源码安装Spark
前提条件
Spark 使用的语言是 Scala,而 Scala 需要运行在 JVM 之上。因此,搭建 Spark 的运行环境应该是 JDK 和 Scala。由于学习 Spark 源码的参考书籍是《Spark内核设计的艺术架构设计与实现》,所以就按照作者安装的版本进行安装:
- Java8
- Scala2.11
- Spark2.1.0
前两者的安装和环境配置就不做讲解了。
安装 Spark
Spark2.1.0 的版本下载地址:https://archive.apache.org/dist/spark/spark-2.1.0/,下载 spark-2.1.0-bin-hadoop2.6.tgz 即可,然后解压到你想要的位置,这里我解压到了 /usr/local/spark-2.1.0-bin-hadoop2.6。
然后在配置环境变量 vim ~/.bash_profile,内容如下:
export SPARK_HOME=/usr/local/spark-2.1.0-bin-hadoop2.6
export PATH=$SPARK_HOME/bin:$PATH
添加完之后执行 source .bash_profile 即可,然后执行命令 spark-shell,结果如下:
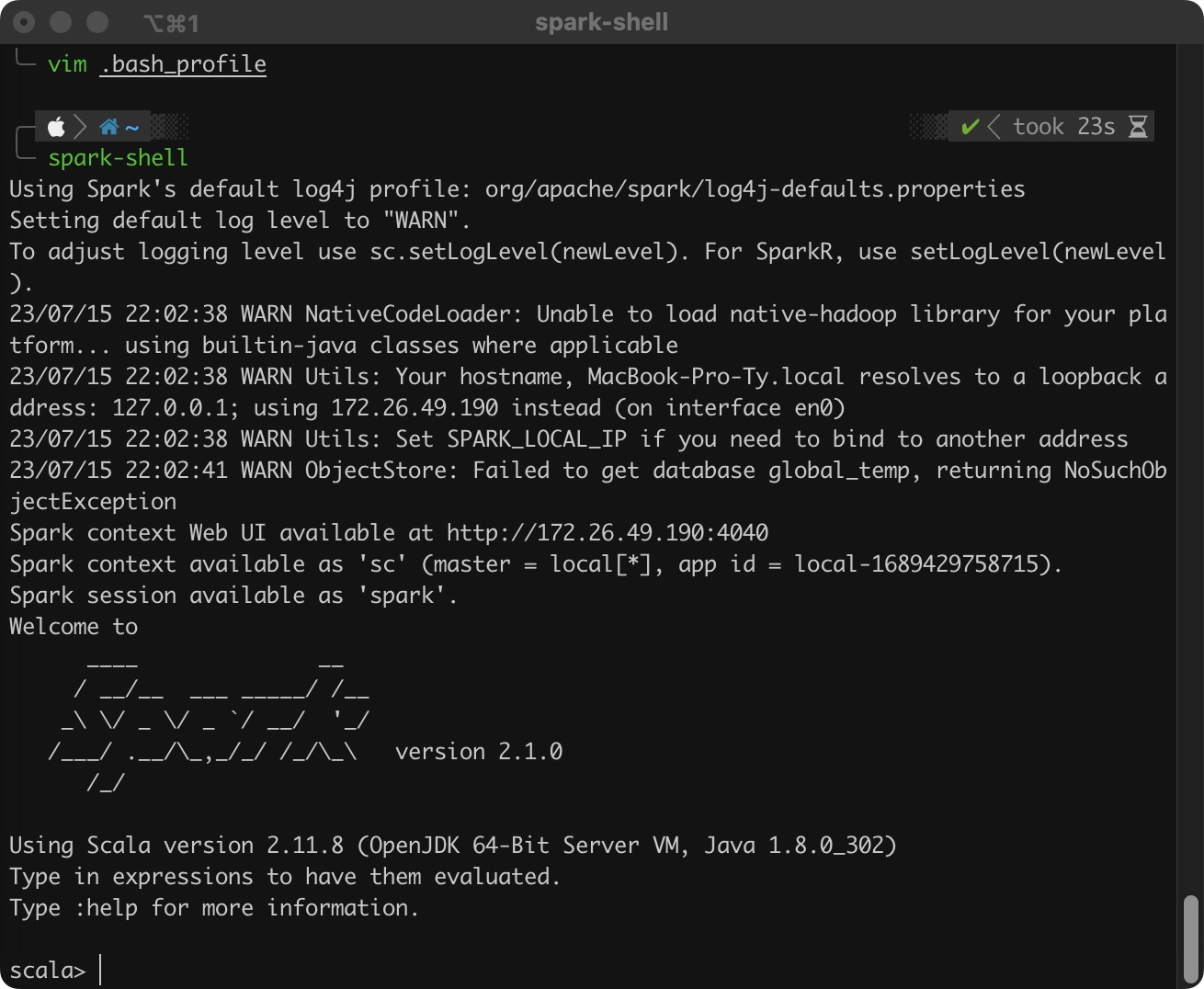
- 如果没有明确指定 log4j 的配置,那么默认使用
org/apache/spark/1og4j-defaults.properties,并且日志级别是 WARN。我们可以自己配置一份 log4j 的配置文件,也可以在 Spark-Shell 命令行中通过sc.setLog-Level(newLevel)来指定日志级别。 - SparkContext 的 WebUI 地址是 http://172.26.49.190:4040。
- 指定的部署模式(即 master)为
local[*],当前应用的 ID 为local-1689429758715。 - 可以在 Spark-Shell 命令行中通过
sc来使用SparkContext,通过spark来使用SparkSession。
配置日志文件
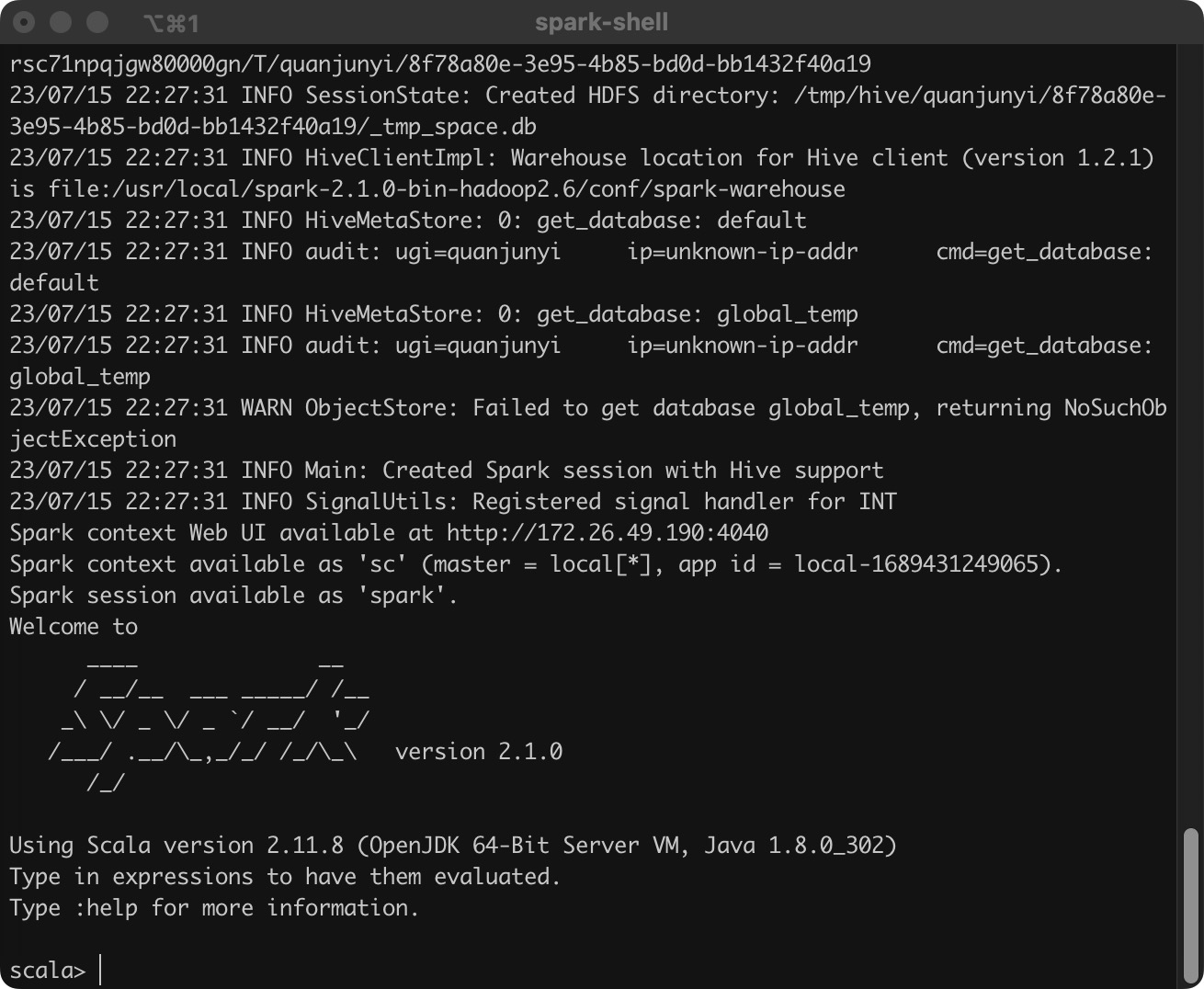
由于 Spark Core 默认日志级别是 WARN,所以给出的信息很少。因此,我们配置一份自己的日志配置文件。
cp log4j.properties.template log4j.properties:将conf/log4j.properties.template复制一份。- 然后修改复制出来的
log4j.properties,将log4j.logger.org.apache.spark.repl.Main修改为INFO。
然后再次执行命令 spark-shell,结果如下:
Spark 源码编译与调试
下载 Spark 源码
在你想要安装的目录下克隆源码并指定分支为 2.1.0:
git clone https://github.com/apache/spark.git -b branch-2.1
编译 Spark 源码
这里我使用的 idea 这个 IDE,所以就使用 Maven 来构建项目,下载相应的 Jar 包。进入 Spark 源码目录(pom.xml 所在目录下),执行如下编译命令:
mvn -T 6 -DskipTests clean package
直到出现 BUILD SUCCESS 就说明编译成功,然后用 idea 打开这个项目。
测试
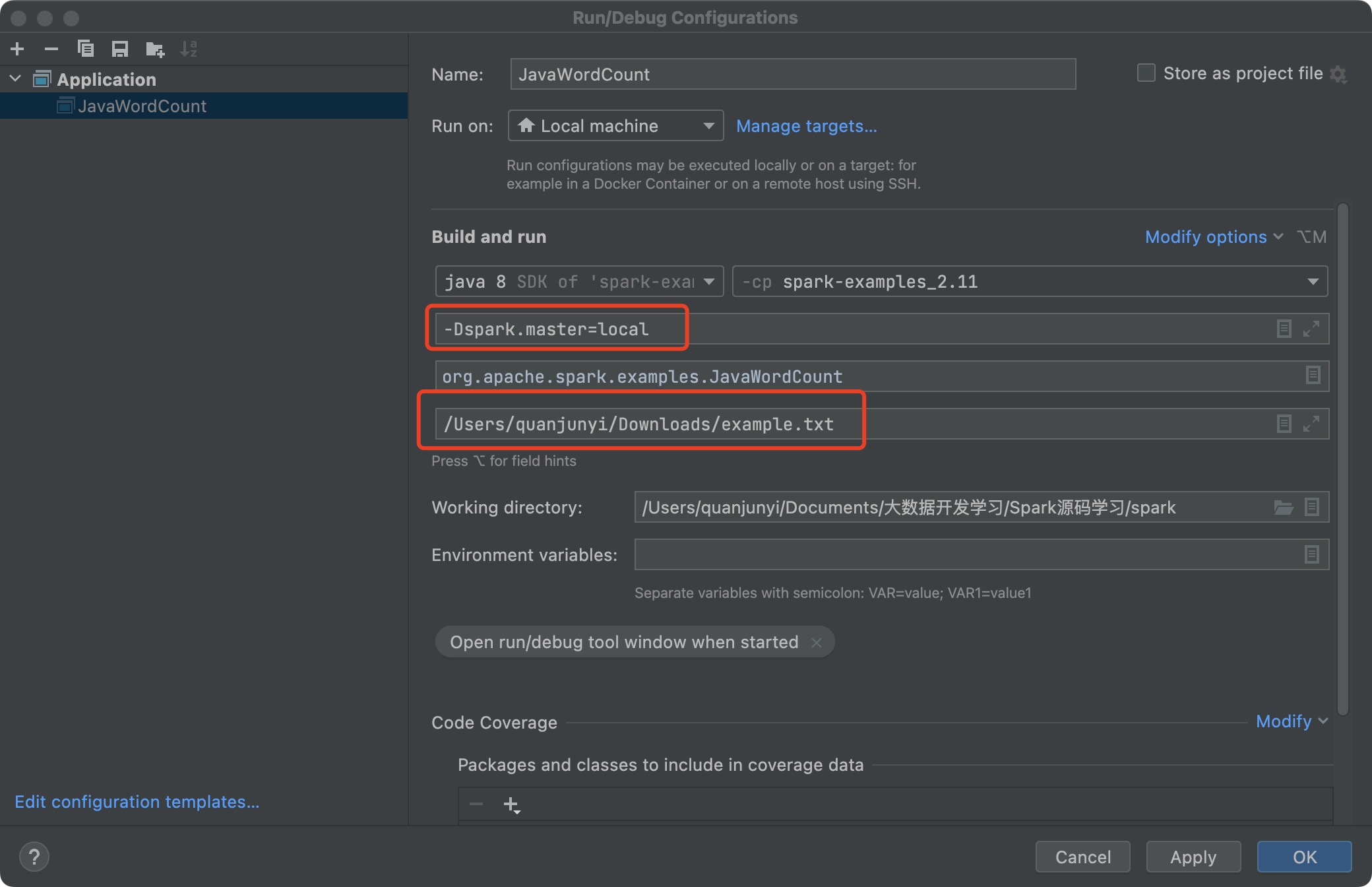
打开 examples/src/main/java/org/apache/spark/examples/JavaWordCount.java 程序,进行测试。运行程序之前,添加一些运行程序所需的参数:
-Dspark.master=local:表示本地模式(-D是 Java 的参数)/Users/quanjunyi/Downloads/example.txt:则是要统计单词的文本
运行之后,报了如下错误:
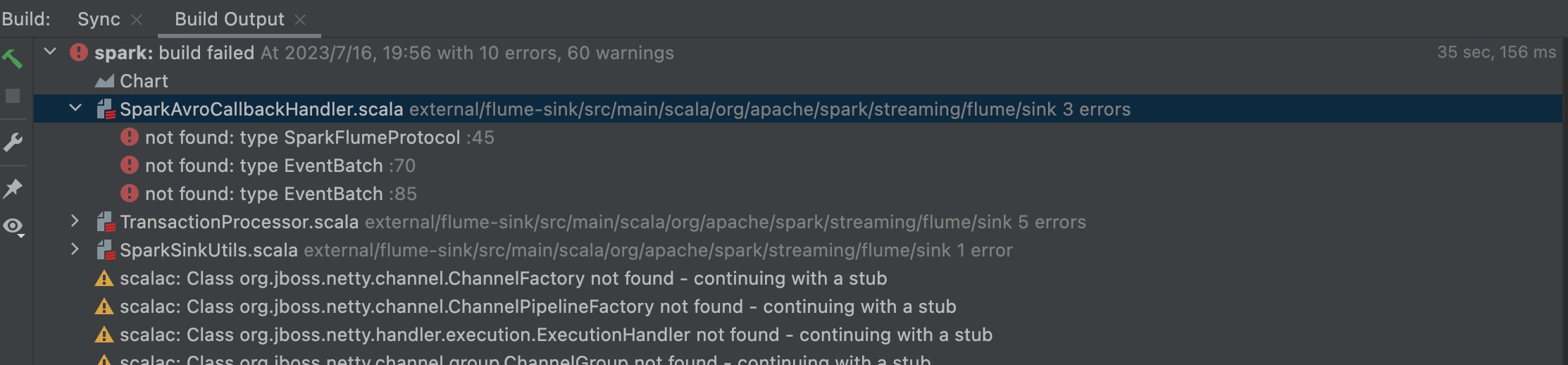
在以下地方右键选择 Generate Sources and Update Folders,然后再次运行程序,还是没变化。
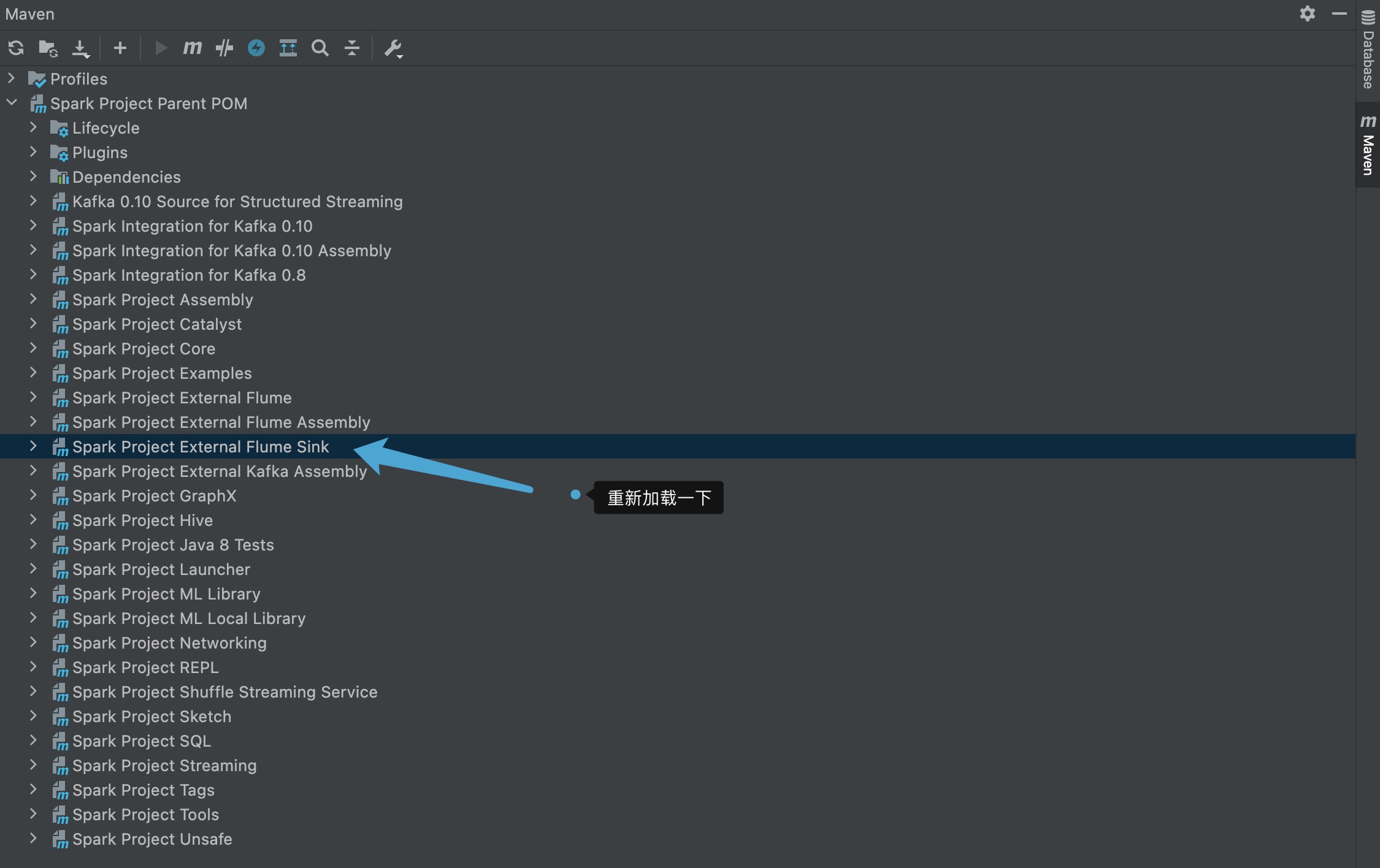
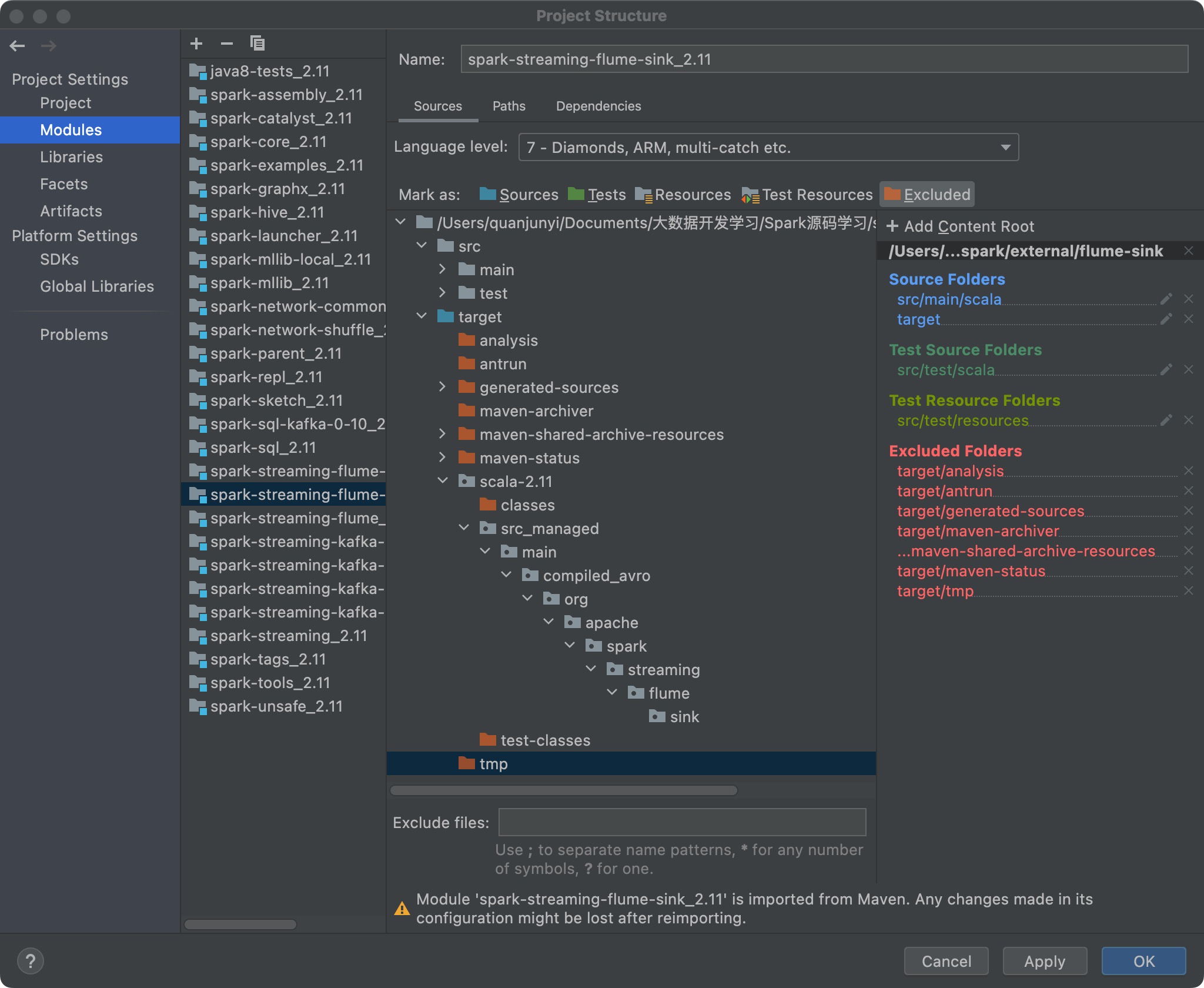
原来 Spark Project External Flume Sink 是排除的,在默认设置下导入 Spark 源代码时,因此只要进行如下修改即可:
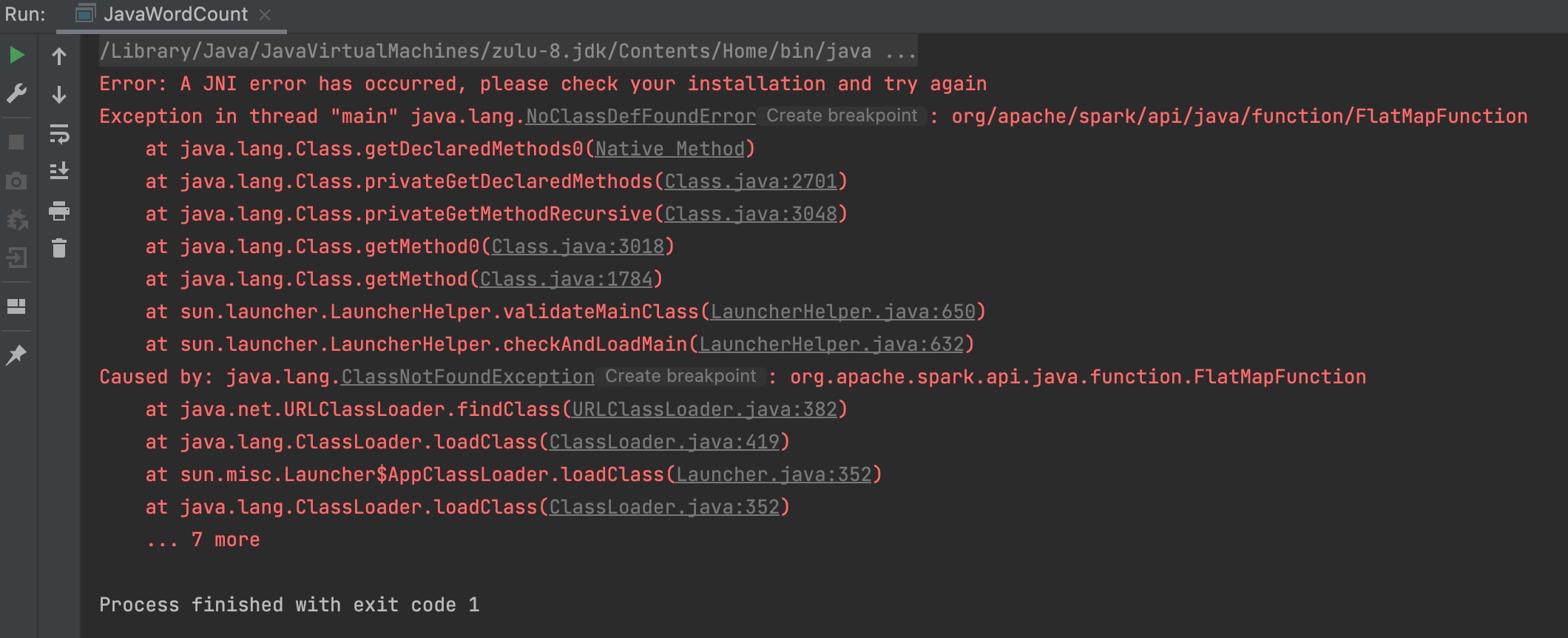
再次运行程序,就会报新的错误:
解决办法,将项目的 assembly 目录下的 scala-2.11 下的 jar 包添加进来,具体目录为 assembly/target/scala-2.11/jars:
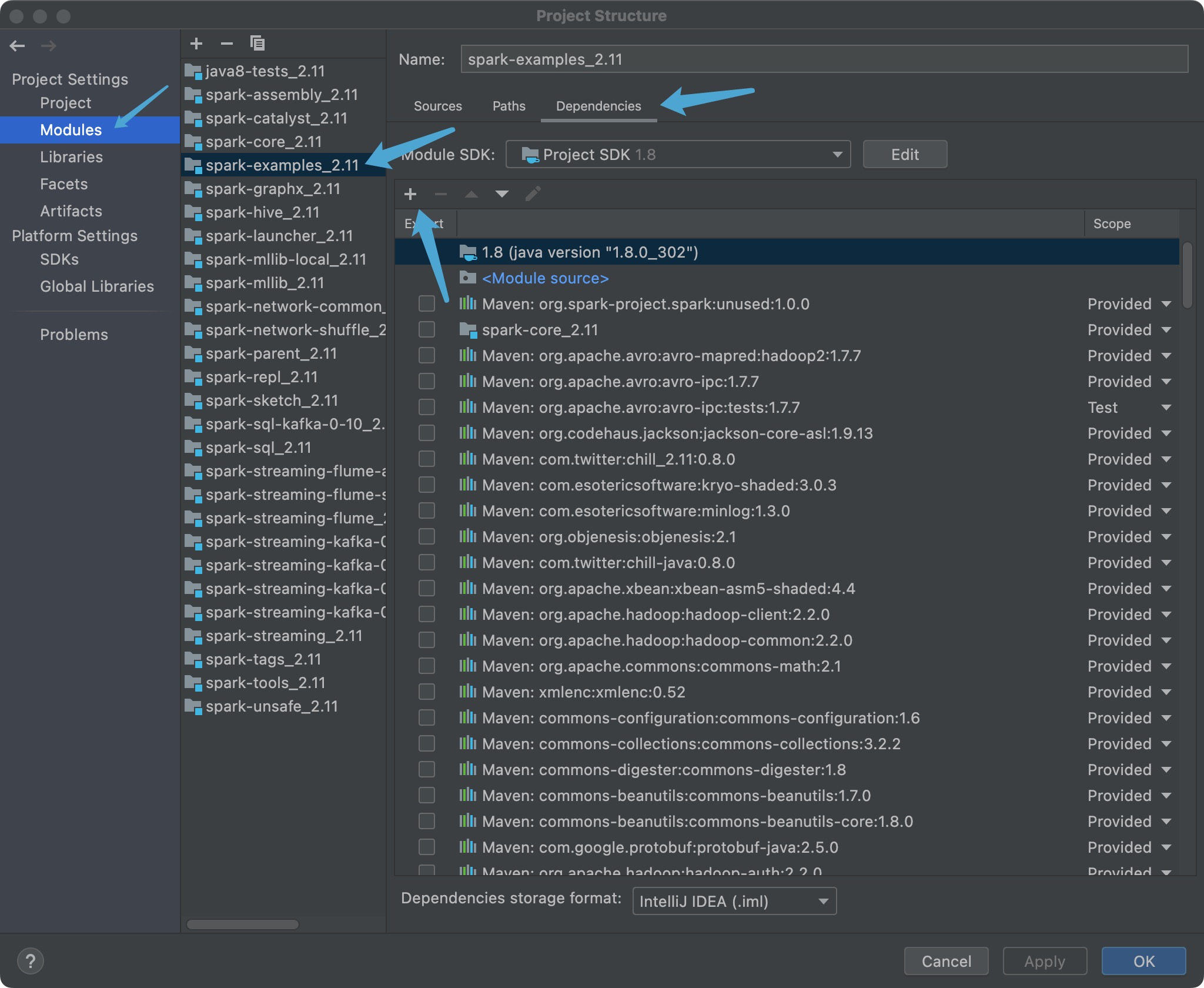
然后就运行成功了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号