TF-IDF定义及实现
TF-IDF定义及实现
定义
TF-IDF的英文全称是:Term Frequency - Inverse Document Frequency,中文名称词频-逆文档频率,常用于文本挖掘,资讯检索等应用,在nlp以及推荐等领域都是一个常用的指标,用于衡量字词的重要性。比较直观的解释是,如果一个词本来出现的频率就很高,如the,那么它就几乎无法带给读者一些明确的信息。一般地,以TF-IDF衡量字词重要性时,某个字词在某个文档中出现的频率越高,那么该字词对该文档就有越大的重要性,它可能会是文章的关键词;但若字词在词库中出现的频率越高,那么字词的重要性越低,如the。
计算公式
\[TF-IDF = TF * IDF
\]
TF-IDF即是两者相乘,词频乘以逆文档频率。
\[TF_{ij} = \frac{n_{ij}}{n_{*j}}
\]
下标i,j的含义:编号为j的文档中的词语i在该文档中的词频,即所占比例,n为该词语的数量。
\[IDF_i = log(\frac{N+1}{N_i+1})
\]
N是文档总数,$ N_i $ 表示文档集中包含了词语i的文档数。对分子分母加一是为了避免某些词语未在文档中出现过导致的分母为零的情况。IDF针对某个词计算了它的逆文档频率,即包含该词语的文档比例的倒数(再取对数),若IDF值越小,分母越大,说明这个词语在文档集中比较常见不具有鲜明的信息代表性,TF-IDF的值就小。总之TF-IDF的值我们通常希望它越大越好,大值代表性强。
实现
1. 数据定义预处理
import numpy as np
import pandas as pd
doc1 = "The cat sat on my bed"
doc2 = "The dog sat on my keens"
#构建词库
wordSet = set(doc1.split()).union(set(doc2.split()))#union是并集操作
wordSet

2. 统计词频
dict1 = dict.fromkeys(wordSet, 0)
dict2 = dict.fromkeys(wordSet, 0)
for word in doc1.split():
dict1[word]+=1
for word in doc2.split():
dict2[word]+=1
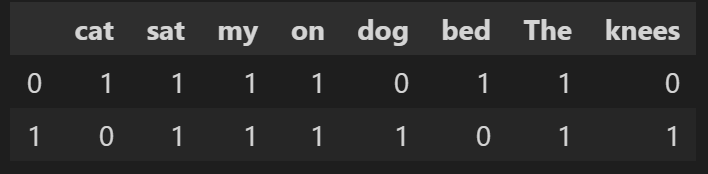
pd.DataFrame([wordDictA, wordDictB])
3. 计算词频 TF,对单个文档统计
def computeTF(wordDict, doc):
sumCount = len(doc.split())
tfDict = dict()
for word, count in wordDict:
dict[word] = count / sumCount
return tfDict
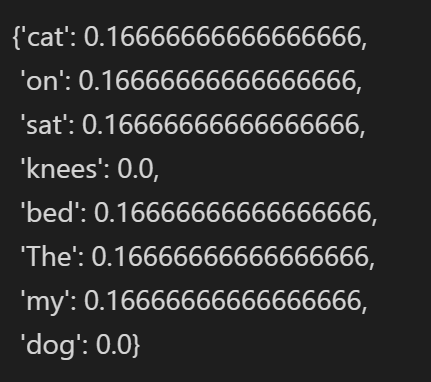
tf1 = computeTF(dict1, doc1)
tf2 = computeTF(dict2, doc2)
4.逆文档频率IDF, 全局只有一份逆文档频率,对所有文档统计
def computeIDF(dicts, wordSet):
"""传入的是文档的字典集和词库,即全部文档"""
docNum = len(docs) #文档总数
#对每个词语查看有几个文档包含它
IDFDict = dict.fromkeys(wordSet, 0)
for word in wordSet:
for _dict in dicts:
IDFDict[word] += (_dict[word] > 0)#该文档中有这个词就加1
for word, idf in IDFDict:
IDFDict[word] = math.log10((docNum + 1) / (IDFDict[word] + 1))
return IDFDict
IDF = computeIDF([dict1, dict2], wordSet)
IDF
5.最终计算
def computeTFIDF( tf, idfs ):
tfidf = {}
for word, tfval in tf.items():
tfidf[word] = tfval * idfs[word]
return tfidf
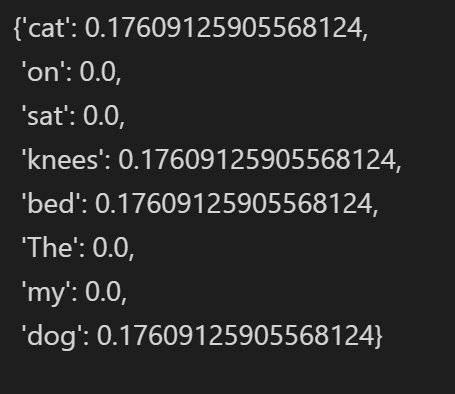
tfidf1 = computeTFIDF( tf1, idf )
tfidf2 = computeTFIDF( tf2, idf )

可以看到由于单词The,dog,my,on,set在两个文档中都存在故TF-IDF值为0,而其他单词因为具有一定的分辨能力,所以TF-IDF有一定的数值可以用来分辨两句话。
以上内容参考自视频B站,点击即可前往。
石中之火,即使无可燃烧之物,也要尽力发亮

 浙公网安备 33010602011771号
浙公网安备 33010602011771号