数据库内核:PostgreSQL 架构
PostgreSQL 的架构
客户端/服务器架构:
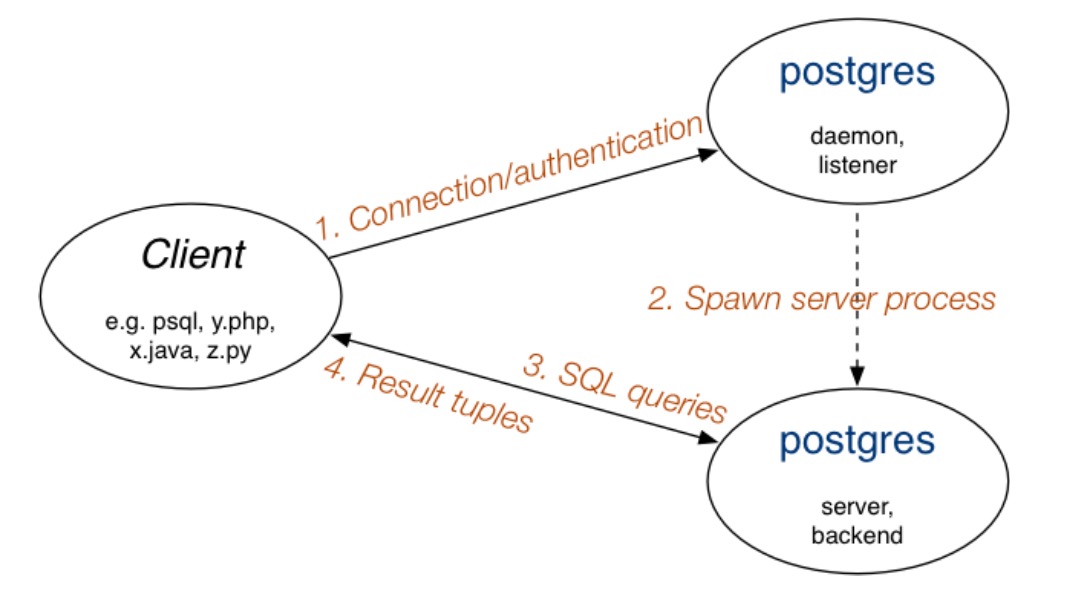
- Postmaster (Daemon) Process(主后台驻留进程):PostgreSQL 启动时第一个启动的进程,他会执行恢复、初始化共享内存的运行后台进程操作。当有客户端发起链接请求时,它还负责创建后端进程。是整个数据库实例的总控进程,负责启动和关闭该数据库实例。
- Background Process(后台进程):PgArch 进程(归档)、PgStat 进程(统计数据收集)、AutoVacuum 进程(自动清理)、BgWriter 进程(后台)、Wal Writer 进程(预写式日志)、CheckPoint进程(检查点)、Syslogger 进程(系统日志)
- Backend Process(后端进程):Postmaster 进程会派生一个子进程用来处理用户连接。
- Client Process(客户端进程):客户端进程需要和后端进程配合使用,处理每一个客户连接。
执行流程
大致流程:首先,客户端进程会向 Postmaster 进程发送连接请求,Postmaster 进程接收到之后会生成一个后端进程来处理请求。客户端进程与后端进程建立连接之后,客户端进程向后端进程发送 SQL 查询,后端进程执行 SQL 返回查询结果。
注意点:
- Postmaster 进程只有一个,客户端进程和后端进程可以有很多个,一个客户端进程对应一个后端进程。
- 客户端进程和后端进程通过 TCP/IP 或 Unix 套接字进行通信。
- 使用 PostgreSQL 特定的前端/后端协议,客户端、服务器分离有利于安全性和可靠性。
- 客户端、服务器连接开销很大,通常是通过持久连接的客户端池来解决。
- 所有后端进程(服务器)都通过缓冲池访问数据库文件。因此,所有服务器都能获得一致的数据视图是很重要的。
- 使用共享内存会限制分布式和可扩展性,因为所有后端进程(服务器)必须在同一台机器上 。
- 共享表是“全局”系统目录表(为整个 PostgreSQL 安装保留用户/组/数据库信息)。
内存/存储架构
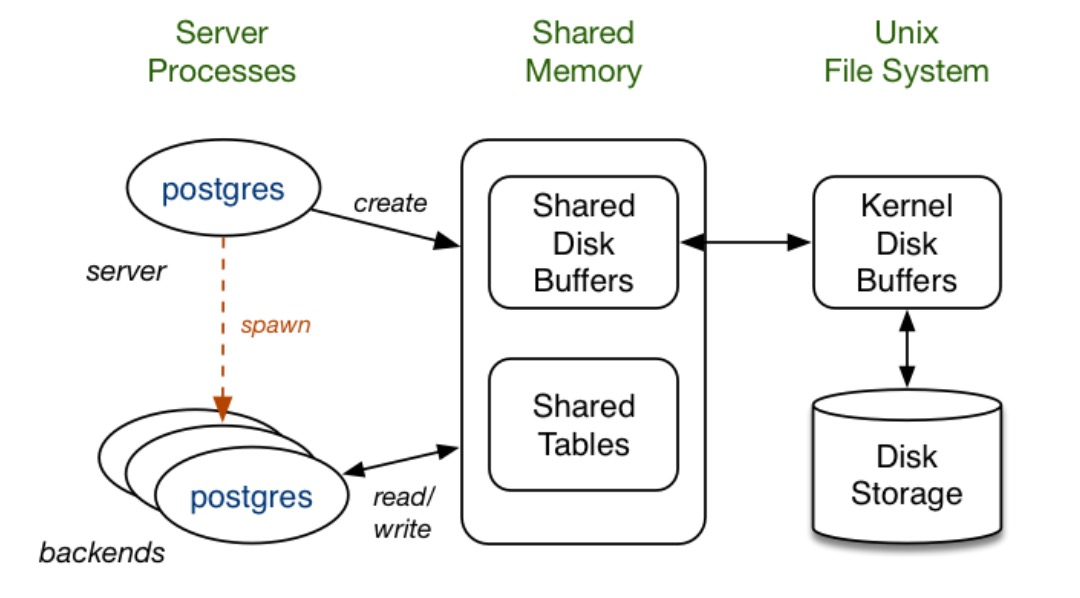
PostgreSQL 启动后,会生成一块共享内存,共享内存主要做数据块的缓冲区,以便提高读写性能,WAL 日志缓冲区和 CLOG 缓冲区也存在于共享内存中。除此之外,一些全局信息也保存在共享内存中,如进程信息、锁信息、全局统计信息等。
文件系统架构
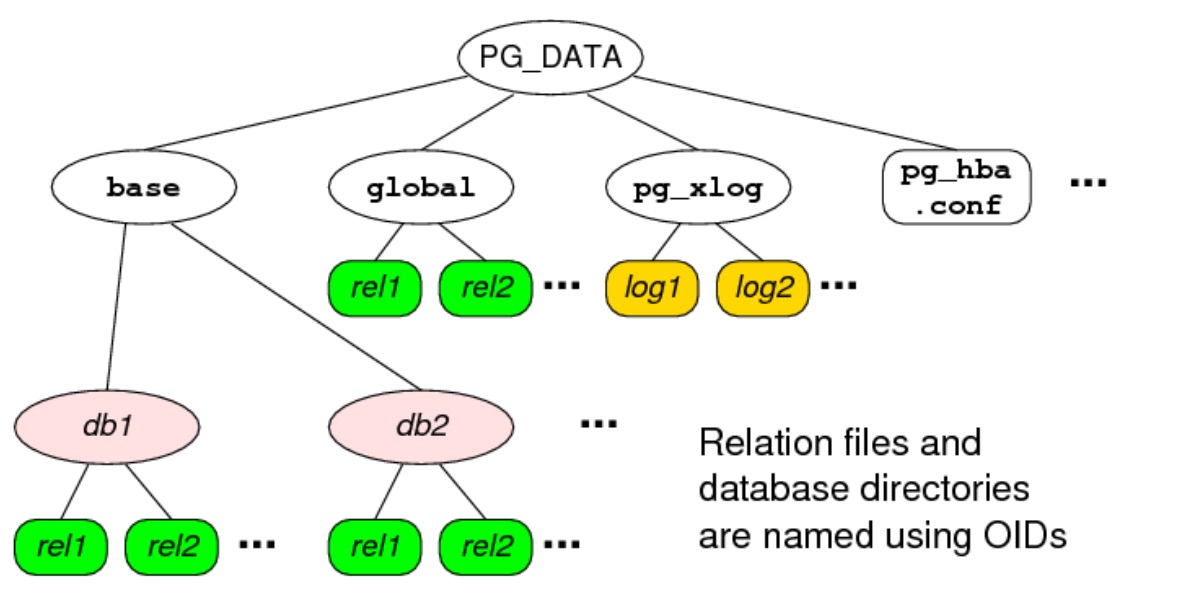
PostgreSQL 使用 OIDs 作为每个数据库目录和每张表文件的名称。使用 pg_catalog 这张表去找数据库的目录、Pizzas 和 People 两张表的数据文件。
$PGDATA目录下关键文件
PG_VERSION:一个包含 PostgreSQL 主版本号的文件postgresql.conf:配置参数postmaster.opts:记录服务器最后一次启动时使用的命令行参数的文件postmaster.pid:锁文件,记录着当前的 postmaster 进程ID(PID)、集簇数据目录路径、postmaster 启动时间戳、端口号、Unix域套接字目录路径、第一个可用的 listen_address(IP地址或者*,或者为空表示不在TCP上监听)以及共享内存段ID(服务器关闭后该文件不存在)。
PostgreSQL 源代码
- README:简单说明
- INSTALL:安装方法简要说明
config/*:构建本地化 Makefiles 的脚本- Makefile:Makefile模版,控制系统构建的顶级脚本
src/*:源代码目录include:具有全局定义的*.h文件(常量,类型等等)backend:PostgreSQL 服务器(后端)的代码bin:客户端代码(例如 psql,pg_ctl,pg_dump 等等)pl:存储过程语言解释器(例如 plpgsql)interfaces:低级 C 语言接口的代码(例如 libpq)
doc/*:常见问题解答和文档(各种格式)contrib/*:分布式扩展的源代码
PostgreSQL 的查询
典型的数据库管理系统的查询路径
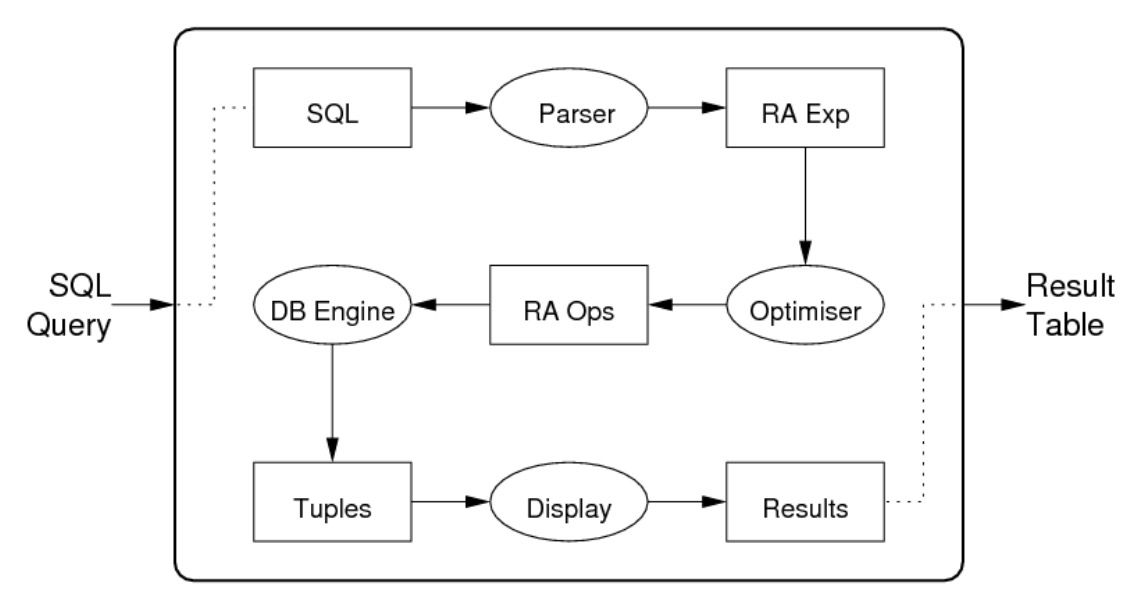
- 客户端给服务器发送 SQL 查询请求。服务器得到一串 SQL 字符串,调用由 lex 和 yacc 编写的查询编译模块,将 SQL 字符串解析成内部的数据结构 —— ParseTree 构成的链表(解析树)。
- 分析阶段(Parser):检查 SQL 里是否由不符合语义规定的部分(例如查询的表是否存在等等),该阶段将解析树作为输入,然后输出 Query 链表(查询树)。
- 查询重写:查找可以应用到查询树中的任何规则(存储在系统目录中),对找到的规则,它会根据规则对查询树进行重写。
- 查询优化(Optimiser):根据重写后的查询树创建一个将被作为执行器输入的查询计划(计划树)。它会先创建所有可能导向相同结果的路径。估算每条路径的代价,选择最小的路径将其扩展为完整的计划供给执行器使用。
- 执行器递归地逐步通过计划树并按照计划表述的方式获取行。执行器在扫描关系时会使用存储系统、执行排序和连接、估算条件并最后归还得到的行。
PostgreSQL 的数据类型
数据类型的定义在 src/include/ 的头文件中。有两个重要的数据类型:Node 和 List。
- Node:为节点提供通用结构
src/include/nodes/nodes.h- 具体的节点定义在
src/include/nodes/*.h - 与节点相关的函数定义在
src/backend/nodes/*.c - 节点类型有解析树,计划树,执行树等等
- List:提供通用的单链接列表
src/include/nodes/pg_list.h- 与列表相关的函数定义在
src/backend/nodes/list.c
PostgreSQL 的查询评估
exec_simple_query(const char *query_string)
src/backend/tcop/postgres.c- 评估 SQL 查询的入口点
- 假设
query_string是一个或多个 SQL 语句,执行大量的初始化操作 - 解析 SQL 字符串到一个或多个解析树中
- 对于每个解析的查询,执行基于规则的重写,制定评估计划(优化),执行计划,向客户端发送元组
pg_parse_query(char *sqlStatements)
src/backend/tcop/postgres.c- 返回解析树列表,每个 SQL 语句对应一个
pg_analyze_and_rewrite(Node *parsetree, ...)
src/backend/tcop/postgres.c- 将解析后的查询转换为适合计划的形式
每个查询都由
Query结构表示
src/include/nodes/parsenodes.h- 包含 SQL 查询的所有组件
- 作为 TargetEntry 列表的必需列
- 作为 RangeTblEntry 列表的引用表
- 在 FromExpr 结构中作为节点的 WHERE 子句
- 将排序要求表示为 SortGroupClause 结构的列表
- 查询可能是嵌套的,因此会形成树状结构
pg_plan_queries(querytree_list, ...)
src/backend/tcop/postgres.c- 将分析的查询转换为可执行的“语句”
- 使用
pg_plan_query()函数去对每个 Query 进行计划,函数在src/backend/tcop/postgres.c planner()是实际在做计划的函数,函数在optimizer/plan/planner.c
每个可执行的查询都由
PlannedStmt节点表示
src/include/nodes/plannodes.h- 包含用于执行查询的信息,例如涉及哪些关系表,输出元组的结构等
- 最重要的组件是计划节点的树,每个计划节点代表一个关系操作(SeqScan,IndexScan,HashJoin,Sort等等),每个计划节点还包含执行的成本估算
PlannedStmt *planner(Query *parse, ...)
optimizer/plan/planner.csubquery_planner()函数用于执行标准转换,例如将选择(Selection)和投影(Projection)下推至树的底部- 然后调用基于成本的优化器
- 选择可能的计划(操作执行令)
- 为这个计划选择物理操作
- 估算此计划的成本(使用DB统计数据)
- 选择成本最小的计划
查询运行在
Portal环境中
src/include/utils/portal.h- 该环境包含计划声明(计划节点的树)、计划节点的运行时版本(在
QueryDesc下)、结果元组的描述(在TupleDesc下)、通过结果元组扫描的总体状态、其他上下文信息(交易、内存等等)
查询评估的流程
exec_simple_query()
- 解析、重写和计划得到
PlannedStmt - 对每一个
PlannedStmt都创建Portal结构,然后将PlannedStmt插入到Portal中 - 设置
CommandDest来接收结果,然后调用PortalRun()函数,PortalRun()函数又会调用ProcessQuery()函数,该函数会从计划中制作QueryDesc - 接着调用
ExecutorRun()函数,ExecutorRun()函数又会调用ExecutePlan()来生成结果
PostgreSQL 的目录
数据库管理系统中需要考虑的关于关系的信息有
- 每个关系的名称、所有者、主键
- 每个属性的名称、数据类型、约束
- 对每个关系进行操作的权限
这些信息在 PostgreSQL 中都存在系统目录表(system catalog tables)中。
以下操作会对影响目录的内容
- 创建对象
create - 删除对象
drop - 修改对象
alter - 授权对象
grant
这里的对象可以是表、视图、函数、触发器、模式等等。
在 PostgreSQL 中用户是可以看到目录的
- 在 Psql shell 中执行特殊命令(例如
\d) - 或者使用 SQL 语句(例如
select * from information_schema.tables;) - 在
pg_catalog中可以看到全局模式 - 在
pg_tables中可以看到模式中的一组表格/视图
除了上面的 \d 命令以外,还有很多命令:
\d:给出所有表格和视图的列表\d Table:给出Table这张表的模式\df:提供用户定义的函数列表\df+ Function:给出Function这个函数的细节\ef Function:允许你对Function这个函数进行编辑\dv:提供用户定义的视图列表\d+ View:给出View这个视图的定义
全局目录信息和本地目录信息
PostgreSQL安装(集群)通常有许多数据库,一些目录信息是全局的,例如:
- 目录表定义:数据库、用户等等
- 整个 PostgreSQL 安装的每个此类表的副本
- 所有集群共享的数据库(在
PGDATA/pg_global中)
其他目录信息是每个数据库的本地信息,不是全局的,例如:
- 模式、表、属性、函数、类型等等
- 每个数据库中每个“本地”表的单独副本
- 在数据库创建时制作了许多“全局”表的副本
PostgreSQL 中元组包含的信息
- 创建表时定义的属性
- 系统定义的属性:
oid:元组的唯一识别号(可选)tableoid:表示这个元组属于哪个表xmin/xmax:表示哪个事务创建/删除了元组(对于MVCC)
OID 在许多目录表中用作主键。
数据库的表示
在单个数据库模式的级别之上:
databases由pg_database表示,包含有关数据库的信息schemas由pg_namespace表示,包含有关模式的信息table spaces由pg_tablespace表示,包含有关表空间的信息
表的表示
表示一张表需要使用几个在目录表中的元组。由于存在对象继承,表的基本表被称为 pg_class。pg_class 表还处理其他“类似表”的对象:
- 视图:表示视图的属性/域
- 复合(元组)类型:来自
CREATE TYPE AS - 序列、索引、其他“特殊”对象
pg_class 中的所有元组都有一个 OID,用作主键。
数据库引擎操作
数据库引擎(DB engine)就是“关系代数虚拟机”(relational algebra virtual machine)。
关系代数(RA,Relational Algebra)可以看作是操纵关系的数学系统或者是关系模型中对数据进行操作的语言(DML,Data Manipulation Language)。
- \(\sigma\):选择(selection)
- \(\pi\):投影(projection)
- \(\Join\):连接(join)
- \(\cup\):并集(union)
- \(\cap\):交集(intersection)
- \(-\):差集(difference)
- 排序(sort)
- 分组(group)
- 聚合(aggregate)
Selection
- \(\sigma_C(r)=Sel[C](r)=\left\{t|t\in r\wedge C(t)\right\}\)
- \(C\) 是一个 boolean 函数,选择条件。
result = {}
for each tuple t in relation r
if (C(t)) { result = result + {t} }
Projection
- \(\pi_X(r)=Proj[X](r)=\left\{t[X]|t\in r\right\}\)
- \(X\in R\),结果的模式(属性)由 \(X\) 中的属性决定。
result = {}
for each tuple t in relation r
result = result + {t[X]}
Union
- \(r_1\cup r_2=\left\{t|t\in r_1\vee t\in r_2\right\}\)
- \(r_1,r_2\) 是两个模式相同的关系。
result = r1
for each tuple t in relation r2
result = result + {t}
Intersection
- \(r_1\cap r_2=\left\{t|t\in r_1\wedge t\in r_2\right\}\)
- \(r_1,r_2\) 是两个模式相同的关系。
result = {}
for each tuple t in relation r1
if(t in r2){result = result + {t}}
Difference
- \(r_1- r_2=\left\{t|t\in r_1\wedge t\notin r_2\right\}\)
- \(r_1,r_2\) 是两个模式相同的关系。
result = {}
for each tuple t in relation r1
if(t not in r2){result =result + {t}}
Inner Join
- \(r\Join_Cs=Join[C](r,s)=\left\{(t_1:t_2)|t_1\in r\wedge t_2\in s\wedge C(t_1:t_2)\right\}\)
- \(C\) 是连接条件,\(r,s\) 是两个可以连接的关系。
result = {}
for each tuple t1 in relation r
for each tuple t2 in relation s
if (matches(t1 ,t2 ,C))
result = result + {concat(t1,t2)}
Left Outer Join
- \(Join_{LO}[C](r,s)\) 包含关系 \(r\) 中所有的元组,即使没有匹配上。
result = {}
for each tuple t1 in relation r
nmatches = 0
for each tuple t2 in relation s
if (matches(t1 ,t2 ,C))
result = result + {concat(t1,t2)}
nmatches++
if (nmatches == 0)
result = result + {combine(t1 ,null)}
练习题
关系 student、course、enrolment 的模式如下所示:
Students(sid, name, degree, ...)
Courses(cid, code, term, title, ...)
Enrolments(sid, cid, mark, grade)
编写关系代数表达式来解决以下问题:
- 找出在2018年第2学期(18s2)中通过了"COMP9315"课程的所有学生
- 对于每个学生,给出学生证、姓名、分数
解:
- \((\sigma_{code=COMP9315,term=18s2}(Courses))\Join_{Courses.cid=Enrolments.cid}(\sigma_{grade>=60}(Enrolments))\Join_{Enrolments.sid=Students.sid}(Students)\)
- \(\pi_{sid,name,mark}((Courses))\Join_{Courses.cid=Enrolments.cid}(Enrolments)\Join_{Enrolments.sid=Students.sid}(Students))\)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号