词向量与相关应用
一、基础知识
计算机没有人类的先验知识,如何理解文字,如何让实现文本分类,必须找到一套方法或方式对这些我们人类造成的词去表达和表式。一是从大量的预料中,拿到一些可以对它的含义表达的一些表达方式,二是文本是标记性的语言没办法去做机器学习,转成计算机可以理解的数值型的向量。
词编码---> N-gram, TFIDF--->word2vec
Nlp常见问题:自动摘要、指代消解、机器翻译、词性标注、分词(中文、日文等)、主题识别、文本分类。
传统:基于规则
现代:基于统计机器学习 HMM, CRF, SVM, LDA, CNN….”规则“隐含在模型参数里
词编码
词编码需要保证词的相似性,如果每个词都给一个码就不能保证识别子类、近义词等,比如青蛙和蟾蜍等等
我们希望编码方式可以表达同样含义的词在向量空间里面分布相似,例如下面假设的二维空间。
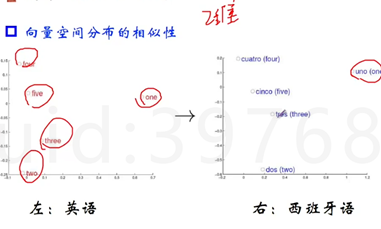
向量空间子结构
每个词一定是空间中的某个点,期望词向量能捕捉到词和词之间的相对关系
VKing – Vqueen +Vwomen = Vman
VParis – VFrance +VGerman = VBerlin
最终目标,词向量表示作为机器学习、特别是深度学习的输入和表示空间
英语里面自然语言处理的库NLTK,他会建立很大一个字典,根据专家构建出来的权威的东西,比如猫,是一个动物,有胎生,弹跳性等上位词。但是会有很多问题,不能分辨细节的差别、需要大量人为劳动、主管、无法发现新词、难以精确计算词之间的相似度

二、离散表示
离散表示:one-hot表示
很早之前的词编码的方式,建索引,one-hot,每个单词都有唯一索引,在词典中的顺序和在句子中的顺序没有关联。先建索引,再one-hot表示。
这种方式非常吃空间,维度非常非常高,如果每个词给一个编码,会做一个高频统计,只表示3000或4000个高频词,其他的词都用一个维度表示。

离散表示:bag of words
刚刚方式可以表达词,但最终目标是表达文本。文档的向量表示可以直接将各词的词向量表示加和。对应维度下面填充数字,表示这个数字出现了多少次。
![]()
from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() #四段语料 corpus = ["i come to China to travel", “This is a car popular in china”, "i love tea and apple", "the work is to write some papers in science"] print vectorizer.fit_transform(corpus)
print vectorizer.fit_transform(corpus).toarray()
print vectorizer.get_feature_names()
离散表示:TF-IDF
在搜索引擎中,常用到词权重,从而引申出TF-IDF。

1 # 读入文本 2 with open('./nlp_text1.txt') as f3: 3 res1 = f3.read() 4 5 with open('./nlp_text3.txt') as f4: 6 res2 = f4.read() 7 8 #停用词 9 #从文件导入停用词表 10 stpwrdpath = "stop_words.txt" 11 stpwrd_dic = open(stpwrdpath, 'rb') 12 stpwrd_content = stpwrd_dic.read() 13 #将停用词表转换为list 14 stpwrdlst = stpwrd_content.splitlines() 15 stpwrd_dic.close() 16 17 # 向量化,TF-IDF和标准化 当然,还可以处理停用词 18 from sklearn.feature_extraction.text import TfidfVectorizer 19 corpus = [res1,res2] 20 vector = TfidfVectorizer(stop_words=stpwrdlst) 21 tfidf = vector.fit_transform(corpus) 22 print tfidf 23 24 wordlist = vector.get_feature_names()#获取词袋模型中的所有词 25 # tf-idf矩阵 元素a[i][j]表示j词在i类文本中的tf-idf权重 26 weightlist = tfidf.toarray() 27 #打印每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重 28 for i in range(len(weightlist)): 29 print "-------第",i,"段文本的词语tf-idf权重------" 30 for j in range(len(wordlist)): 31 print wordlist[j],weightlist[i][j]
离散表示:语言模型 Bi-gram和N-gram
上面两个表示方式都没有考虑词的顺序。Bi-gram和N-gram考虑了词的顺序,但是缺点是词表膨胀。

离散表示的问题:
无法衡量词向量之间的关系(没有捕获文本的含义);词表维度随着语料库增长膨胀;n-gram词序列随语料库膨胀更快;数据稀疏问题。
对于词袋模型的稀疏问题可以用常用的文本降维方法是Hash Trick。在Hash Trick中,首先定义一个Hash后对应的哈希表,这个哈希表的维度会远远小于词汇表的特征维度,因此可以看成是降维。具体的方法是,对任意一个特征,使用用Hash函数找到对应哈希表的位置,然后将该特征对应的词频统计值累加到该哈希表位置。在scikit-learn的HashingVectorizer类中,实现了基于signed hash trick的算法。
from sklearn.feature_extraction.text import HashingVectorizer vectorizer2 = HashingVectorizer(n_features=6,norm=None) print vectorizer2 .fit_transform(corpus)
三、分布式连续表示
分布式表示(Distributed representation)

1957年firth提出,用一个词附近的其他词来表示该词,这被认为是现代统计自然语言处理中最有创见的想法之一。计算机可以看很多语料,比如发现banking经常和经济这类词放到一起,基于这种思路,就有很多人提出了不同的解决思路。
共现矩阵(Cocurrence matrix)
即两个词同时出现。Word-Document的共现矩阵主要用于发现主题,用于主题模型,如LSA(latent semantic analysis)
这时候就有一个局域窗的概念,就是在一个范围内看共现的单词。局域窗中的word-word共现矩阵可以挖掘语法和语义信息。
Window length设为1(一般设为5-10)
使用对窗函数(左右window length都为1)
将共现矩阵行作为词向量。
下图为这三句话的共现矩阵,假设左右窗口为1,i旁边左右窗口中like出现2次,enjoy出现1次。这时候的向量表示用的是共现矩阵的方式。
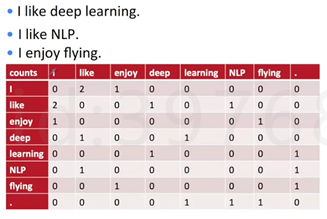
优势:能表示出来词的相关度。把周边朋友拿过来了,上下文捕捉到了
缺点:向量维数随着词典大小线性增长;存储整个词典的空间消耗非常大;一些模型如文本分类模型会面临稀疏性问题;模型会欠稳定(加了新的句子,统计的频率就不一样)。
解决上面维度的缺陷,最直接的想法是降维,用SVD对共现矩阵向量做降维,取 U矩阵里面的值。该想法依然有问题,计算量随语料库和词典增长膨胀太快,对X(m*n)维的矩阵,计算量o(n^3);难以为词典中新加入的词分配词向量。与其他深度学习模型框架差异大(已经再原始数据上处理了,可能不是deeplearnning想要的输入方式)。
Import numpy as np
la = np.linalg
x = np.array([
[0,2,1,0,0,0,0,0],
[2,0,0,1,0,0,0,0],
[1,0,0,1,,0,0,1,0]
])
U, S, Vh = la.svd(X, full_matrices=False)
四、WORD2VEC
NNLM(neural network language model)2003年提出word2vec前身
直接从语言模型出发,将模型最优化过程转化为求词向量表示的过程。前向窗函数,由N-1个词推断下一个词的概率,会遍历整个语料库。
使用了非对称的前向窗函数,窗长度为n-1,滑动窗口遍历整个语料库求和,![]()
与标准答案的相近度,希望越大越好。
要求概率P满足归一化条件,这样不同位置t处的概率才能相加,即:
![]()
对所有的词做一个稀疏的向量表示,前n-1个词去预测下一个词。 NNLM只有1个隐层。最后W假设是1*8000(对1个词的描述),假设最后的向量是个500维的,那C就是80000*500。先通过投影矩阵(先随机初始化)做投影,只是从W里面选出一行或者一列,然后到一个隐层,然后再到softmax,最后完成拼接。最后的维度,取决于你的n,如果你要用前10个词预测,那应该是10*500=5000维。输出层softmax,我们希望拿到的概率值尽量的高,可以加上一个负号然后用BP+SDG可以完成优化,一旦优化完了,投影矩阵也就是最好的稠密向量表示。
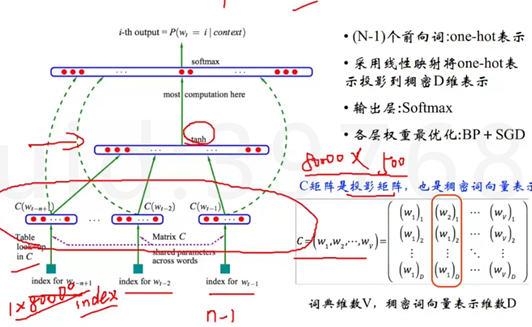
因为是神经网络,所以需要大量的数据,每个训练样本的复杂度为N*D+N*D*H+H*V,因此在这个基础上去做了简化。
Word2Vec实际上是两种不同的方法:Continuous Bag of Words (CBOW) 和 Skip-gram。
这两种方法都利用人工神经网络作为它们的分类算法。起初,每个单词都是一个随机 N 维向量。经过训练之后,该算法利用 CBOW 或者 Skip-gram 的方法获得了每个单词的最优向量。
Word2vec:CBOW(连续词袋)
Continue bag of words由周边的n个词,去推中间的1个词。
如何简化?
试试无隐层。
使用双向上下文窗口。
上下文词序无关。
输入层直接使用低维稠密表示。
投影层简化为求和(平均)
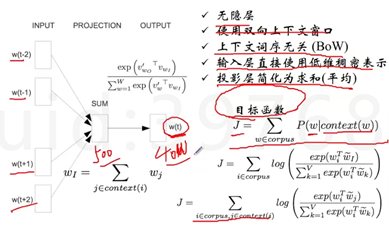
最后是一个softmax,类似于多分类的softmax,也需要去完成一个全连接的计算,拼接,如果词表是40W,500*40W你就需要有这样一个连接,消耗太大,所以要处理,有两种方式:
一种是层次softmax。40W词是平铺开来的,意思是和40w词都要有连接,对于平铺开来的结构如果要压缩空间是层叠起来的结构,使用huffman树对原本文本语料进行编码,根据出现频次的高低。边上的权重可以共享。根据语料在这个huffman树上找到路径(每个节点就是个二分类),求出这条路径上的概率相加,使其最大,就把刚刚平铺的变成了层叠的结构。

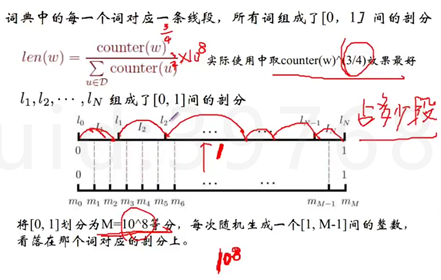
另一种是负例采样(工业上用的多一些)。由前后的词预测第t个词,可以将第t个词当成是正确的正样本,其他的作为负样本(40w-1),负样本的量太大了,所以我们可以去对这些负样本去采样。这个采样是要有技巧的,保证采样完的东西和原本的相近度很高。Google在做这个事情的时候想了个办法,拉出一个长度为1的小段,切成了10^8次方等分,然后按照词出现的词频的3/4划分占多少线段,在从空中抛色子,色子有10^8面,那个面朝上,查一查这个数落在哪一段,就把这一段的词取出来。之后就可以train一个softmax。
Word2vec:Skip-Gram(连续词袋)
上面是由周边的词推断中间的词,而Skip-Gram是中间的词推断周边的词,其他的和CBOW基本一致。语料非常大的话Skip-Gram的结果稍微比CBOW好一点

Word2vec存在的问题
对每个local context window单独训练,没有利用包含在global co-currence矩阵中的统计信息。改进方法:Glove
对多义词无法很好的表示和处理(比如苹果手机和苹果),因为使用了唯一的词向量。
Glove可以利用全局的信息,如果你需要一个对词表示的很好的词向量,可以试试Glove有开源的专门的库。但是深度学习里面还是用word2vec比较多,因为词嵌入这种方式你是可以可以作为嵌入层,直接做一个端到端的模型,嵌入的词表和目标直接关联的。
词嵌入效果评估:词类比任务。
词嵌入效果评估:词相似度任务。
词嵌入效果评估:作为特征用于CRF。


四、工具
1.Google word2vec
Git clone https://github.com/dav/word2vec
cd word2vec/src
Make
2.Python库
Genism
easy_install -U genism或pip install –upgrade
示例代码 https://www.zybuluo.com/hanxiaoyang/note/472184
word2vec作为此的初始输入,后面可以接各种各样的模型
word2vec + CNN尤其是建立成端到端的模型
电商情感分析 snownlp
参考博客
http://mp.weixin.qq.com/s?__biz=MzIxODM4MjA5MA==&mid=2247485748&idx=1&sn=daca1a059a51e3a2265a49c34faa3fe9&chksm=97ea2351a09daa4720c84c139751b1515c5447dac4d92741b9a7a3583a51aadbd758db013b26&scene=21#wechat_redirect

 浙公网安备 33010602011771号
浙公网安备 33010602011771号