在桌面应用程序中预览 PDF 的新解决方案
https://www.brad-smith.info/blog/archives/972
----------------------------------------------------------------------------------------
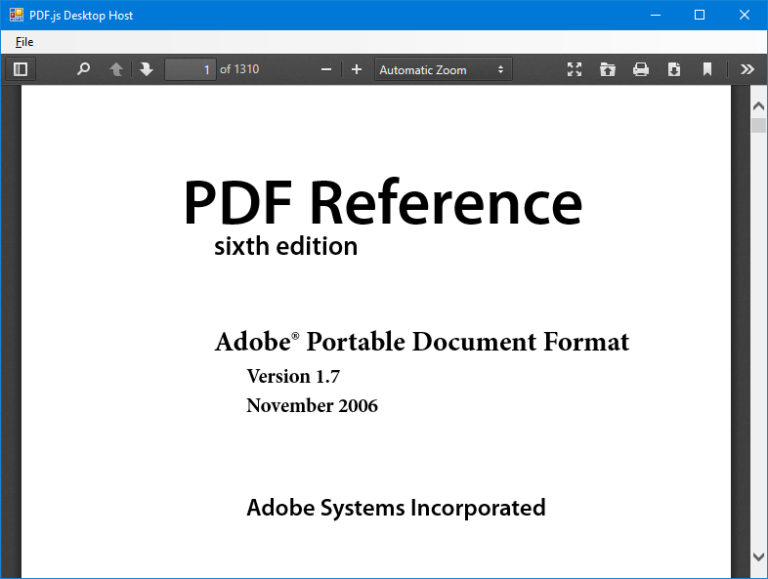
过去,我使用 Windows 预览处理程序作为在我的 Windows 窗体应用程序中预览文档的便捷方式。这样做的主要优点是不必为(可能无限)范围的文件格式编写我自己的预览逻辑,并使用自 Windows Vista 以来已广泛支持的标准操作系统功能。
不幸的是,预览处理程序的一大好处也让我很头疼;并非所有实现都是平等创建的。一些处理程序编写得很好,可以很好地与 .NET 主机配合使用,另一些则存在重大错误和内存泄漏,还有一些根本无法正常工作。最糟糕的罪魁祸首之一是 Adobe 的 PDF Preview Handler,它与 Adobe Reader 和 Acrobat 一起安装。
我现在得出的结论是,至少对于 PDF,预览处理程序不再是可行的解决方案,需要更可靠的替代方案。问题在于,为 PDF 文档生成预览并非易事——这样做需要解析器、PostScript 解释器、用于排版、图像处理、压缩、加密等的库。虽然我一直在尝试所有这些,但我需要一些适合立即生产使用的东西。
输入,PDF.js…
PDF.js是由 Mozilla Labs 开发的 JavaScript 库,可用于在 Web 浏览器中查看 PDF。它是 Firefox 中内置 PDF 查看器的基础,但也适用于其他浏览器。与其他机制不同,它不需要安装操作系统或第三方 PDF 应用程序,完全独立。它也很小(大约 4MB)并且性能很好。
如果我正在开发一个 Web 应用程序,我肯定会利用 PDF.js 来预览文档——这是显而易见的选择,真的。然而,我主要在桌面世界工作,我需要一种在 Windows 窗体环境中利用这个优秀库的方法。
浏览器问题
内置WebBrowser控件是在桌面应用程序中利用 HTML/JavaScript 内容的便捷方式。除了能够在表单上的其他控件旁边显示内容外,DOM 和托管应用程序之间也可能存在一些有限的交互性。所以从表面上看,这似乎是利用 PDF.js 的好方法……
问题:
- 出于兼容性原因,浏览器在 Internet Explorer 7 仿真模式下运行,该模式缺乏适当的、符合标准的 HTML、CSS 和 JavaScript 支持。
- 除非通过 HTTP 加载,否则 PDF.js 查看器无法正常工作——文件 URL 是不够的。
- PDF.js(在大多数情况下)只能呈现从与其自身相同的来源(域)加载的文档。
使用本地 HTTP 服务器解决这些问题
PDF.js 已经在很大程度上解决了第一个问题;可以通过在 HTML 页面的部分中包含X-UA-Compatible元标记来覆盖 Web 浏览器控件的兼容性设置。<head>这会将浏览器提升到 Internet Explorer 11 模式。为 ECMAScript 版本 5 浏览器(包括 IE11)构建的 PDF.js 版本可用,可以在该浏览器中使用查看器。
其他两个问题需要更彻底的解决方案;由于脚本需要通过 HTTP 加载,我们需要使用本地 HTTP 服务器来提供它。理想情况下,这应该是轻量级的,不需要额外的设置或提升权限即可运行。由于同源要求,我们还需要一种方法来确保加载到查看器中的文档可以通过同一服务器访问。
为了满足这些要求,我选择了NHttp——一个简单的嵌入式 HTTP 服务器,没有其他依赖项。与基于 Windows 的 .NET Framework 的内置 HTTP 服务器不同http.sys,NHttp 不需要 URL 保留,因此不需要管理员权限即可运行。它也快速旋转,非常适合我们的需求。
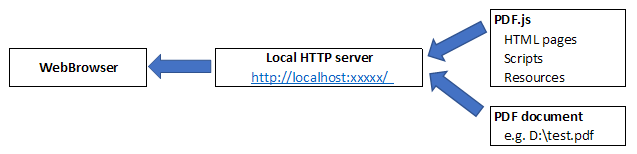
服务器只是充当 PDF.js 脚本、要预览的文档和 Web 浏览器之间的代理。它将它们放在 HTTP URL 后面,并确保它们是从同一来源访问的(即使它们的真实位置不同)。总之,这解决了上述所有问题。
这个怎么运作
从开始到结束,在WebBrowser控件中预览 PDF 的过程如下:
- 初始化组件时,PDF.js 文件被提取到一个临时目录。通过将这些作为嵌入式资源存储在程序集中,该项目的占用空间更小。
- HTTP 服务器开始侦听本地 IP 地址,使用随机端口号,以免干扰可能需要端口 80 的任何其他服务。
- 应用程序向服务器注册一个本地文件名(可能在另一个驱动器或网络共享上),以换取将用于显示预览的唯一 URL。(理论上,这也可能是内存中的流,甚至是位于另一个 URL 的文档)该 URL 指向 PDF.js 查看器,预加载了正确的文档。
- 应用程序将控件导航
WebBrowser到上一步中获得的 URL。 - 服务器接收多个请求。根据路径:
- 如果路径以“/doc”开头,则将步骤 3 中注册的本地文件名提供给浏览器。
- 如果路径对应于 PDF.js 源文件之一,则该文件将提供给浏览器。
- 加载查看器,然后 PDF.js 加载文档并将其
WebBrowser显示给用户。 - 当应用程序不再需要显示预览时,可以停止 HTTP 服务器。此时,也可以清理临时目录。
例子:
// register the local file with the HTTP server string url = host.GetUrlForDocument(openFileDialog.FileName); // open in embedded web browser webBrowser.Navigate(url);
实施说明
类Host(实现 HTTP 服务器和注册方法)实现了该IDisposable模式。调用者正确处理组件很重要,否则应用程序可能不会退出。
出于性能和响应性的原因,PDF.js 文件是在主机初始化后异步提取的。这假设在加载第一个文档预览之前会经过一段时间(否则,主线程将阻塞直到进程完成)。
HTTP 服务器支持GET,HEAD和OPTIONS方法(即使浏览器似乎没有利用后两者)。它还支持If-Modified-Since请求标头并允许浏览器缓存内容。这可以缩短后续预览的加载时间。
向主机注册本地文件名后,其 URL 在上次访问后的 30 分钟内保持有效。
源代码
该项目在 GitHub 上可用,还有一个演示应用程序: https ://github.com/BradSmith1985/PdfJsDesktopHost
---------------------------------------------------------------
In the past, I have used Windows Preview Handlers as a convenient means of previewing documents inside my Windows Forms applications. The main advantage of this was not having to write my own previewing logic for a (potentially limitless) range of file formats, and using a standard OS feature that has been widely supported since Windows Vista.
Unfortunately, one of the great benefits of preview handlers has also caused a lot of headaches for me; not all implementations are created equally. Some handlers are well-written and play nice with .NET hosts, others have major bugs and memory leaks, and some simply do not work at all. And one of the worst culprits is Adobe’s PDF Preview Handler, installed along with Adobe Reader and Acrobat.
I’ve now come to the conclusion that, at least for PDFs, Preview Handlers are no longer a viable solution and a more reliable alternative is needed. The problem is that generating a preview for a PDF document is no trivial exercise – to do so requires a parser, a PostScript interpreter, libraries for typography, image processing, compression, cryptography and more. While I have been experimenting with all of these, I needed something that was suitable for immediate production use.
Enter, PDF.js…
PDF.js is a JavaScript library, developed by Mozilla Labs, that can be used to view PDFs in a web browser. It is the basis for the built-in PDF viewer in Firefox, but also works in other browsers. Unlike other mechanisms, it requires no operating system or third party PDF applications to be installed, being completely self-contained. It’s also small (around 4MB) and performs quite well.
If I was developing a web application, I would most certainly leverage PDF.js to preview documents – it’s the obvious choice, really. However, working mostly in the desktop world, I needed a way of utilising this excellent library in the Windows Forms environment.
The WebBrowser problem
The built-in WebBrowser control is a handy way of leveraging HTML/JavaScript content inside a desktop application. As well as being able to display content alongside other controls on a form, there is also some limited interactivity possible between the DOM and the hosting application. So on face value it might seem like a good way to leverage PDF.js…
Problems:
- For compatibility reasons, the browser runs in Internet Explorer 7 emulation mode, which lacks proper, standards-compliant HTML, CSS and JavaScript support.
- The PDF.js viewer does not work properly unless loaded over HTTP – a file URL is not sufficient.
- PDF.js (in the majority of cases) can only render documents loaded from the same origin (domain) as itself.
Solving these problems with a local HTTP server
The first problem has been largely solved by PDF.js already; it is possible to override the compatibility settings for the web browser control by including the X-UA-Compatible meta tag in the <head> section of the HTML page. This elevates the browser to Internet Explorer 11 mode. A version of PDF.js built for ECMAScript version 5 browsers (including IE11) is available, making it possible to use the viewer in that browser.
The other two problems require a more drastic solution; since the script expects to be loaded over HTTP, we need to serve it using a local HTTP server. Ideally this should be something lightweight that does not require additional setup or elevated privileges to run. Due to the same-origin requirement, we also need a way of ensuring that the document loaded into the viewer can be accessed via the same server.
To meet these requirements, I chose NHttp – a simple embedded HTTP server with no other dependencies. Unlike the .NET Framework’s built-in HTTP server based on http.sys in Windows, NHttp does not require URL reservations and therefore does not require admin privileges to run. It also spins up quickly, making it very desirable for our needs.
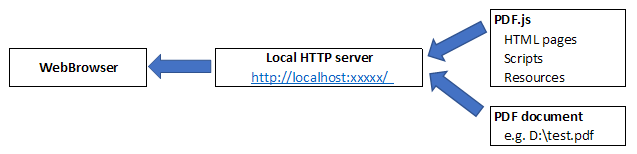
The server simply acts as a proxy between the PDF.js scripts, the document to be previewed and the web browser. It places them behind an HTTP URL and ensures that they are accessed from the same origin (even if their true locations differ). Together, this solves all of the problems above.
How it works
From start to finish, the process of previewing a PDF inside a WebBrowser control is as follows:
- The PDF.js files are extracted to a temporary directory when the component is initialised. By storing these inside the assembly as an embedded resource, the project has an even lighter footprint.
- The HTTP server starts listening on the local IP address, using a random port number so as not to interfere with any other services that might need port 80.
- The application registers a local filename (which could be on another drive or network share) with the server, in exchange for a unique URL that will be used to display the preview. (In theory, this could also be an in-memory stream or even a document located at another URL) This URL points to the PDF.js viewer, preloaded with the correct document.
- The application navigates the
WebBrowsercontrol to the URL obtained in the previous step. - The server receives multiple requests. Depending on the path:
- If the path starts with “/doc”, then the local filename registered in step 3 is served to the browser.
- If the path corresponds to one of the PDF.js source files, that file is served to the browser.
- The
WebBrowserloads the viewer, and PDF.js loads and displays the document to the user. - When the application no longer needs to display the preview, the HTTP server can be stopped. At this point, the temporary directory can be cleaned up as well.
Implementation notes
The Host class (which implements the HTTP server and the registration method) implements the IDisposable pattern. It is important that caller properly disposes the component or else the application may not exit.
For performance and responsiveness reasons, the PDF.js files are extracted asynchronously after the host is initialised. This assumes that some time will elapse before the first document preview is loaded (otherwise, the main thread will block until the process has completed).
The HTTP server supports GET, HEAD and OPTIONS methods (even though the browser seems not to take advantage of the latter two). It also supports the If-Modified-Since request header and allows the browser to cache the content. This could improve loading times for subsequent previews.
Once a local filename is registered with the host, its URL remains valid for 30 minutes after it was last accessed.
Source code
The project is available on GitHub, along with a demo application: https://github.com/BradSmith1985/PdfJsDesktopHost

 浙公网安备 33010602011771号
浙公网安备 33010602011771号