数据库内核:PostgreSQL 存储
存储管理
数据库管理系统的存储管理分级
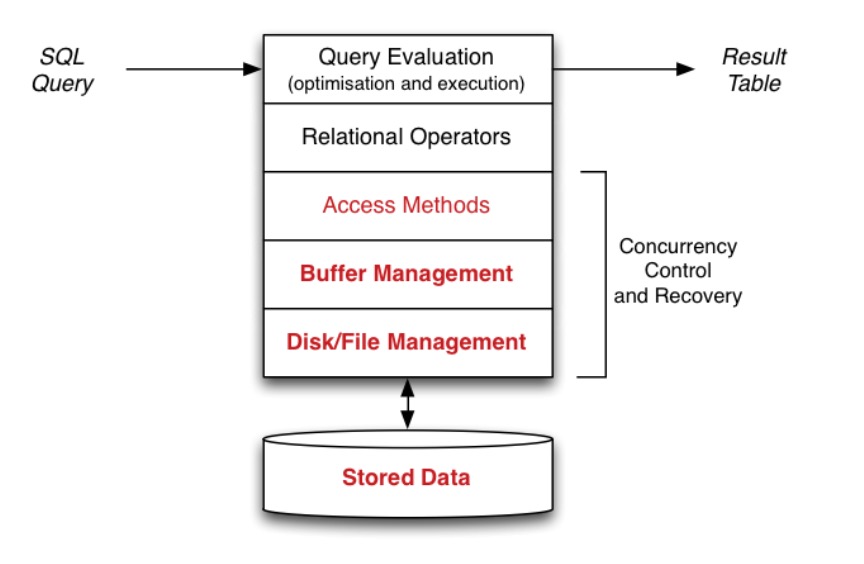
在数据库管理系统中存储管理的目的是:
-
提供页或者元组集合的数据视图
-
将数据库对象(例如表)映射到磁盘文件上
-
管理数据与磁盘存储之间的传输
-
使用缓冲区来减少磁盘/内存之间传输次数
-
将加载的数据还原成为元组
-
是使用访问方法来访问文件结构的基础
数据库管理系统中存储管理分为如下几个级别:
- 磁盘或文件(Disks and Files):磁盘文件的性能问题和组织
- 缓存区管理(Buffer Management):使用缓存来提高数据库管理系统的吞吐量
- 元组或页管理(Tuple/Page Management):元组是如何在磁盘中存储和管理的
- 数据库对象管理(Catalog):表、视图、函数、类型等对象是如何表示的
以查询数据的视角来看存储结构
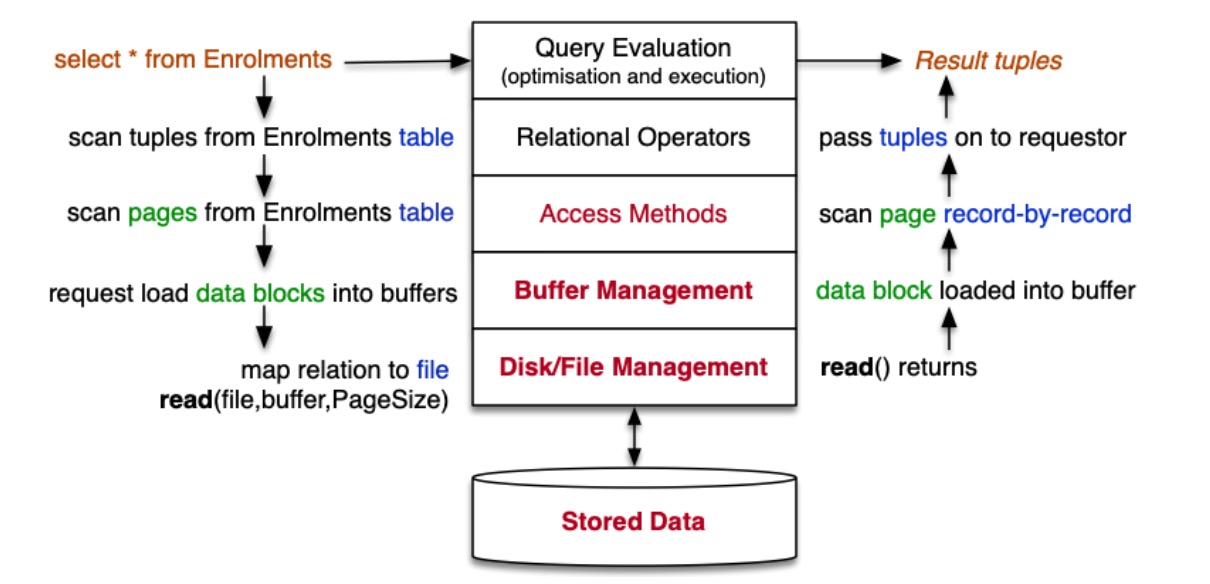
在查询过程中,表示数据库对象的有:
DB:处理一个授权或开放的数据库Rel:处理一个开放的关系Page:存储磁盘块内容的内存缓冲区Tuple:保存来自一个元组的数据值的内存
在数据库管理系统中的寻址方式:
- \(PageID=FileID+Offset\):表示一个数据块,\(Offset\) 表示这个数据块在文件中的位置
- \(TupleID=PageID+Index\):表示一个元组,\(Index\) 表示这个元组在数据块(页)的位置
存储技术
存储介质类别
- 持久存储:存储空间大、价格低、获取数据速度慢、以块为单位访问,但是可以存储很长的时间
- 计算存储:存储空间小、价格高、获取数据速度快、以字节或者字为单位访问,一般用于分析数据
- HDD 与 RAM 访问数据速度之比约是 100000:1,也就是说
- 10 毫秒可以读取包含两个元组的块
- 1 微妙可以对两个元组进行比较
硬盘是成熟的、廉价的、大容量的一种存储介质。
另外还有一种批量存储的介质:固态硬盘(SSD):
- 比 HDD 更快,没有延迟
- 可以读取单个项目
- 更新需要块擦除然后写入
- 随着时间的推移,需要重写“磨损”块
- 需要分散写入负载的控制器
| HDD | SDD | |
|---|---|---|
| Cost/byte | 约 4c/GB | 约 13c/GB |
| 读取延迟 | 约 10ms | 约 50μs |
| 写入延迟 | 约 10ms | 约 900μs |
| 读取单元 | 块(例如 1KB) | 字节 |
| 写的方式 | 写入一块数据块 | 写入一块空的数据块 |
成本模型
数据库操作的成本主要的方面:
- 数据总是作为整个块(页面)传输到磁盘或者从磁盘中传出
- 在内存中操作元组的成本可以忽略不计
- 总成本主要由数据块的读/写次数决定
但是,并非所有页面访问都需要进行磁盘的访问(当数据在缓冲池中时),而且元组通常是可变大小的。
文件管理
文件管理子系统的目的:
- 组织文件系统内的数据布局
- 处理从数据库 ID 到文件地址的映射
- 在缓冲池和文件系统之间传输数据块
- 尝试处理文件访问错误问题(重试)
- 在操作系统文件操作之上构建更高级别的操作
操作系统提供的一般文件操作:
fd = open(fileName,mode) // 打开fileName文件用于读、写
close(fd) // 关闭打开的文件
nread = read(fd, buf, nbytes) // 尝试从文件中读取数据到缓冲区中
nwritten = write(fd, buf, nbytes) // 尝试将缓冲区的数据写入到文件中
lseek(fd, offset, seek_type) // 将文件指针移动到相对/绝对文件偏移量
fsync(fd) // 将文件缓冲区的内容刷新到磁盘
数据库管理系统的文件组织
不同的数据库管理系统会有不同的选择:
- 绕过文件系统并使用原始磁盘分区
- 一个包含所有数据库数据的非常大的文件
- 有几个大文件,表分布在它们之间
- 拥有多个数据文件,每个表一个
- 每个表都有多个文件
- 等等
单文件的存储管理器
整个数据库只有一个文件(例如 SQLite),对象都被分配到文件划分出来的区域(段)中。

如果一个对象对分配的段来说太大,就需要分配一个扩展的段。
在 Unix 文件中分配空间是很容易的,只需寻找到你想要的地方并写下数据,如果那里没有数据,数据就会附加到文件中,如果那里已经有数据了,它就会被覆盖。如果查找远远超出了文件的末尾,Unix 就不会为“漏洞”分配磁盘空间,仅当数据写入那里时,才会分配磁盘存储。
考虑以下简单的单文件的数据库管理系统的布局

每个文件段由一个数字固定大小的块组成,以下是一些重要的数据/常量的定义:
#define PAGESIZE 2048 // 每页的字节数,一般设置为1024, 2048, 4096, 8192
typedef long PageId; // PageId是块的索引,pageOffset=PageId*PAGESIZE
typedef char *Page; // 指向页或块的缓冲区的指针
开放的数据库和表的存储管理器的数据结构
typedef struct DBrec { // 数据库的存储管理器的数据结构
char *dbname; // 数据库的名称副本
int fd; // 数据库文件的地址
SpaceMap map; // 空闲和已使用区域的映射
NameTable names; // 将名称映射到 areas + sizes 处
} *DB;
typedef struct Relrec { // 表的存储管理器的数据结构
char *relname; // 表的名称副本
int start; // 表的开始数据所在的页的索引
int npages; // 表数据所占页的数量
...
} *Rel;
例子:查看关系
select name from Employee
实现的“伪”代码:
DB db = openDatabase(”myDB”); // 获取名为myDB数据库对象
Rel r = openRelation(db,”Employee”); // 打开数据库中Employee这张关系表,得到表对象
Page buffer = malloc(PAGESIZE*sizeof(char)); // 获取PAGESIZE*sizeof(char)大小的缓冲区
for (int i = 0; i < r->npages; i++) { // 遍历Employee这张关系表所占的所有页面
PageId pid = r->start+i; // 当前页面的索引
get_page(db, pid, buffer); // 将当前页面中的数据加载到缓冲区中
for each tuple in buffer { // 对缓冲区中的元组进行遍历
get tuple data and extract name
add (name) to result tuples
}
}
对数据库对象的初始化和释放操作
DB openDatabase(char *name) { // 初始化
DB db = new(struct DBrec); // 创建一个数据库对象
db->dbname = strdup(name); // 数据库的名字
db->fd = open(name,O_RDWR); // 数据库文件的地址
db->map = readSpaceTable(db->fd); // 数据库中表的映射信息
db->names = readNameTable(db->fd); // 数据库中表的名字
return db;
}
void closeDatabase(DB db) { // 释放资源以及一些同步数据操作
writeSpaceTable(db->fd,db->map);
writeNameTable(db->fd,db->map);
fsync(db->fd);
close(db->fd);
free(db->dbname);
free(db);
}
对关系表对象的初始化和释放操作
Rel openRelation(DB db, char *rname) { // 初始化
Rel r = new(struct Relrec); // 创建一个表对象
r->relname = strdup(rname); // 表名称
r->start = ...; // 表的开始页面
r->npages = ...; // 表的页面总数
return r;
}
void closeRelation(Rel r) { // 释放资源
free(r->relname);
free(r);
}
对页面的操作
// 假设 Page = byte[PageSize],PageId = block number in file
// 从文件系统中读取页面到内存的缓冲区中
void get_page(DB db, PageId p, Page buf) {
lseek(db->fd, p*PAGESIZE, SEEK_SET); // 将文件指针移动到指定页面的位置
read(db->fd, buf, PAGESIZE); // 从文件中读取页面的内容,并将其存储在缓冲区中
}
// 将内存缓冲区的页写入到文件系统中
void put_page(Db db, PageId p, Page buf) {
lseek(db->fd, p*PAGESIZE, SEEK_SET);
write(db->fd, buf, PAGESIZE);
}
管理空间映射表的内容
// 假设存在一个由(偏移量、长度、状态)记录组成的数组,分配n个新页面
PageId allocate_pages(int n) {
if (no existing free chunks are large enough) { // 没有足够大的现有空闲块
int endfile = lseek(db->fd, 0, SEEK_END); // 将文件指针移动到末尾
addNewEntry(db->map, endfile, n); // 在文件的末尾添加一个新条目以分配所需的页面
} else {
grab ”worst fit” chunk // 选择“最差匹配”块
split off unused section as new chunk // 将未使用的部分拆分为新的块
}
}
// 从页面 p 开始释放 n 个页面
void deallocate_pages(PageId p, int n) {
if (no adjacent free chunks) { // 没有相邻的空闲块
markUnused(db->map, p, n); // 将标记这些页面为未使用(markUnused)
} else {
merge adjacent free chunks // 合并相邻的空闲块
compress mapping table // 压缩映射表
}
}
例题:查看关系表的成本
一张模式为 \(R(x,y,z)\) 的表有 \(10^5\) 个元组,有以下假设:
- 元组的数量 \(r=10000\)
- 元组的平均大小是 \(R=200\) 字节
- 页面的大小是 \(B=4096\) 字节
- 读取一个页面的时间为 \(T_r=10\) 毫秒
- 检查一个元组的时间为 \(T_c=1\) 微秒
- 形成一个结果元组的时间 \(T_c=1\) 微秒
- 写一个结果页需要 \(T_w=10\) 毫秒
计算回答以下查询的总时间成本:
insert into S select * from R where x > 10;
假设有一半的元组满足过滤条件。
解:
- 读取输入表
R的总页面数: \(P_R = \lceil\frac{r\cdot R}{B}\rceil=489\) - 读取页面并对所有元组进行过滤的时间成本: \(T_f=P_R\cdot T_r+r\cdot T_c=4890000+10000=4900000\mu s\)
- 插入结果表
S的总页面数: \(P_S = \lceil \frac{r}{2} \cdot \frac{R}{B} \rceil=245\) - 形成结果元组和写入结果表的时间成本: \(T_w = \frac{r}{2}\cdot T_c + P_S \cdot T_w=5000+2450000=2455000\mu s\)
- 因此总时间为 \(7355000\mu s\)
数据库管理系统参数
- 一个关系有 \(r\) 个元组,元组平均大小为 \(R\) 字节
- 这些元祖存储在磁盘上占 \(b\) 个页面
- 每个页面的大小是 \(B\) 字节,包含 \(c\) 个元组
- 数据在磁盘和内存之间转换是以页为单位的
- \(T_r\) 表示磁盘和内存之间转换的成本,\(T_w\) 表示其他成本

多文件的磁盘管理器
大多数数据库管理系统不会对所有数据都使用单个大文件。一般会提供:
- 在物理上或逻辑上分区为多个文件
- 将数据库级的对象映射到文件(例如通过元数据)
使用多个文件(每个关系一个文件),这会更容易。但是具体的文件结构还是依赖于数据库管理系统。
单文件与多文件比较
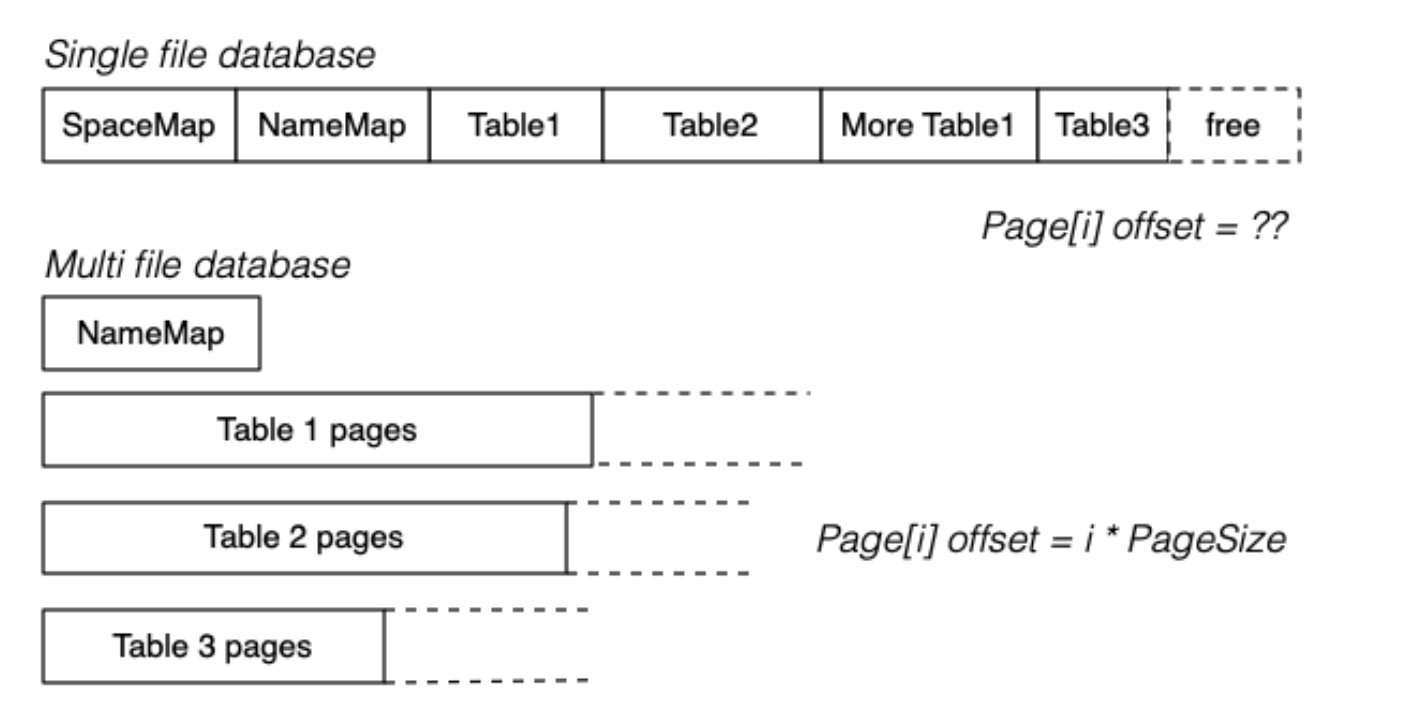
如果系统每个表都使用一个文件,PageId 包含:
- 关系标识符(用于映射到对应的文件名,以确定所属的表)
- 页码(用于标识在该文件中的具体页面)
如果系统每个表使用多个文件,PageId 包含:
- 关系标识符
- 文件标识符(与关系标识符结合,给出了文件名,用于确定所在的具体文件)
- 页码
PostgreSQL 的文件管理
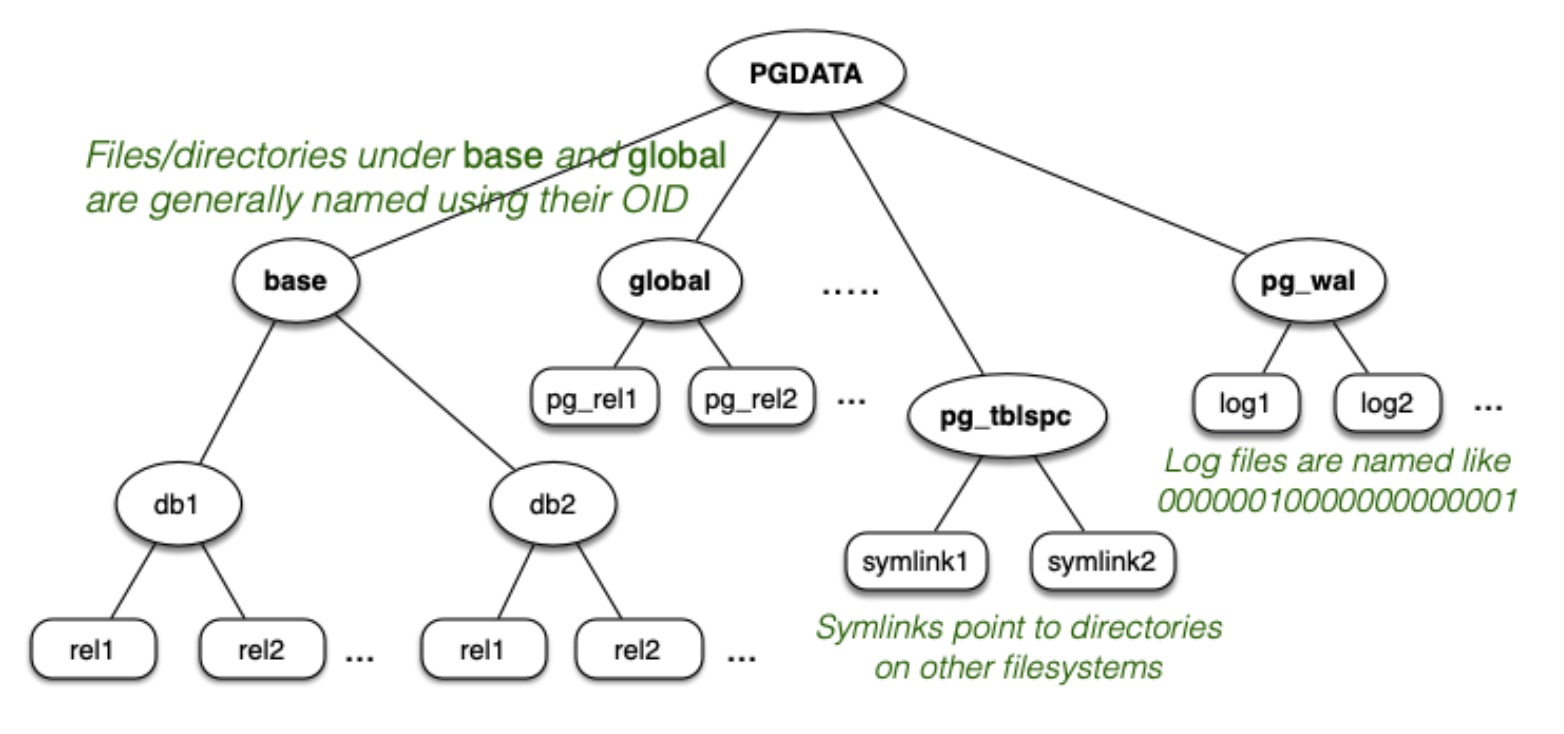
存储子系统的组件:
- 从关系到文件的映射(
RelFileNode):包含关系的标识符,可以映射到对应的文件名或文件描述符。 - 开放的关系池的抽象(
storage/smgr):用于管理和操作关系文件,包括创建、打开、关闭、读取、写入等操作。Smgr 专为许多存储设备设计,仅提供磁盘处理程序。 - 管理文件的函数(
storage/smgr/md.c):实现了管理文件的具体函数和逻辑,提供了对文件的创建、删除、重命名、扩展、截断等操作的支持。 - 文件描述符池(
storage/file):用于管理文件描述符的分配和释放,负责维护可用的文件描述符池,用于打开和操作文件,避免频繁地打开和关闭文件,提高文件操作的效率。
PostgreSQL 中有两类基础类型的文件:
- 包含数据的堆文件
- 包含索引条目的索引文件
在 PostgreSQL 中都是通过其 OID 来识别关系文件的。其核心数据结构是 RelFileNode:
typedef struct RelFileNode {
Oid spcNode; // 表空间是数据库中逻辑存储空间的组织单位,用于存储表和索引等数据库对象的物理文件。
Oid dbNode; // 数据库
Oid relNode; // 关系
} RelFileNode;
在全局共享表(pg_database)中的参数:spcNode == GLOBALTABLESPACE_OID 和 dbNode == 0。
relpath函数将RelFileNode映射到文件
// 根据 RelFileNode 中的 spcNode 和 relNode 字段的值,确定了不同情况下的文件路径
char *relpath(RelFileNode r) {
char *path = malloc(ENOUGH_SPACE);
if (r.spcNode == GLOBALTABLESPACE_OID) { // 关系属于共享系统关系,存储在 PGDATA/global 目录中
Assert(r.dbNode == 0);
sprintf(path, ”%s/global/%u”,
DataDir, r.relNode); // 将路径拼接为 DataDir/global/关系标识符 的形式
}
else if (r.spcNode == DEFAULTTABLESPACE_OID) { // 关系属于默认表空间,存储在 PGDATA/base 目录中
sprintf(path, ”%s/base/%u/%u”,
DataDir, r.dbNode, r.relNode); // 将路径拼接为 DataDir/base/数据库标识符/关系标识符 的形式
}
else { // 其他的表空间
sprintf(path, ”%s/pg_tblspc/%u/%u/%u”, DataDir
r.spcNode, r.dbNode, r.relNode); // 将路径拼接为 DataDir/pg_tblspc/表空间标识符/数据库标识符/关系标识符 的形式
}
return path;
}
文件描述符池
Unix 对并发打开的文件数量有限制,PostgreSQL 维护了一个开放文件描述符池:
- 从更高级别的功能中隐藏这一限制
- 尽量减少昂贵的
open()操作
文件名只是字符串 typedef char *FileName,打开的文件通过索引引用 typedef int File,一个文件就是对“虚拟文件描述符”表的索引。文件描述符的接口(池):
File FileNameOpenFile(FileName fileName, int fileFlags, int fileMode); // 打开一个位于数据库目录($PGDATA/base/)下的文件
File OpenTemporaryFile(bool interXact); // 打开一个临时文件
void FileClose(File file); // 关闭一个打开的文件
void FileUnlink(File file); // 删除一个文件
int FileRead(File file, char *buffer, int amount); // 从文件中读取数据
int FileWrite(File file, char *buffer, int amount); // 向文件中写入数据
int FileSync(File file); // 将文件内容刷新到磁盘,确保数据持久化
long FileSeek(File file, long offset, int whence); // 在文件中移动文件指针的位置
int FileTruncate(File file, long offset); // 截断文件,将文件大小调整为指定的大小
虚拟文件描述符(Vfd)
物理存储在动态分配的数组中:
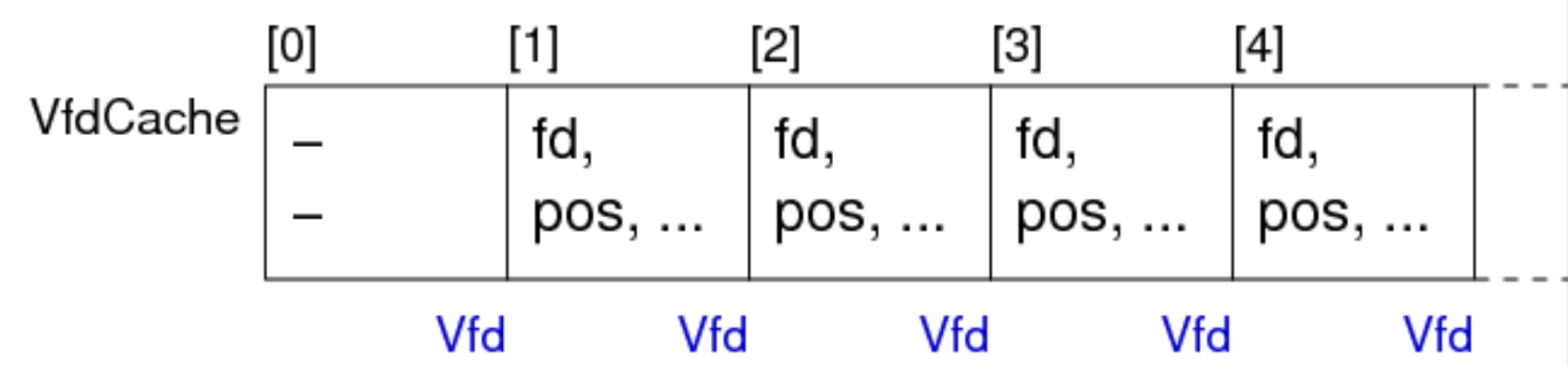
还可以按使用的新旧程度排列成列表:
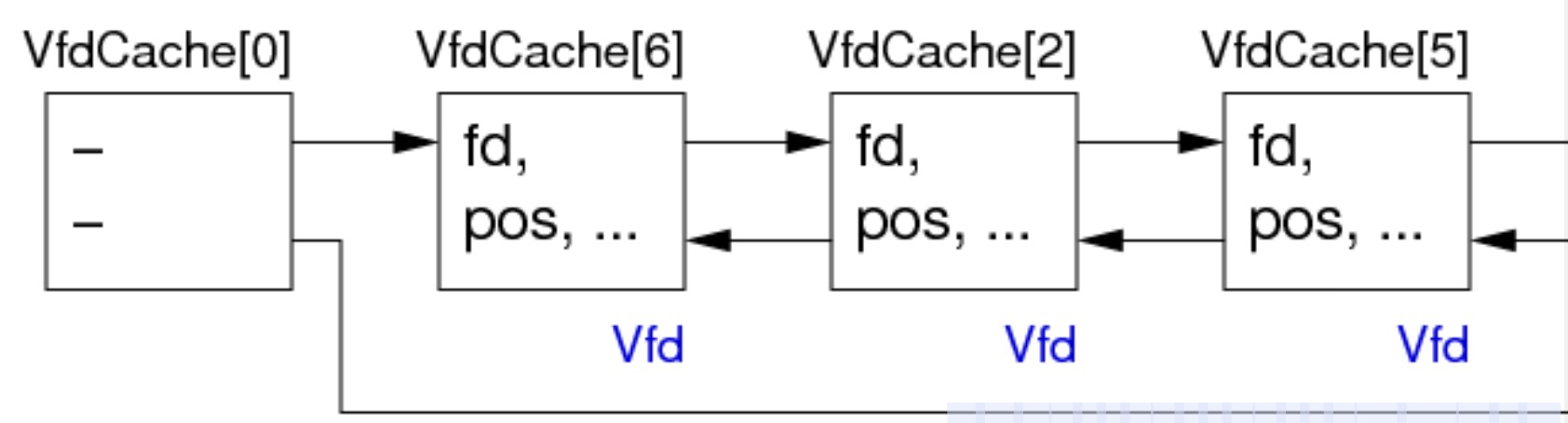
typedef struct vfd
{
s_short fd; // 当前的文件描述符,如果是空,则为 VFD_CLOSED
u_short fdstate; // 当前的文件描述符的状态
File nextFree; // 链接到下一个空的VFD
File lruMoreRecently; // 指向链表前一个VFD
File lruLessRecently;
long seekPos; // 当前文件的逻辑地址
char *fileName; // 文件的名称,如果没有使用VF则为NULL。通过动态分配内存(malloc)而来的,在关闭文件时需要释放内存
int fileFlags; // 用于(重新)打开文件的open(2)标志
int fileMode; // 传递给open(2)的模式
} Vfd;
文件管理
PostgreSQL 将每一张表都存储在 PGDATA/pg_database.oid 中。
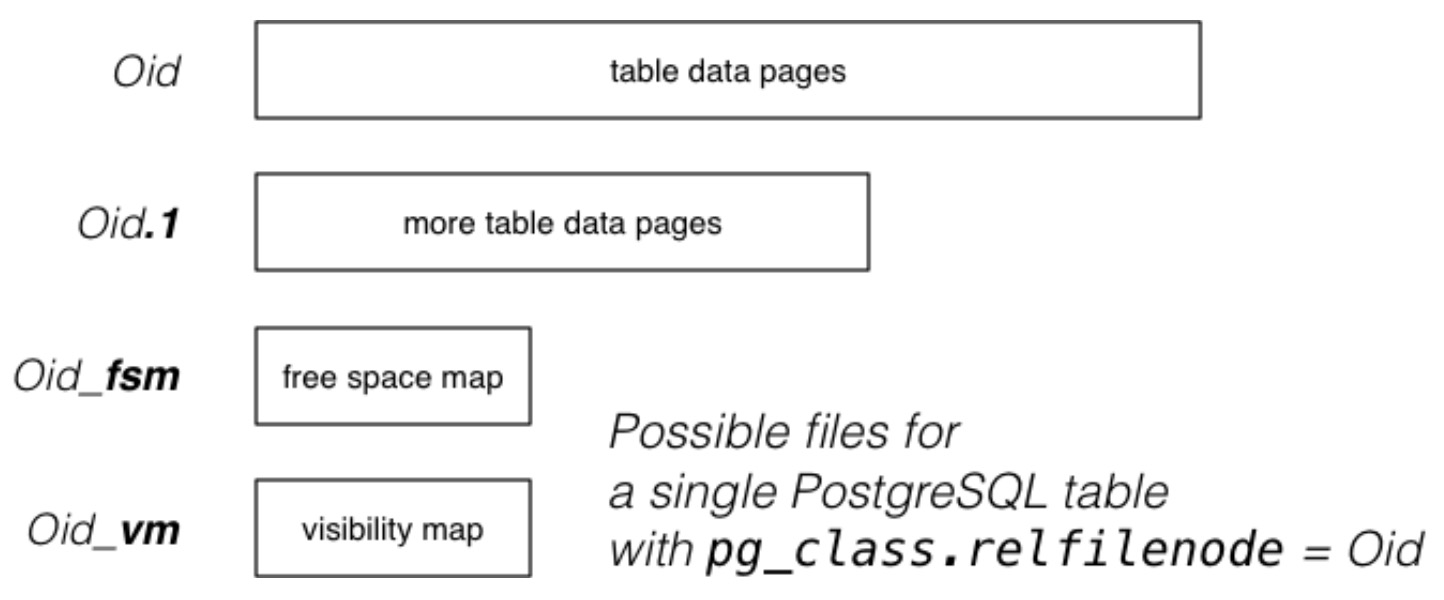
- 数据文件(Oid、Oid.1):固定大小的块/页序列(通常为8KB),每个页面都包含元组数据和管理数据,数据文件的最大大小为 1 GB(Unix 的限制)。
- 自由空间映射(Oid_fsm):表示数据页中的可用空间在哪里,“免费”空间只有在真空后才是免费的,而
DELETE只是将元组标记为不再使用,这种就不是“免费”空间。 - 可见映射(Oid_vm):表示所有元组都是“可见”的页面,可见就是所有当前活跃的事务都可以访问这些页面。
磁盘存储管理器 storage/smgr/md.c:
- 管理自己的开放文件描述符池(Vfd)
- 如果多个分支,可以使用多个 Vfd 来访问数据
- 管理从 PageID 到 file+offset 的映射
在 PostgreSQL 中 PageID 的结构如下:
typedef struct
{
RelFileNode rnode; // 表示与页面相关的关系(relation)和文件(file)
ForkNumber forkNum; // 表示与页面相关的文件的分支(fork),在 PostgreSQL 中,一个表可以有多个分支,每个分支用于不同的目的,如主数据分支(main fork)、TOAST 分支、索引分支等。ForkNumber 是一个枚举类型,用于表示不同的分支。
BlockNumber blockNum; // 表示页面(block)在文件中的块号
} BufferTag;
访问数据块的方法(大致)如下:
// BufferTag结构体用于标识一个页面,Buffer则是用于存储页面数据的缓冲区
getBlock(BufferTag pageID, Buffer buf)
{
Vfd vf; off_t offset;
(vf, offset) = findBlock(pageID) // 根据给定的pageID找到对应的磁盘文件和偏移量
lseek(vf.fd, offset, SEEK_SET) // 将文件指针定位到offset所指定的位置
vf.seekPos = offset;
nread = read(vf.fd, buf, BLOCKSIZE) // 从文件中读取数据,并将数据存储到buf缓冲区中,BLOCKSIZE是全局常量(默认:8192)
if (nread < BLOCKSIZE) ... we have a problem
}
findBlock(BufferTag pageID) returns (Vfd, off_t)
{
offset = pageID.blockNum * BLOCKSIZE // 根据blockNum和页面大小BLOCKSIZE计算偏移量,确定页面在文件中的位置
fileName = relpath(pageID.rnode) // 生成文件名
if (pageID.forkNum > 0) // 表示页面属于某个特定的fork
fileName = fileName+”.”+pageID.forkNum // 在文件名中添加fork信息,以区分不同的fork
if (fileName is not in Vfd pool) // 检查文件名是否存在于Vfd池中,即是否已经打开过该文件
fd = allocate new Vfd for fileName // 如果文件名不在池中,说明是首次访问该文件,需要为其分配一个新的Vfd
else
fd = use Vfd from pool // 如果文件名已存在于池中,说明该文件已经打开,可以直接使用池中的Vfd
if (offset > fd.fileSize) { // 检查偏移量是否超出文件大小,如果是,则说明需要访问下一个fork
fd = allocate new Vfd for next fork
offset = offset - fd.fileSize // 偏移量需要相应地减去当前文件的大小,以确定在下一个文件中的偏移位置
}
return (fd, offset)
}
缓冲池
缓冲池的目的就是保留从数据库文件中读取的页面,以便可能重复使用,提高效率。
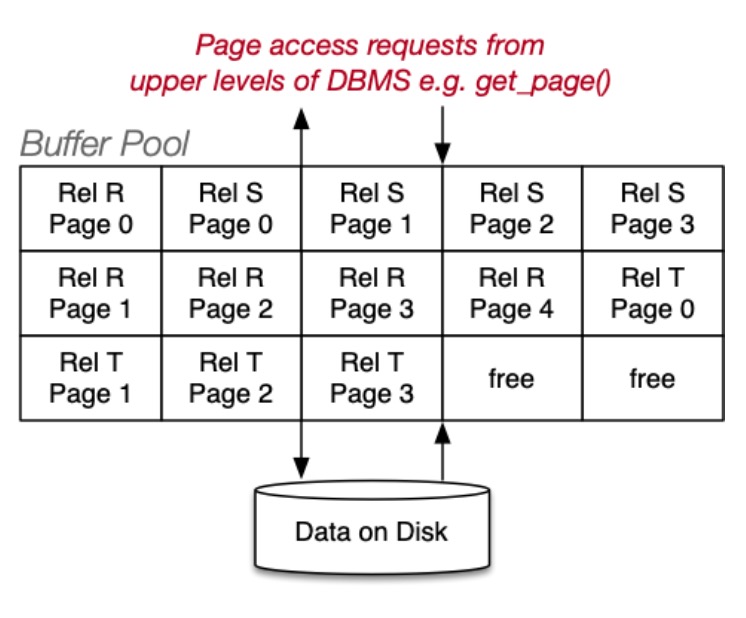
缓冲池的操作(两者都采用单个 PageID 参数):
request_page(pid):用于替代getBlock()release_page(pid):用于替代putBlock()
缓冲池数据结构:
Page frames [NBUFS]FrameData directory [NBUFS]- 这里的
Page是byte[BUFSIZE]
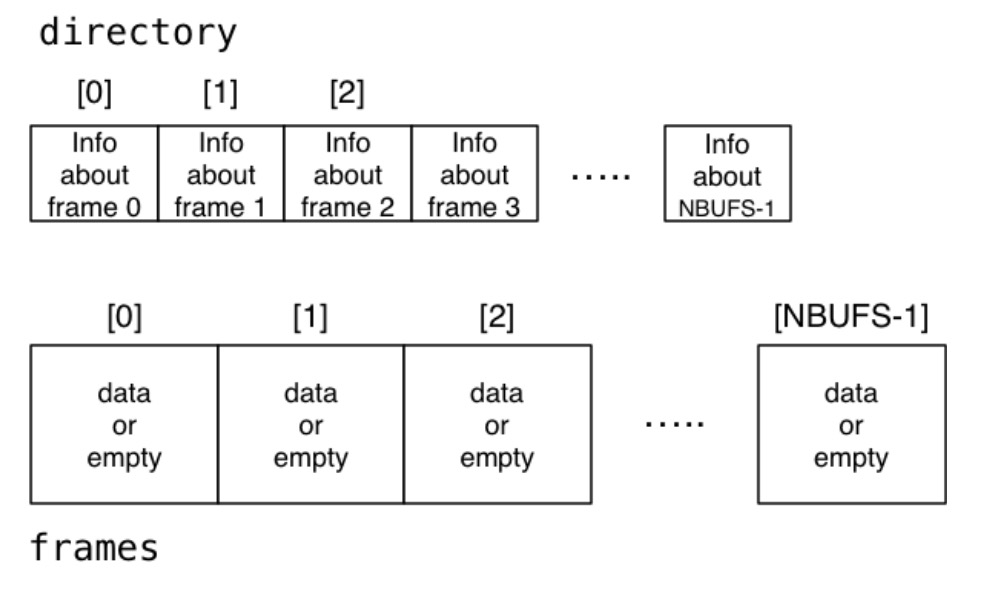
对于每个 frame(FrameData)都需要知道:
- 哪些页是有数据的,哪些页是空的
- 自加载以来是否已修改(脏位)
- 目前有多少笔交易正在使用它(别针数)
- 最近访问的时间戳(用于页面替换时使用)
页面由 PageID 引用,PageID = BufferTag = (rnode, forkNum, blockNum)。
在没有缓冲池的情况下进行扫描
Buffer buf;
int N = numberOfBlocks(Rel); // 获取关系Rel中的块数目
for (i = 0; i < N; i++) { // 遍历关系中的每个块
pageID = makePageID(db,Rel,i); // 创建一个BufferTag结构体,用于标识要读取的块
getBlock(pageID, buf); // 根据给定的pageID读取块的内容,并将内容存储在缓冲区buf中
for (j = 0; j < nTuples(buf); j++) // 遍历缓冲区中的每个元组
process(buf, j)
}
- 需要读 N 个页面
- 如果需要再读一次,则又要读 N 个页面
在有缓冲池的情况下进行扫描
Buffer buf;
int N = numberOfBlocks(Rel);
for (i = 0; i < N; i++) {
pageID = makePageID(db,Rel,i);
bufID = request_page(pageID); // 从缓冲池中获取指定页的缓冲区ID
buf = frames[bufID]; // // 获取缓冲区中的数据
for (j = 0; j < nTuples(buf); j++)
process(buf, j)
release_page(pageID); // // 释放使用的页,将缓冲区标记为可用状态
}
- 第一次需要读 N 个页面
- 之后如果需要读,读的页面将少于 N 个页面
request_page()
int request_page(PageID pid)
{
if (pid in Pool) // 页面已存在于缓冲池中
bufID = index for pid in Pool // 直接获取该页面对应的缓冲区ID
else {
if (no free frames in Pool) // 缓冲池中没有可用的空闲帧
evict a page (free a frame) // 需要选择一个页面进行替换(驱逐)
bufID = allocate free frame // 分配一个空闲帧给新页面
// 在目录中记录分配的帧的信息
directory[bufID].page = pid
directory[bufID].pin_count = 0
directory[bufID].dirty_bit = 0
}
directory[bufID].pin_count++ // 增加页面的引用计数
return bufID
}
页面替换
- 找到适合替换的帧,这个帧需要满足:
pin count = 0dirty bit = 0
- 如果选定的帧被修改,则将帧刷新到磁盘
- 将目录条目标记为“空帧”
- 如果满足条件的帧有多个,就需要使用页面替换策略(Least Recently Used (LRU)、Most Recently Used (MRU)、First in First Out (FIFO)、Random)
缓冲管理的效率
考虑一个查询,以找到同时也是员工的客户:
select c.name
from Customer c, Employee e
where c.ssn = e.ssn;
这可以通过嵌套循环在数据库管理系统中实现:
for each tuple t1 in Customer {
for each tuple t2 in Employee {
if (t1.ssn == t2.ssn)
append (t1.name) to result set
}
}
在页面级操作来看,该算法如下:
Rel rC = openRelation(”Customer”);
Rel rE = openRelation(”Employee”);
for (int i = 0; i < nPages(rC); i++) {
PageID pid1 = makePageID(db,rC,i); // 获取关系Customer的第i个页面的PageID
Page p1 = request_page(pid1); // 获取具体的页面内容
for (int j = 0; j < nPages(rE); j++) {
PageID pid2 = makePageID(db,rE,j);
Page p2 = request_page(pid2);
// compare all pairs of tuples from p1,p2
// construct solution set from matching pairs
release_page(pid2);
}
release_page(pid1);
}
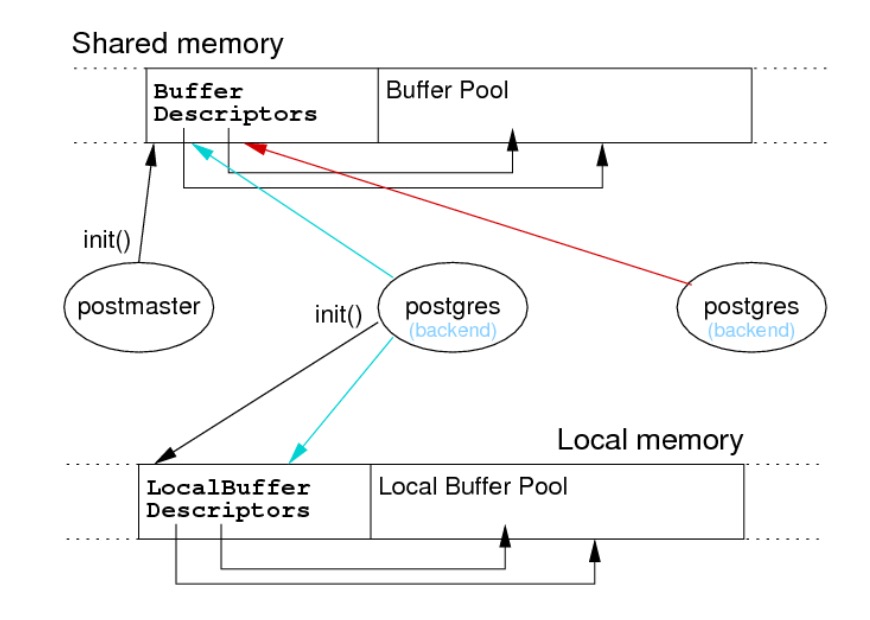
PostgreSQL 缓冲区管理器为所有后端提供共享的内存缓冲区池,所有访问方法都通过缓冲区管理器从磁盘获取数据。缓冲区位于一个大的共享内存区域。
定义:src/include/storage/buf*.h
include/storage/buf.h:基本缓冲管理器数据类型(例如 Buffer)include/storage/bufmgr.h:缓冲区管理器函数接口的定义include/storage/buf_internals.h:缓冲区管理器内部的定义(例如 BufferDesc)
函数:src/backend/storage/buffer/*.c
缓冲池的构成:
BufferDescriptors:BufferDesc的共享固定数组(大小为NBuffers)BufferBlocks:帧(8KB 大小)的共享固定数组(大小为NBuffers)Buffer:上述数组中的索引值
缓冲池的大小在 postgresql.conf 中设置:
shared_buffers = 16MB # min 128KB, 16*8KB buffers

 浙公网安备 33010602011771号
浙公网安备 33010602011771号