恢复速度快的优点和,又有 AOF 丢失数据少的优点呢?
当然有,那就是将 RDB 和 AOF 合体使用,这个方法是在 Redis 4.0 提出的,该方法叫混合使用 AOF 日志和内存快照,也叫混合持久化。
如果想要开启混合持久化功能,可以在 Redis 配置文件将下面这个配置项设置成 yes:
aof-use-rdb-preamble yes
混合持久化工作在 AOF 日志重写过程。
当开启了混合持久化时,在 AOF 重写日志时,fork 出来的重写子进程会先将与主线程共享的内存数据以 RDB 方式写入到 AOF 文件,然后主线程处理的操作命令会被记录在重写缓冲区里,重写缓冲区里的增量命令会以 AOF 方式写入到 AOF 文件,写入完成后通知主进程将新的含有 RDB 格式和 AOF 格式的 AOF 文件替换旧的的 AOF 文件。
也就是说,使用了混合持久化,AOF 文件的前半部分是 RDB 格式的全量数据,后半部分是 AOF 格式的增量数据。这样的好处在于,重启 Redis 加载数据的时候,由于前半部分是 RDB 内容,这样加载的时候速度会很快。
加载完 RDB 的内容后,才会加载后半部分的 AOF 内容,这里的内容是 Redis 后台子进程重写 AOF 期间,主线程处理的操作命令,可以使得数据更少的丢失。
12、消息队列在这个项目中的作用?#
订单相关操作时,用mq发送短信消息给短信消费者
如果商品服务和订单服务是两个不同的微服务,在下单的过程中订单服务需要调用商品服务进行扣库存操作。按照传统的方式,下单过程要等到调用完毕之后才能返回下单成功,如果网络产生波动等原因使得商品服务扣库存延迟或者失败,会带来较差的用户体验,
应用场景
异步处理。把消息放入消息中间件中,等到需要的时候再去处理。
流量削峰。例如秒杀活动,在短时间内访问量急剧增加,使用消息队列,当消息队列满了就拒绝响应,跳转到错误页面,这样就可以使得系统不会因为超负载而崩溃。使用监听器绑定
sendEmail()函数,当系统需要发出短信时,通过rabbitMq中间件发送。
13、MongoDB与Reids的区别是什么?你的项目中MongoDB的作用?#
内存管理机制不同
Redis 数据全部存在内存,定期写入磁盘,当内存不够时,可以选择指定的 LRU 算法删除数据。MongoDB 数据存在内存,由 linux系统 mmap 实现,当内存不够时,只将热点数据放入内存,其他数据存在磁盘。
支持的数据结构不同
Redis 支持的数据结构丰富,包括string,hash,list,set及zset(sorted set)等。
MongoDB 数据结构比较单一,但是支持丰富的数据表达,索引,最类似关系型数据库,支持的查询语言非常丰富。
使用MongoDb存储一些非关系型的数据,提高访问速度
在1.8版本之后开始支持journal,就是我们常说的redo log,用于故障恢复和持久化
在2.0之后的版本,journal都是默认打开的,以确保数据安全
图解:
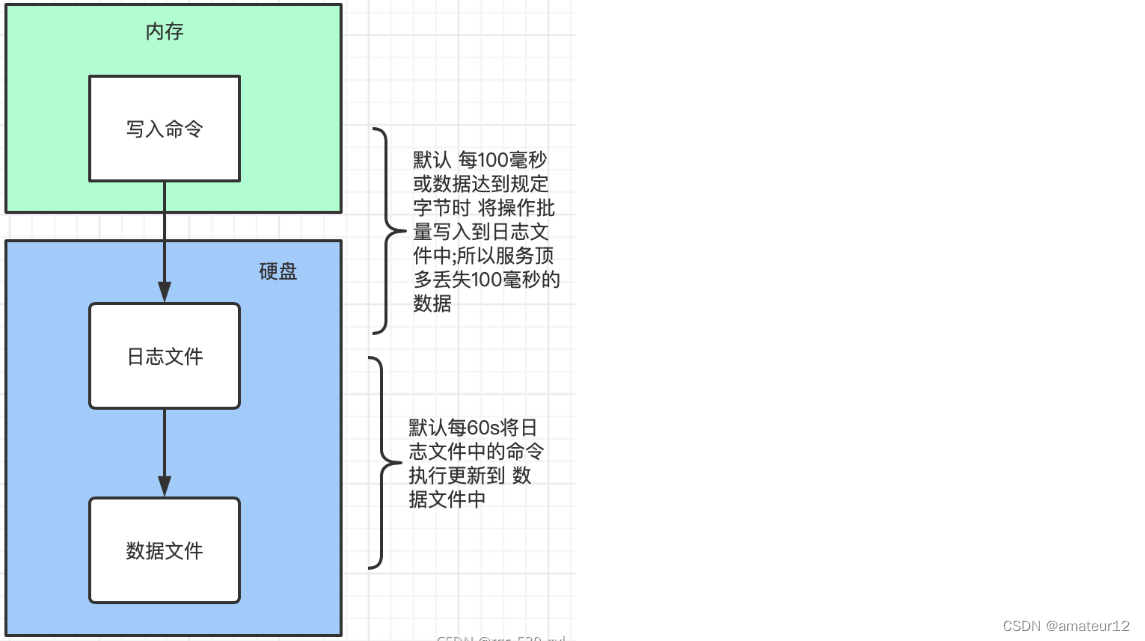
写入操作会记录journal日志,记录写入操作具体更改的磁盘地址和字节(如果服务器突然崩溃,启动时,journal会重放崩溃前并没有刷新到磁盘上的写操作)
数据文件每隔60s刷新到磁盘上,journal只需要持有60s内的写入数据。journal预分配了几个空文件用于此目的,位于/data/db/journal,命名为_j.0,_j.1等。
14、项目中存在多线程问题吗?如果多个用户同时抢号怎么处理?#
库存表结构如下
| 字段名 | 英文名 | 字段类型 |
|---|---|---|
| 商品标识 | skuId | 长整型 |
| 库存数量 | num | 整数 |
综合使用数据库和Redis满足高并发扣减的原理#
扣减库存其实包含两个过程:第一步是超卖校验,第二步是扣减数据的持久化;在传统数据库扣减中,两步是一起完成的。抗写的实现原理其实是巧妙的利用了分离的思想,分离开防超卖和数据持久化;首先防超卖是由Redis来完成的;通过Redis防超卖后,只要落库就可以;落库通过任务引擎,业务数据库使用商品分库分表,任务引擎任务通过单据号分库分表,热点商品的落库会被状态机分散开,消除热点。整体架构如下:
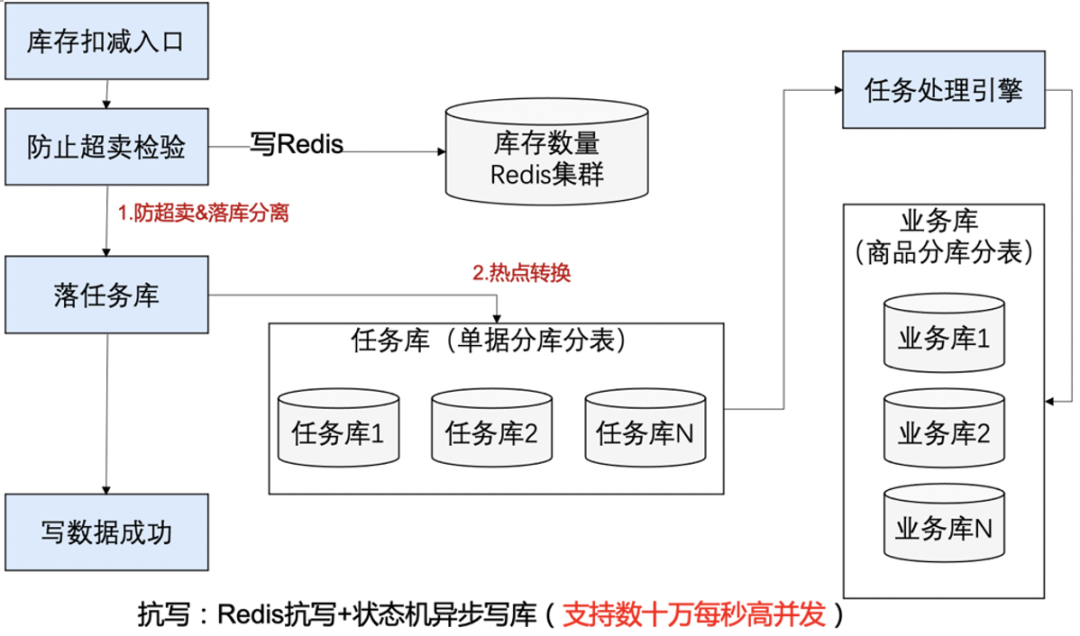
第一关解决超卖检验:可以把数据放入Redis中,每次扣减库存,都对Redis中的数据进行incryby 扣减,如果返回的数量大于0,说明库存够,因为Redis是单线程,可以信任返回结果。第一关是Redis,可以抗高并发,性能Ok。超卖校验通过后,进入第二关。
第二关解决库存扣减:经过第一关后,第二关不需要再判断数量是否足够,只需要傻瓜扣减库存就行,对数据库执行如下语句,当然还是需要处理防重幂等的,不需要判断数量是否大于0了,扣减SQL只要如下写就可以。
--事务开始
Insert into antiRe(code) value (‘订单号+Sku’)
Update stockNum set num=num-下单数量 where skuId=商品ID
--事务结束
要点:最终还是要使用数据库,热点怎么解决的呢?任务库使用订单号进行分库分表,这样针对同一个商品的不同订单会散列在任务库的不同库存,虽然还是数据库抗量,但已经消除了数据库热点。
第一步超卖校验Redis内存扣减,第二步扣减数据的持久化,中间断了怎么办?(例:服务重启)
答:如果是服务重启,会在服务器重启之前停止这台服务器的服务;但此方案并不能保证数据的绝对一致,比如扣减redis后,应用服务器故障直接死机,这种情况下的处理就需要更复杂的方案才能保证实时一致(目前没有采取更复杂方案),可以通过另一个方案使用库存数据和用户的订单数据进行数据比对修复,达到最终一致性。
15、对于号的超抢问题如何解决(类似秒杀的超买超卖问题)#
每一个用户只能抢购一件商品的限制,在数据库减库存时加上数据库数量判断,库存为0时阻止秒杀订单生成
数据库增加唯一索引,防止用户重复购买,SQL加库存数量判断:防止库存变负数。
悲观锁
select时,使用行锁,
select math from zje where math>60 lock in share mode;(共享锁)select math from zje where math >60 for update;(排它锁)乐观锁
是在更新的时候判断此时的库存是否是之前查询出的库存,如果相同,表示没人修改,可以更新库存,否则表示别人抢过资源,不再执行库存更新。
分段执行的排队方案
使用CLH队列、AQS内部队列
- 第一阶段申请,申请预减减库,申请成功之后,进入消息队列;
- 第二阶段确认,从消息队列消费申请令牌,然后完成下单操作。 查库存 -> 创建订单 -> 扣减库存。通过分布式锁保障解决多个provider实例并发下单产生的超卖问题。
申请阶段:将库存从MySQL移入Redis,由于Redis不存在锁,不会出现互相等待。
确认阶段:通过队列等一部手段,将变化的数据异步写入DB中
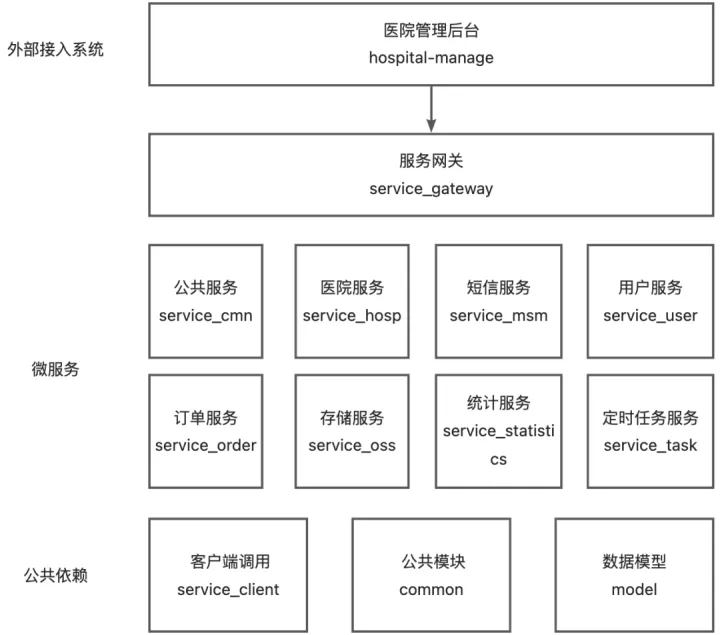
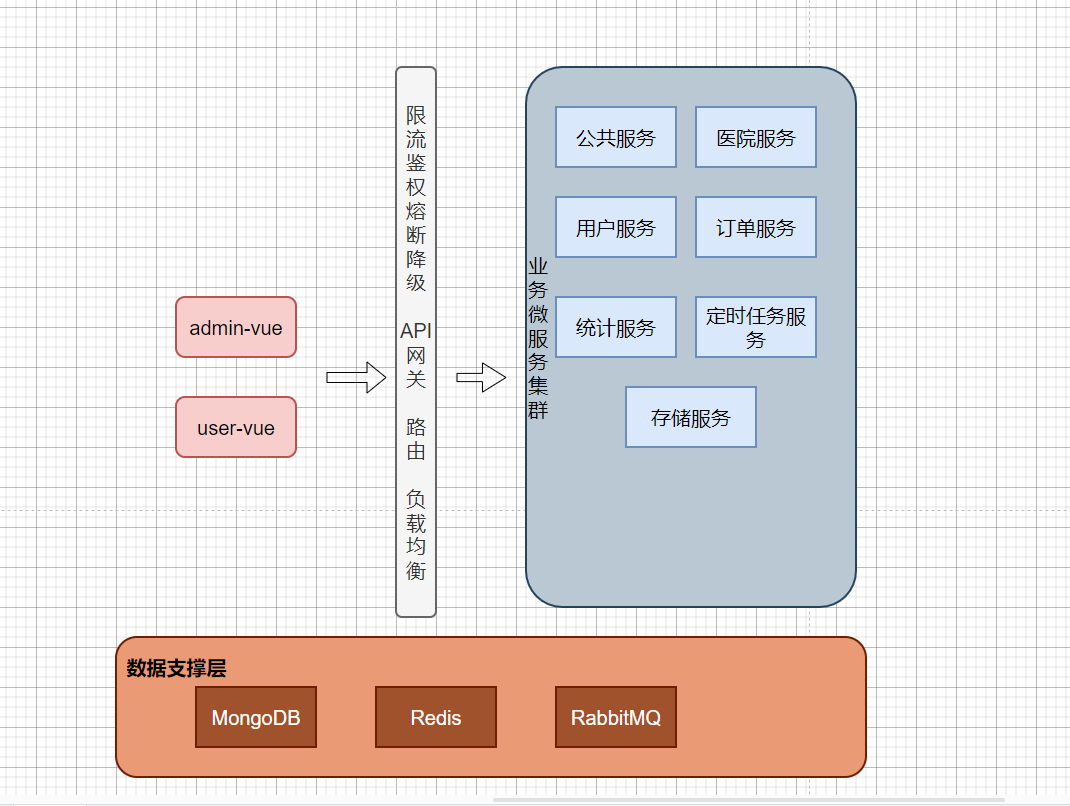
16、微服务是如何划分的?有哪些微服务模块?#
17、SpringCloud Nacos有具体了解过吗(比如源码等)#
Nacos是阿里开源的一个项目,可以作为服务注册中心、配置中心
每个服务实例启动之后,都主动向注册中心登记自己的地址信息,这样注册中心便拥有了所有服务实例的记录,类似于查号台。
当某个服务实例停止运行的时候,主动让注册中心销毁自己的信息。如果服务实例不是主动停止,而是因为故障等原因死掉的,如何处理?需要注册中心能够主动清理。注册中心要能够实时知道各个服务实例的状态,通过心跳机制来实现,实例定时向注册中心发送请求,表明自己还活着,如果心跳没了,注册中心就可以对其清理。
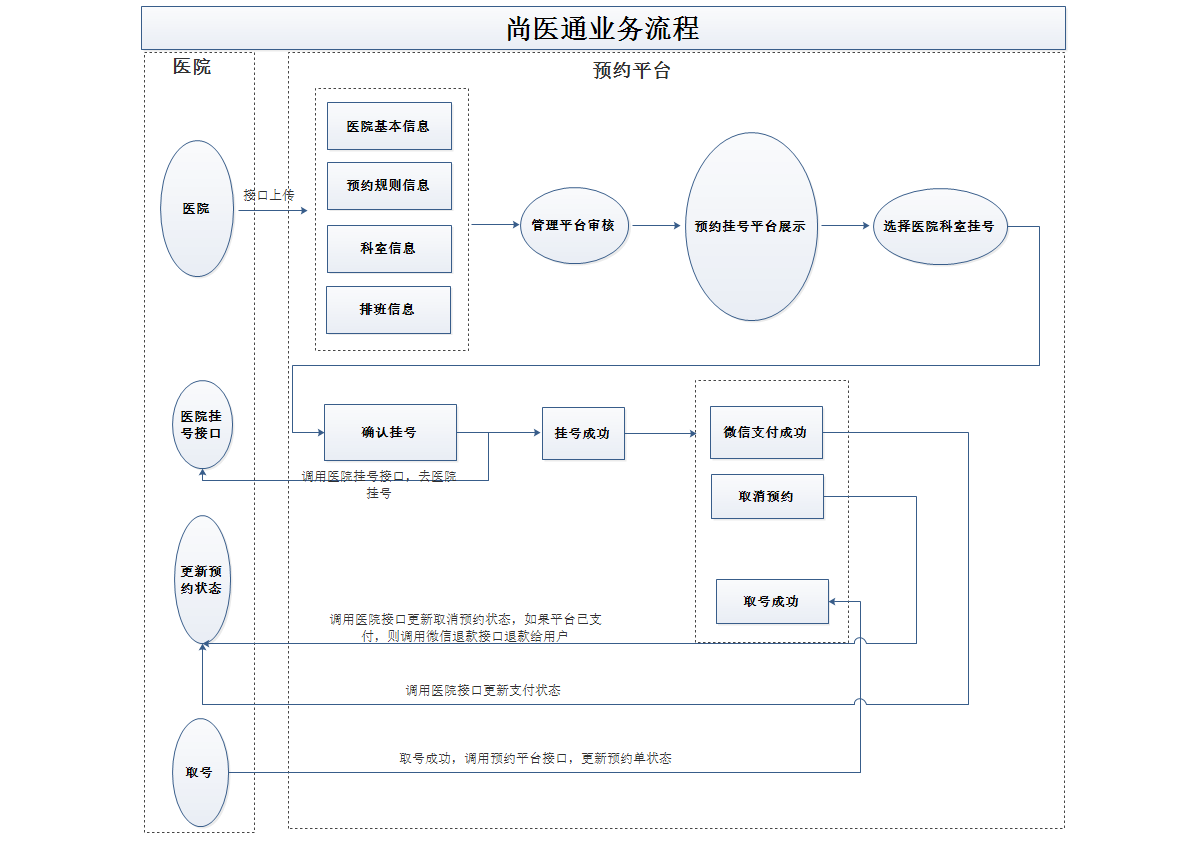
18、 项目的业务流程#
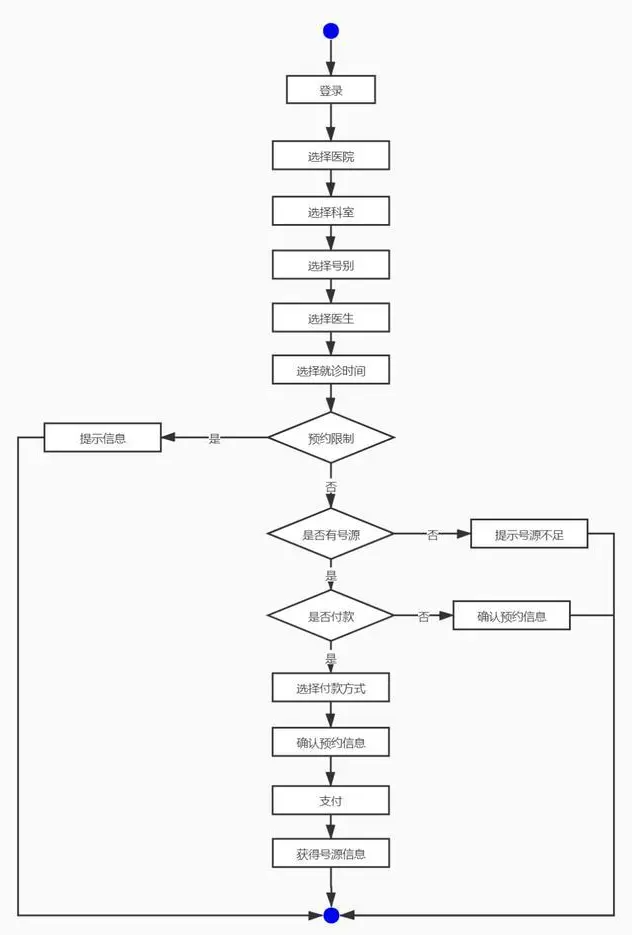
19、 项目的分层架构#
20、订单提交后,如何判断是否有死锁(数据库死锁),怎么解决#
(1)数据库死锁#
在数据库中,如果一个连接占用了另一个连接所需的数据库锁,则它可以阻塞另一个连接。如果两个或两个以上的连接相互阻塞,则它们都不能继续执行,这种情况称为数据库死锁。
值得庆幸的是,数据库死锁通常是可恢复的:当数据库发现死锁时,它会强制销毁一个连接(通常是使用最少的连接),并回滚其事务。这将释放所有与已经结束的事务相关联的锁,至少允许其他连接中有一个可以获取它们正在被阻塞的锁。
如何尽可能避免数据库死锁
- 以固定的顺序访问表和行。比如对第2节两个job批量更新的情形,简单方法是对id列表先排序,后执行,这样就避免了交叉等待锁的情形;又比如对于3.1节的情形,将两个事务的sql顺序调整为一致,也能避免死锁。
- 大事务拆小。大事务更倾向于死锁,如果业务允许,将大事务拆小。
- 在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁概率。
- 降低隔离级别。如果业务允许,将隔离级别调低也是较好的选择,比如将隔离级别从RR调整为RC,可以避免掉很多因为gap锁造成的死锁。
- 为表添加合理的索引。可以看到如果不走索引将会为表的每一行记录添加上锁,死锁的概率大大增大。
(2)多线程死锁#
- 多线程锁定同一资源会造成死锁
- 线程池中的任务使用当前线程池也可能出现死锁
Jconsole是JDK自带的监控工具,在JDK/bin目录下可以找到。它用于连接正在运行的本地或者远程的JVM,对运行在Java应用程序的资源消耗和性能进行监控,并画出大量的图表,提供强大的可视化界面。而且本身占用的服务器内存很小,甚至可以说几乎不消耗。
我们在命令行中敲入jconsole命令,会自动弹出以下对话框,选择进程1362,并点击“链接”
进入所检测的进程后,选择“线程”选项卡,并点击“检测死锁”
-
统一加锁顺序
使用多线程的时候,一种非常简单的避免死锁的方式就是:统一各个线程获取锁的顺序,并强制线程按照指定的顺序获取锁。因此,如果所有的线程都是以同样的顺序获得锁和释放锁,就不会出现死锁了。这需要编程人员的细心。
-
请求锁时限&失败返回
另外一个可以避免死锁的方法是在尝试获取锁的时候加一个超时时间,这也就意味着在尝试获取锁的过程中若超过了这个时限该线程则放弃对该锁请求。若一个线程没有在给定的时限内成功获得所有需要的锁,则会进行回退并释放所有已经获得的锁,然后等待一段随机的时间再重试。
当然synchronized不具备这个功能,但是我们可以使用jdk1.5提供的Lock锁体系中的tryLock方法去尝试获取锁,这个方法可以指定一个超时时限,在等待超过该时限之后变回返回一个失败信息。
LOCK锁,jdk1.5之后提供的新锁! 比使用 synchronized 方法和语句可获得的更广泛的锁定操作! 此实现允许更灵活的结构,具有尝试获取锁的方法,如下方法:
21、你是怎样使用测试工具判断最终结果符合预期的#
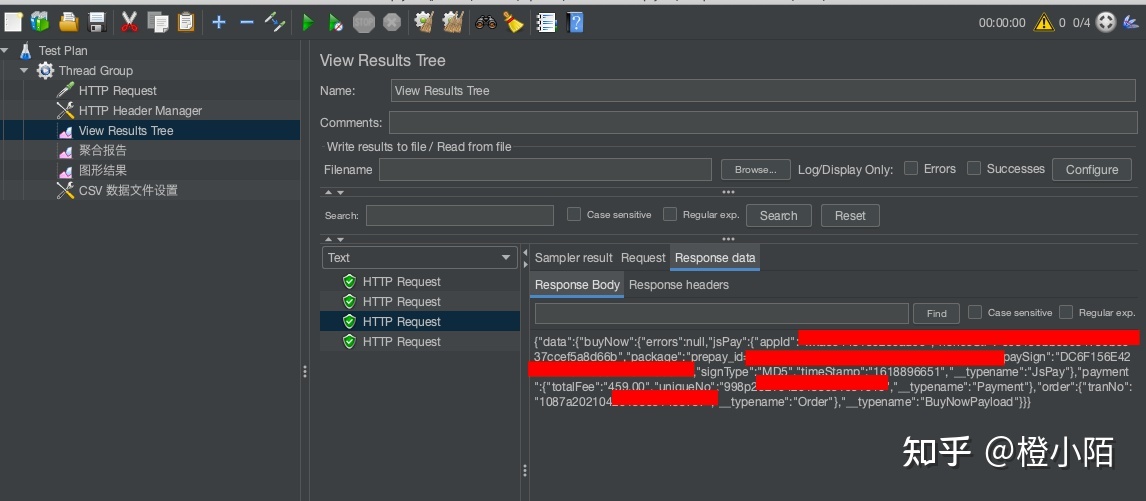
使用 JMeter 进行测试,如果是MacOS 可以通过 Homebrew 安装,创建Http Request 测试。
- 一组 HTTP API 测试通过几个部分组成,HTTP Request、HTTP Header / Cookies、View Results Tree、外部CSV等;
- 可以通过 HTTP Request 创建 API 请求;
- 可以设置 HTTP Header 头,比如 Token,如果有多个 Token ,可以依赖 CSV 外部文件进行导入,CSV 设置变量名 token,在 Header 里面以 ${token} 变量名进行动态加载;如果 Body 请求体为 JSON 格式,记得设置 Header Content-Type application/json
- 可以通过 View Results Tree 查看每条测试结果;
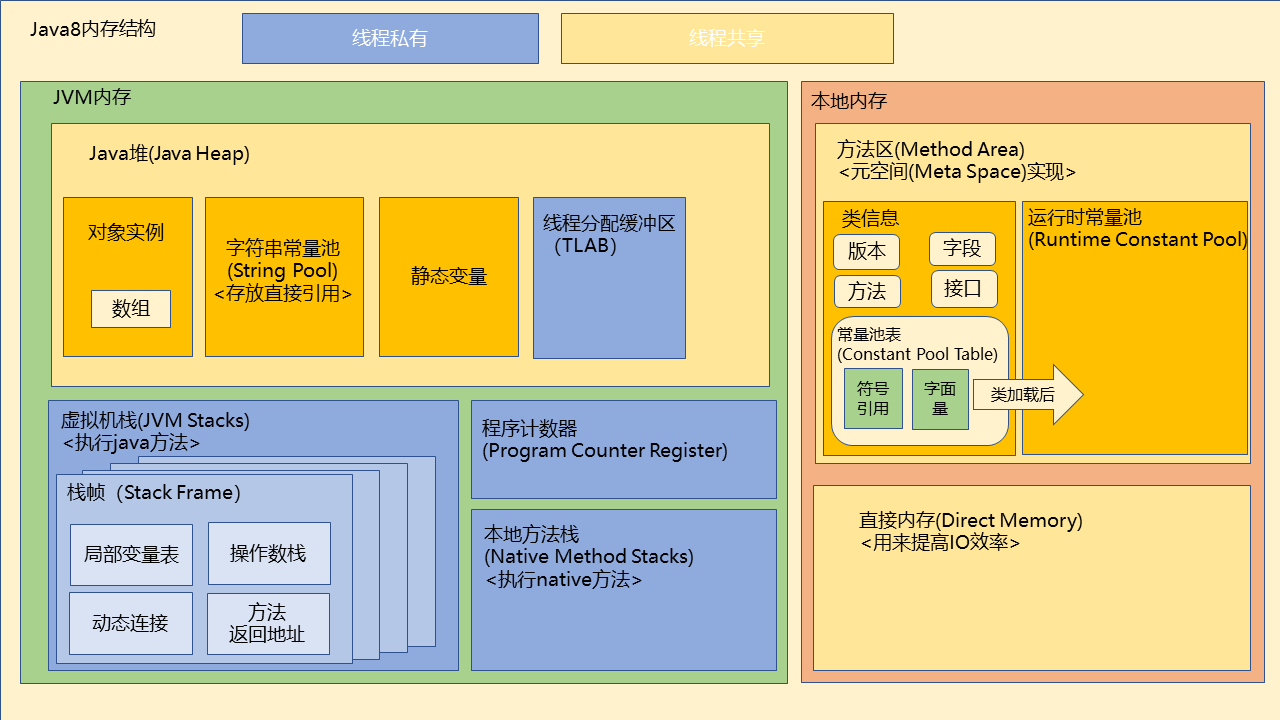
22、Java8内存结构#



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本