条件随机场
判别式模型:拿到的是条件概率,在给定特征X情况下求Y得概率,找到最大的Y作为结果,不关注Y的分布。比如神经网络,你把X灌进去就能拿到结果。仅仅对输入抽取特征,即特征函数为f(x)。
产生式模型:是一种联合分布,用联合分布生成样本,比如HMM,BNS,MRF,对输入输出同时抽取特征,即特征函数为f(x,y)
相关的库:CRF++ 是传统方法里面比较好的方法,但是到现阶段大家会尝试用一些新的方法解决。
解决前后之间关联问题。考虑关联关系的模型。
比如用条件随机场来做句子词性标注。正如分类器所做,我们首先要设定一组特征方程f1。
CRF的特征函数
在CRF中每个特征函数以下列信息作为输入:
一个句子s
词在句子中的位置i
当前词的标签Li
前一个词的标签Li-1
f(s, i, Li, Li-1)输出的是一个实数值。例如某个特征函数就可以用来衡量当上一个词是“very”时,当前词有多少程度可以被标为一个形容词。
只包含Li和Li-1实际上是建立了一种特殊的线性CRF,没有考虑全局的信息。
从特征到概率
我们为每个特征函数fi设置一个权重值λj。给定一个句子S,现在我们可以通过累加句子中所有词加权后的特征来为S的打标结果I打分。(有一个句子,然后我给出了标注序列L,我去判断我这个标注给的好不好打个分)其中,j有m个取值可以理解为,有不同的方式抽取特征,每个f设定一个λ。

最终,我们通求指数与归一的方式转换这些得分转换为0、1之间的概率值:看起来会有点眼熟,这是因为实际上CRF就是序列版本的逻辑回归,正如逻辑回归是分类问题的对数线性模型,CRF是序列标注问题的对数线性模型。
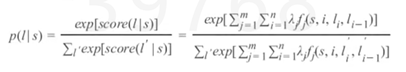
CRF使用任意的特征函数组用于得到标注得分,HMM采用生成方式进行标注,定义如下,P(Li|Li-1)为转移概率(一个介词后面紧跟着一个名词的概率),P(wi|Li)为发射概率(当已知是名词,会出现“dad”的概率):
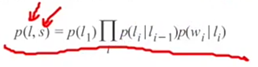
那么HMM和CRF比较会如何?CRF更强大,CRF可以为任何HMM能够建模的事务建模。

权重学习
上面那个概率函数实际上是类似于目标函数,因此我们学习权重一种方式是梯度上升。
假设我们有一组训练样本(包括句子与相关的词性标注标签结果),一开始,为我们的CRF模型随机初始化权重值,为了使这些随机初始的权重值最终调整为正确的值,遍历每个训练样本,执行如下操作:第一步求出梯度,然后迭代直到达到某种停止条件(更新值已经低于某个阈值),能达到什么效果取决你的特征函数。

应用,比如想知道twitter上哪些词代表理论,这时候可以利用条件随机场,例如我们设定如果上一个词是一个GIFT-RECIBER且它的前一个词是‘gave’,那么f1=1,这是一个特征函数,还可以设定另一个是,如果后面紧跟着的两个词是‘for christmas’那么f2=1,这又是另一个特征函数。

应用:中文命名实体识别
在中文信息处理领域,命名实体识别是各种自然语言处理技术的重要基础
命名实体:人名、地名、组织名
怎样想办法构造一些特征函数

人名左右的指界词要自己生成

如下可以看到,这个特征函数一点也不高级,就是在做一些feature engineering的工作


 浙公网安备 33010602011771号
浙公网安备 33010602011771号