数据库内核:PostgreSQL 查询执行和性能
查询执行
查询执行简介
在这一阶段中,数据库引擎接受从优化器而来的执行计划,执行该计划并得到结果元组。
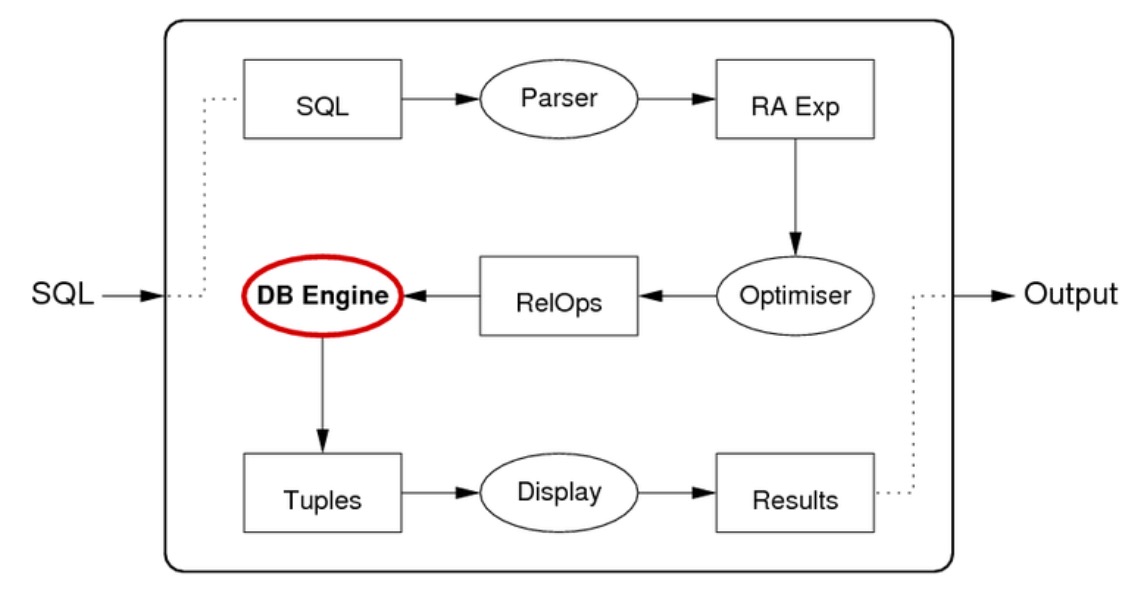
以下是一个具体的例子,SQL 查询如下:
select s.name, s.id, e.course, e.mark
from Student s, Enrolment e
where e.student = s.id and e.semester = ’05s2’;
Translator 先将 SQL 映射为一个 RA 表达式:
\(\pi_{name,id,course,mark}(Stu\bowtie_{e.student=s.id}(\sigma_{semester=05s2}(End)))\)
优化器会为每个操作选择特定的 RelOps,将其映射为一个执行计划:
Temp1 = BtreeSelect[semester=05s2](Enr)
Temp2 = HashJoin[e.student=s.id](Stu,Temp1)
Result = Project[name,id,course,mark](Temp2)
查询执行计划:
- 由 RelOps 的集合组成
- 一起执行以产生一组结果元组
结果可以从一个操作器传递给下一个操作器,两种方式:
- materialization:将结果写入磁盘并回读
- pipelining:通过内存缓冲区生成和传递
Materialization
两个操作器之间的实现步骤:
- 第一个操作器读取输入,然后将执行后的结果写到磁盘中
- 下一个操作器就从磁盘中读取上一个操作之后的结果
实际上临时表是作为实表生成的,因为它存在了磁盘上。
优点:中间结果可以放在文件结构中,这可以选择不同的访问方式以加快后续操作的执行。
缺点:中间结果需要磁盘空间/写入,需要磁盘访问权限才能读取中间结果,这是耗时又耗空间的。
Pipelining
两个操作器之间的实现步骤:
- 操作器同时执行生产者和消费者的职能
- 构造为交互的迭代器(
open,while(next),close)
优点:无需磁盘访问(结果通过内存缓冲区传递)
缺点:更高级别的操作器通过线性扫描访问输入,需要足够的内存缓冲区来保存所有输出
迭代器会以 “流” 的形式生成结果,数据库管理系统会把之前得到的执行计划中的每一个操作变为一个迭代器。
iter = startScan( params ):为迭代器设置数据结构(创建状态,打开文件等等)tuple = nextTuple(iter):在迭代中获取下一个元组。如果没有,则返回 nullendScan(iter):为迭代器清理数据结构
一个 Pipelining 的例子,以下是查询 SQL:
select s.id, e.course, e.mark
from Student s, Enrolment e
where e.student = s.id and e.semester = ’05s2’ and s.name = ’John’;
通过 RA 树节点之间的通信进行评估:
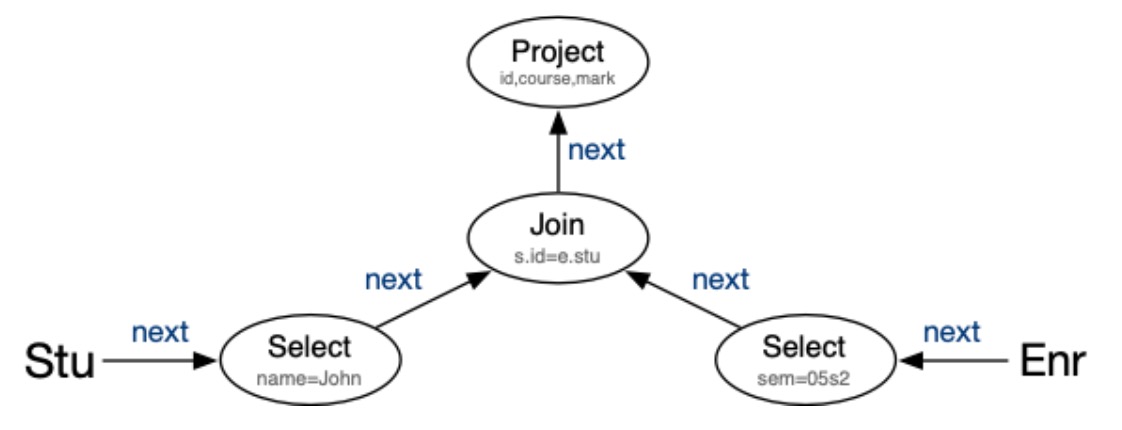
在这幅图中,需求从上向下传播,需要的元组从下向上传递。
流水线不能避免完全不访问磁盘。一些操作使用多个通道(例如合并排序、哈希连接)。这些操作需要使用多轮,那么数据就需要在第一轮中写入,后面进行一轮轮读取。因此,在一个操作中,可能需要进行磁盘读写,但是操作与操作之间,不需要磁盘读写。
PostgreSQL 中的查询执行
定义在 src/include/executor 和 src/include/nodes。
代码在 src/backend/executor。
PostgreSQL 使用流水线(尽可能多):
- 查询计划是计划节点的树
- 每种类型的节点都实现一种 RA 操作(节点通过迭代器接口实现特定的访问方法)
- 节点类型(
Scan, Group, Indexscan, Sort, HashJoin) - 执行通过
PlanState节点树进行管理(镜像计划节点树的结构,保持执行状态)
src/include/executor 中的模块可以分为两组:
execXXX:例如execMain, execProcnode, execScan,实现了计划评估的通用控制,向节点迭代器提供整体计划执行和调度。nodeXXX:例如nodeSeqscan, nodeNestloop, nodeGroup,为特定类型的 RA 操作器实现迭代器,一般包含ExecInitXXX, ExecXXX, ExecEndXXX三种函数。
考虑下面这个 SQL 查询:
select e.age, d.nemps
from Departments d, Employees e
where e.name = d.manager and d.name =’Shoe’;
相应的执行计划树为:

最开始的入口函数为 InitPlan() 会对执行计划树的根节点调用 ExecInitPlan(),ExecInitPlan() 看到根节点是 Nested Loop Join,就会调用 ExecInitNestedLoop() 函数来生成相应的迭代器。在 ExecInitNestedLoop() 函数中会对左子计划节点调用 ExecInitPlan() 函数,以及对右子计划节点调用 ExecInitPlan() 函数,这两个函数分别看到自己的计划是 Index Scan 和 Seq Scan,然后就会分别去调用 ExecInitIndexScan() 和 ExecInitSeqScan 函数。因此,它会创建与执行计划树具有相同结构的计划状态树。
有了计划状态树之后,执行 ExecutePlan() 函数重复去调用 ExecProcNode() 函数,ExecProcNode() 函数首先对根节点调用,发现是 NestedLoop 节点,所以就调用 ExecNestedLoop() 去获取下一个元组,该函数还包含 ExecProcNode() 函数分别调用它的左右子计划,然后两个左右子计划分别调用 ExecIndexScan() 和 ExecSeqScan() 去获取下一个元组,最后向上返回元组。
查询性能
如果数据库管理系统花了很长的时间来回答查询,该怎么办,提升性能涉及以下几个方面:
- 一般来说,SQL 查询大多是某个应用的一部分,所以,可以选择提升该应用的整体效率
- 降低 Query/Transaction 的响应时间
- 提升 Transaction 整体的吞吐量
从某种层面来说,查询优化器消除了来自于数据库开发者的一些干扰和噪音,这是因为它会在 “最佳” 执行计划上以自己的判断做出决定。 除此以外,调优还需要我们考虑以下问题:
- 会用到什么 Query/Transaction
- 每个 Query / Transaction 的使用频率
- 对于 Query/Transaction 是否有时间限制
- 都某些 Attribute 是否有特别的限制(比如取值是否会有重复)
- 多久更新一次

 浙公网安备 33010602011771号
浙公网安备 33010602011771号